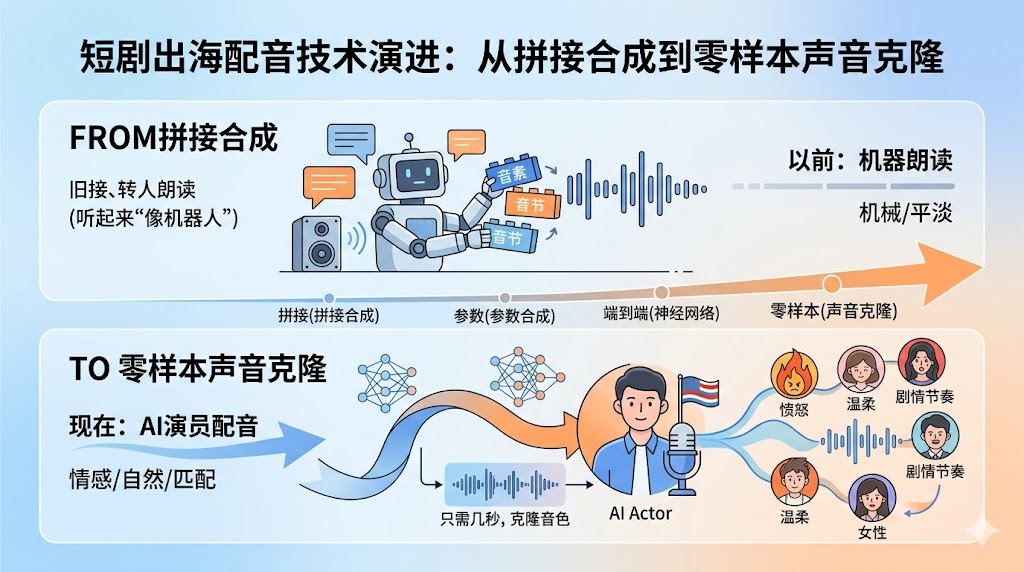
短剧翻译完了,但配音听起来"像机器人"。情感不对:该愤怒的地方平淡,该温柔的地方僵硬。节奏不对:语速太快或太慢,破坏剧情节奏。音色不对:霸总用了少年音,女主用了大妈音。
短剧配音不是"把文字读出来",而是"用声音演戏"。这对TTS(Text-to-Speech,语音合成)技术提出了极高要求:情感可控、节奏可控、音色匹配。
这篇文章梳理TTS技术的演进历程,看看业界如何从"机器人朗读"进化到"AI演员配音"。
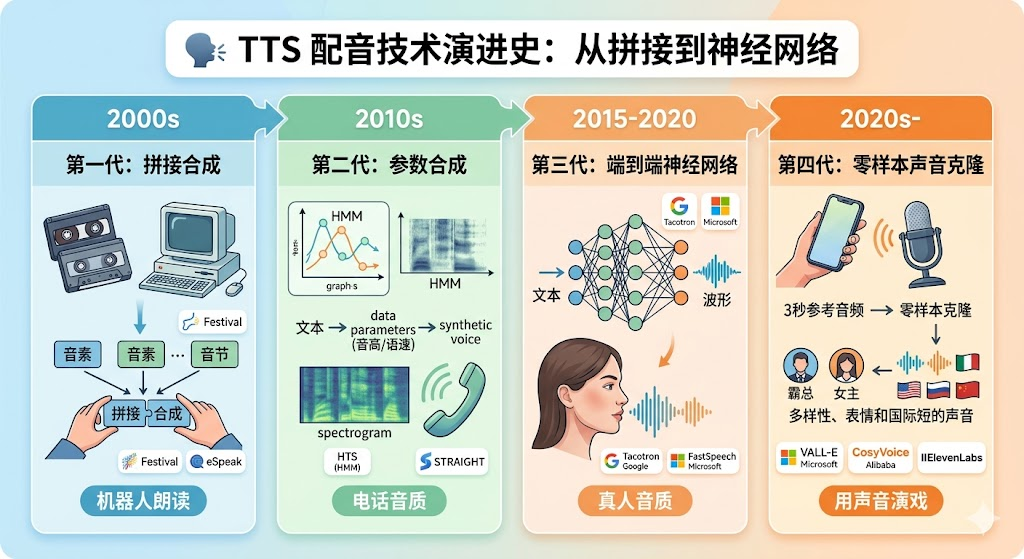
技术原理:
录制大量语音片段(音素、音节),根据文本拼接对应片段。就像用乐高积木拼出一句话——每个积木是一个音素,拼在一起就是完整的句子。
代表系统:
Festival(开源,1990年代)
eSpeak(轻量级,适合嵌入式设备)
优点:
实现简单,不需要复杂的算法
计算量小,可以在低性能设备上运行
缺点:
拼接痕迹明显,听起来像"机器人"
情感表达几乎为零(因为每个片段是独立录制的)
不适合短剧场景(短剧需要情感表达)
为什么会有"机器人感"?
