
自9月1日起,美团正式发布了LongCat-Flash系列模型,并已开源LongCat-Flash-Chat和LongCat-Flash-Thinking两大版本,吸引了众多开发者的广泛关注。今日,LongCat-Flash系列迎来重大升级,全新成员LongCat-Flash-Omni正式发布。
LongCat-Flash-Omni在继承LongCat-Flash系列高效架构设计(基于Shortcut-Connected MoE,包含零计算专家)的基础上,创新性地集成了高效多模态感知模块和语音重建模块。即便在拥有5600亿总参数(激活参数为270亿)的庞大规模下,该模型仍能实现低延迟的实时音视频交互功能,为开发者在多模态应用场景中提供了更为高效的技术解决方案。

综合评估结果显示,LongCat-Flash-Omni在全模态基准测试中达到了开源领域的最先进水平(SOTA)。在文本理解、图像识别、视频解析以及语音感知与生成等关键单模态任务中,LongCat-Flash-Omni均展现出了卓越的竞争力。作为业界首个集“全模态覆盖、端到端架构、大参数量高效推理”于一体的开源大语言模型,LongCat-Flash-Omni首次在开源领域实现了与闭源模型的全模态能力对标。凭借其创新的架构设计和工程优化,该模型能够在多模态任务中实现毫秒级响应,有效解决了行业内大参数模型推理延迟的难题。

极致性能的一体化全模态架构
LongCat-Flash-Omni 是一款性能卓越的开源全模态模型,它在一个统一的框架内融合了离线多模态理解与实时音视频交互功能。该模型采用纯端到端的设计思路,以视觉和音频编码器作为多模态感知的核心组件,由 LLM 直接处理输入数据并生成文本及语音 token,随后通过轻量级音频解码器将其重建为自然语音波形,从而实现低延迟的实时交互体验。所有模块均基于高效的流式推理架构设计,其中视觉编码器和音频编解码器均为轻量级模块,参数量均约为 6 亿,延续了 LongCat-Flash 系列的创新性高效架构设计,实现了性能与推理效率之间的最佳平衡。

大规模、低延迟的音视频交互能力
LongCat-Flash-Omni 成功攻克了“大参数规模与低延迟交互难以兼得”这一技术难题,在大规模架构的基础上实现了高效的实时音视频交互。该模型拥有5600亿总参数(其中激活参数为270亿),凭借LongCat-Flash系列创新的ScMoE架构(包含零计算专家)作为LLM的核心支撑,并结合高效的多模态编解码器以及“分块式音视频特征交织机制”,最终实现了低延迟、高质量的音视频处理和流式语音生成。模型支持128K tokens的上下文窗口以及超过8分钟的音视频交互,在多模态长时记忆、多轮对话、时序推理等能力方面展现出显著优势。
渐进式早期多模融合训练策略
全模态模型训练的关键难点之一在于“不同模态的数据分布存在显著差异”,LongCat-Flash-Omni通过渐进式早期多模态融合训练策略,结合平衡数据策略和早期融合训练范式,逐步引入文本、音频、视频等模态数据,确保模型在全模态性能上表现出色且单模态性能不退化。
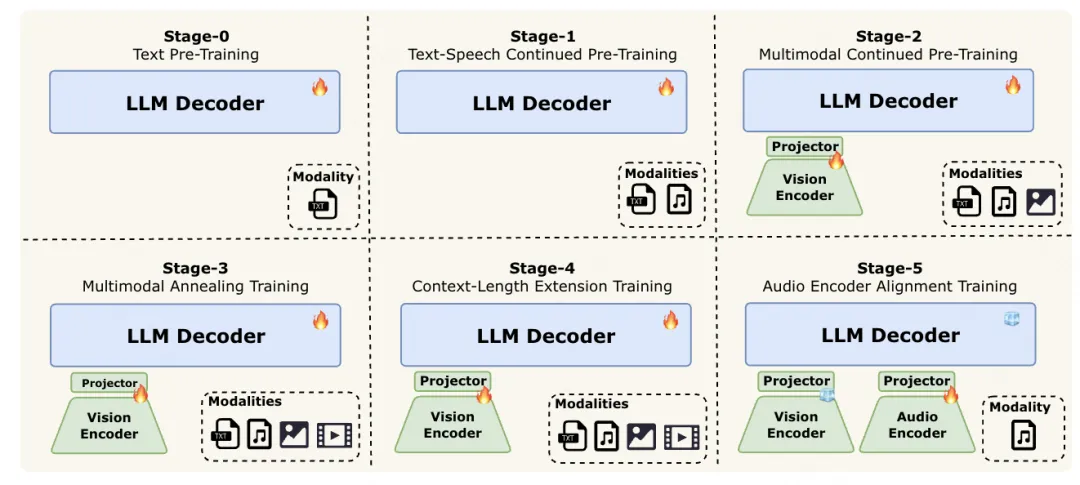
预训练阶段:
阶段 0:开展大规模文本预训练,借助成熟稳定的大语言模型为后续多模态学习筑牢根基。
阶段 1:引入与文本结构相似度较高的语音数据,实现声学表征与语言模型特征空间的对齐,有效整合副语言信息。
阶段 2:在文本 - 语音对齐的基础上,加入大规模图像 - 描述对以及视觉 - 语言交织语料,实现视觉 - 语言对齐,丰富模型的视觉知识储备。
阶段 3:引入最为复杂的视频数据,实现时空推理能力的提升,同时整合更高质量、更多样化的图像数据集,进一步增强模型的视觉理解能力。
阶段 4:将模型上下文窗口从8K扩展至128K tokens,以更好地支持长上下文推理和多轮交互。
阶段 5:为缓解离散语音tokens带来的信息丢失问题,开展音频编码器对齐训练,使模型能够直接处理连续音频特征,从而提升下游语音任务的保真度和稳健性。

