
8月29日,由清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型“极数”(LimiX)正式宣布开源。此次发布标志着我国在结构化数据智能应用领域的技术突破与生态开放迈出了关键一步,将显著降低千行百业的AI技术门槛。特别是在结构化数据占主导的泛工业领域,“极数”大模型将助力AI深度融入工业生产全流程,破解工业数据价值挖掘难题,为实现智能制造与新型工业化提供关键支撑,推动产业技术变革和优化升级。
泛工业领域渴求准确高效的结构化数据智能应用技术
在泛工业领域,结构化数据的智能处理能力直接影响产业效率与科研突破。因语言大模型(LLM)和私有数据+专用模型两种传统的结构化数据处理范式长期存在准确率低、难泛化、不通用,成本高等一系列缺陷,严重制约了AI在工业场景的落地路径。
“极数”大模型通过学习数据因果关系,实现了可在不同上下文信息中捕捉因果变量,数据分布的能力,以适应分类、回归、缺失值预测、数据生成、因果推断等任务。在产业应用层面,“极数”大模型已成功落地多个真实工业场景,单一模型适配多场景、多任务的通用性突破获得合作企业的高度认可,形成了面向泛工业垂直行业核心业务场景的真正智能底座。

“极数”模型在多领域任务中获得性能突破
“极数”模型的研发核心团队由国家杰出青年科学基金获得者、国家自然科学二等奖得主、国际计算机协会(ACM)杰出科学家、清华大学计算机系崔鹏教授牵头组建,团队兼具学术研究深度与产业落地能力。
“极数”模型在评测方面,选取了各个领域的权威数据集作为Benchmark。如开源数据集Talent,它包含上百个真实数据集,是当前领域内体量最大、最具代表性的基准之一。在分类任务中,对比“极数”与24个领域内的最优模型,“极数”大模型的模型性能显著超越其他模型,在AUC、ACC、F1Score和ECE上均取得了最优。
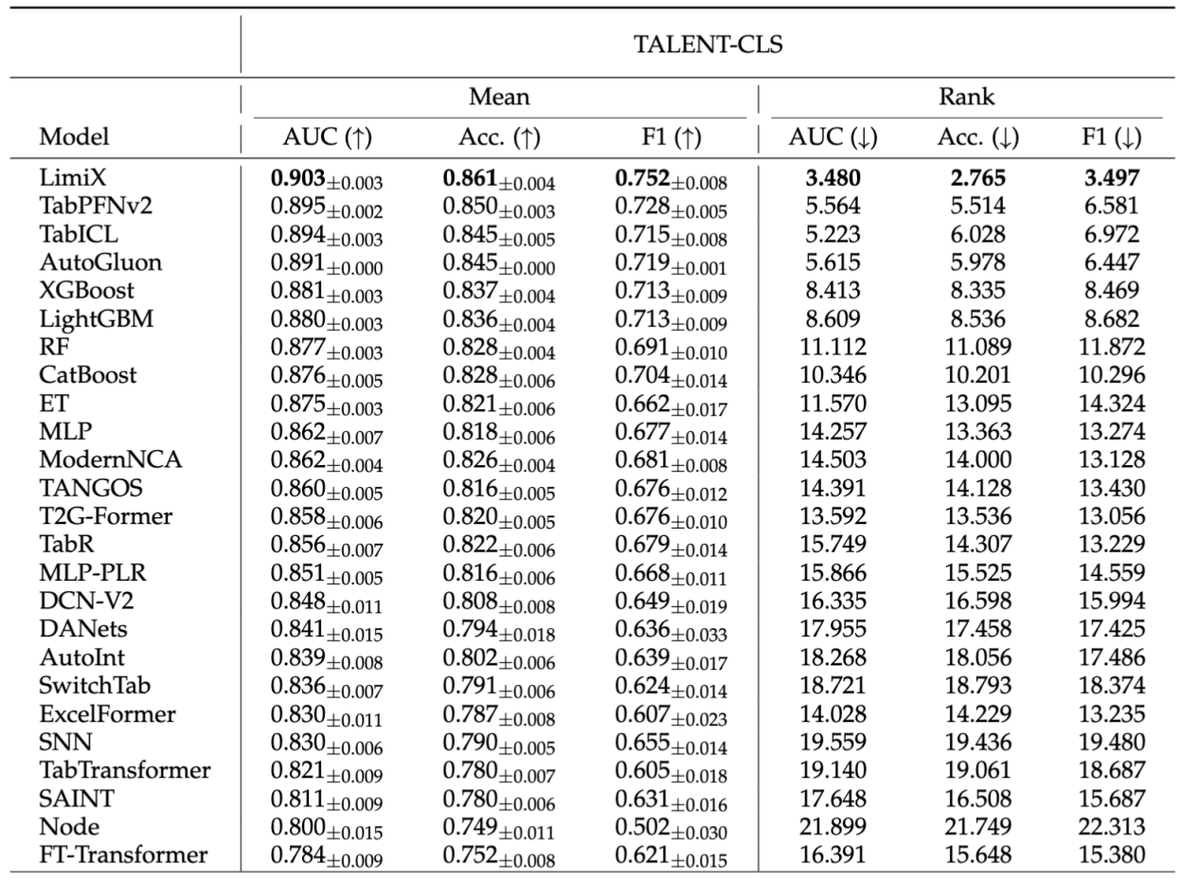
在回归任务上,“极数”大模型在R2和RMSE指标上都达到了平均最优,对比其他最优模型展现出了明显的优势。并且在数据集中有干扰特征或无效特征时,性能优势更加明显。


“极数”已在多个关键工业场景中成功落地
目前,“极数”大模型凭借其优越的通用建模能力,有效破解了传统专用模型在工业场景“数据稀缺、质量参差、环境异质”情况下的能力瓶颈,已在多个关键工业场景中成功落地。
在工业运维领域,“极数”大模型已成功应用于钢铁、能源电力等行业,为设备运行监测、故障预警与健康度评估等任务提供核心支撑;在工艺优化领域,“极数”大模型在化工、制造、生物等行业中化身为“生产智囊”;在市场预测领域,“极数”大模型正成为能源、零售、农业、消费品等行业应对市场波动的“交易智囊”,为风险规避、成本控制与盈利提升提供核心决策支撑。
目前,“极数”大模型已经开源,在Github、Huggingface、Modelscope等平台搜索LimiX即可查询。