因为人类说话时,每个音素的发音会受到前后音素的影响(协同发音现象)。拼接合成把每个音素独立处理,忽略了这种连续性,所以听起来不自然。
第二代:参数合成(2010年代初)技术原理:
不再拼接录音片段,而是用数学模型(声学模型)生成语音参数,再通过声码器合成波形。
代表系统:
HTS(HMM-based Speech Synthesis)
STRAIGHT(声码器)
技术细节:
使用隐马尔可夫模型(HMM)建模语音的时序特征:
训练阶段:从录音中提取声学参数(基频、频谱包络、非周期成分)
合成阶段:根据文本生成参数序列,再用声码器合成波形
优点:
比拼接合成自然(因为考虑了音素之间的连续性)
可以调节音高、语速(通过修改参数)
缺点:
音质模糊,听起来像"电话音"(因为声码器的限制)
情感表达有限(只能调整整体的音高和语速,不能做细粒度控制)
仍不适合短剧场景
为什么音质模糊?
因为声码器(STRAIGHT)在重建波形时会丢失高频细节。人耳对高频细节很敏感,丢失后就会觉得"不清晰"。
第三代:端到端神经网络(2015-2020)技术突破:
用深度学习直接从文本生成语音,不再需要手工设计声学模型和声码器。这是TTS技术的革命性进步。
Tacotron(2017,Google)
技术原理:
基于Seq2Seq(序列到序列)架构,直接从文本生成Mel频谱(声音的频谱表示),再用声码器(Griffin-Lim或WaveNet)合成波形。
架构:
文本 → Encoder(编码器)→ Attention(注意力机制)→ Decoder(解码器)→ Mel频谱 → 声码器 → 波形
创新点:
端到端训练(不需要手工对齐文本和语音)
注意力机制(自动学习文本和语音的对应关系)
音质大幅提升(接近真人)
缺点:
推理速度慢(生成1秒音频需要10秒)
注意力机制不稳定(有时会跳字或重复)
Tacotron2(2018,Google)
改进:
改进注意力机制(Location-Sensitive Attention),解决跳字问题
配合WaveNet声码器,音质进一步提升
效果:
在MOS(Mean Opinion Score,平均意见分)测试中,Tacotron2的得分接近真人录音(4.5分 vs 4.6分,满分5分)。
缺点:
推理速度仍然慢。WaveNet声码器是自回归模型,生成每个采样点都需要依赖前面的采样点,导致速度慢。
FastSpeech(2019,微软)
技术突破:
解决Tacotron推理慢的问题。核心思路是并行生成,而不是自回归生成。
技术原理:
使用Transformer架构 + Duration Predictor(时长预测器):
Duration Predictor预测每个音素的时长
根据预测的时长,并行生成所有帧的Mel频谱
速度提升10倍以上
优点:
推理速度快(实时率>1,即生成1秒音频<1秒)
音质接近Tacotron2
可以控制语速(通过调整Duration Predictor的输出)
缺点:
需要大量训练数据。每个音色需要10-20小时的录音,成本高。
第四代:零样本声音克隆(2020-至今)技术突破:
只需要几秒钟的参考音频,就能克隆音色。这是TTS技术的又一次革命。
VALL-E(2023,微软)
技术原理:
把TTS当作语言模型任务来做(类似GPT):
把音频编码成离散的token(使用Neural Codec)
用Transformer预测下一个token
只需3秒参考音频,就能克隆音色
创新点:
零样本克隆(不需要针对新音色训练)
支持情感迁移(参考音频的情感可以迁移到新文本)
效果:
在零样本场景下,音质接近真人。但推理速度较慢(因为是自回归模型)。
CosyVoice(2024,阿里)
技术原理:
基于Flow Matching的零样本多语言TTS:
使用Conditional Flow Matching生成Mel频谱
支持情感控制(可以指定"愤怒""温柔"等情感标签)
推理速度快(实时率>1)
优点:
零样本克隆
情感可控(这是短剧场景的关键需求)
推理速度快
开源(可以自己部署)
短剧场景的适配:
CosyVoice特别适合短剧配音,因为:
支持逐句情感控制(不是整段统一情感)
支持多语言(中英日韩泰等10+种语言)
音质高(MOS 4.3+)
ElevenLabs(2023,商业产品)
技术特点:
音质最接近真人的商业TTS服务:
支持情感细节(呼吸声、停顿、语气转折)
零样本克隆(上传几秒音频即可)
支持29种语言
优点:
音质极高(MOS 4.5+,接近真人)
情感表达丰富
缺点:
成本高(按字符计费,1000字符约$0.3)
API限流(免费版有调用次数限制)
要求1:情感表达的精细控制
短剧的情感变化非常快:
前一句还在温柔说话:"我真的很喜欢你..."