经过全面的综合评估显示:LongCat-Flash-Omni 不仅在综合性的全模态基准测试(如Omni-Bench, WorldSense)上达到了开源最先进水平(SOTA),其在文本、图像、音频、视频等各项模态的能力均位居开源模型前列,真正实现了“全模态不降智”。
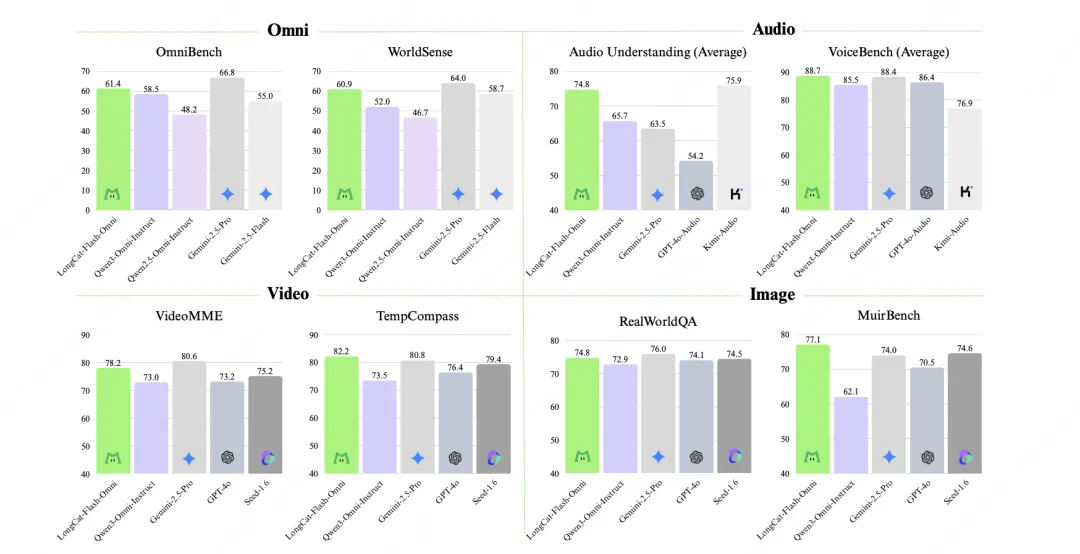
文本能力:LongCat-Flash-Omni保持了系列卓越的文本基础性能,在多领域领先。与早期版本相比,文本能力不仅未衰减,还在部分领域提升,验证了训练策略的有效性和多模态协同价值。
图像理解:在RealWorldQA测试中,LongCat-Flash-Omni得分为74.8分,与Gemini-2.5-Pro相当,优于Qwen3-Omni。其多图像任务优势显著,得益于高质量图文、多图像及视频数据集的训练。
音频能力:在ASR、TTS、语音续写等任务中表现突出。ASR在LibriSpeech、AISHELL-1等数据集上优于Gemini-2.5-Pro;S2TT在CoVost2表现强劲;音频理解在TUT2017、Nonspeech7k等任务中达最优水平;音频到文本对话在OpenAudioBench、VoiceBench表现优异,实时交互评分接近闭源模型,类人性指标优于GPT-4o。
视频理解:视频到文本任务性能达最优,短视频理解大幅领先,长视频理解比肩Gemini-2.5-Pro与Qwen3-VL,得益于动态帧采样、分层令牌聚合策略及长上下文支持。
跨模态理解:性能优于Gemini-2.5-Flash,比肩Gemini-2.5-Pro,在真实世界音视频理解WorldSense基准测试中显著领先其他开源全模态模型,展现高效多模态融合能力,是当前领先的开源全模态模型。

端到端交互:鉴于当前行业内缺乏成熟的实时多模态交互评估体系,LongCat团队打造了一套专属的端到端评测方案,涵盖定量用户评分(250名用户参与)和定性专家分析(10名专家对200个对话样本进行评估)。定量结果显示,在端到端交互的自然度与流畅度方面,LongCat-Flash-Omni在开源模型中表现突出,其评分比当前最优开源模型Qwen3-Omni高出0.56分。定性结果表明,LongCat-Flash-Omni在副语言理解、相关性与记忆能力三个维度上与顶级模型相当,但在实时性、类人性与准确性三个维度仍有提升空间,未来将进一步优化。