下一句突然愤怒爆发:"但你为什么要骗我!"
再下一句又变成委屈哭泣:"我那么信任你..."
传统TTS只能控制"整体情感"(整段话是愤怒或温柔),但短剧需要逐句甚至逐词的情感控制。
技术方案:
基于情感标签的细粒度控制:
从剧本中提取情感信息(通过LLM分析)
为每句话标注情感标签(愤怒/温柔/搞笑/悲伤)
在TTS合成时注入情感参数
案例:
文本:"你给我滚!"
情感标签:愤怒(强度9/10)
TTS参数:音高+20%,语速+30%,音量+40%
要求2:节奏感与停顿
短剧的"爽感"很大程度来自节奏:
霸总说话要有"停顿"和"重音":"你,给我,滚!"
搞笑场景要有"语速变化":快速吐槽→突然停顿→反转
传统TTS的节奏是"均匀"的,缺少这种"演技"。
技术方案:
基于标点符号+语义的智能停顿:
识别标点符号(逗号、句号、感叹号)
基于语义识别"重音词"(通常是动词、形容词)
在重音词处加重音,在标点处加停顿
案例:
文本:"你,给我,滚!"
停顿:[你] 0.3秒 [给我] 0.3秒 [滚!]
重音:[滚] +50%音量
要求3:音色与角色匹配
短剧中不同角色需要不同音色:
霸总:低沉、磁性、有力量感
女主:甜美、清脆、有少女感
反派:阴冷、尖锐、有攻击性
传统TTS只有固定的几个音色,不够灵活。
技术方案:
零样本声音克隆:
从演员配音中提取音色(只需3-5秒)
用提取的音色合成新文本
支持音色混合(多个音色按比例混合,生成新音色)
案例:
霸总音色 = 70%低沉男声 + 30%磁性男声
女主音色 = 80%甜美女声 + 20%少女音
业界TTS配音方案对比对比维度:
音质(接近真人程度)
情感表达能力
支持语种
推理速度
成本
API开放程度
🔵 Azure TTS微软出品,音质高,支持100+语种覆盖面最广,推理速度快,成本适中。情感表达属于预设情感,可控性一般——适合需要多语言出海、对情感细腻度要求不高的场景。
🟡 ElevenLabs目前公认音质天花板,情感细节最丰富,声音几乎以假乱真。但只支持29种语言,推理速度中等,成本最高——适合对声音品质极度挑剔、预算充足的创作者。
🟢 CosyVoice阿里开源方案,音质高、情感可控、推理速度快,最大优势是开源免费,长期使用成本极低——适合有一定技术能力、想自己部署的团队。
🦐 雅译(AI解说大师)专为短剧/解说场景优化的TTS,音质高、情感表达针对短视频节奏调校,推理速度快,成本适中——适合电影解说、短剧配音的内容创作者直接上手。

挑战1:多语种情感表达的差异
不同语言的情感表达方式不同:
中文:情感表达直接("我爱你")
日文:情感表达含蓄("好きです"比"愛してる"更常用)
英文:情感表达夸张("I love you so much!")
如果用同样的情感参数合成不同语言,会导致"文化违和感"。
解决方案:
为每种语言建立情感参数库,根据目标语言调整情感强度。
挑战2:配音与画面的同步
短剧的画面和配音必须精确同步:
演员张嘴时,配音要开始
演员闭嘴时,配音要结束
演员表情变化时,配音情感要匹配
但翻译后的文本长度变化,导致配音时长不匹配。
解决方案:
动态时间规整(DTW)+ 语速调节:
识别画面中的"张嘴-闭嘴"时间点
调整配音语速,使其与画面同步
在0.8x-1.2x范围内调整(超出这个范围会听起来不自然)
挑战3:批量生产的质量稳定性
短剧出海需要批量生产(一天几十集),但TTS的质量不够稳定:
有时情感表达过度(太夸张)
有时情感表达不足(太平淡)
有时出现发音错误(多音字、专有名词)
解决方案:
质量检测 + 自动重试:
用ASR反向识别生成的配音
检测发音错误、情感异常
自动重试(调整参数后重新生成)

趋势1:多模态情感联动
当前:TTS只根据文本生成语音
未来:结合视频画面(演员表情、肢体语言),自动调整配音情感
技术方案:
用多模态模型(如Video-LLaMA)理解画面情感
将画面情感映射到TTS参数
实现"看图说话"式的配音
趋势2:实时情感调节
当前:情感需要预先标注
未来:用户可以实时调节情感强度(像调音量一样调情感)
应用场景:
创作者可以试听不同情感版本
选择最合适的情感强度
趋势3:个性化音色定制
当前:音色库是固定的
未来:用户可以"设计"音色(调节音高、音色、语速、情感倾向)
技术方案:
基于音色向量的插值
用户通过滑块调节音色参数
实时预览效果
总结从拼接合成到零样本声音克隆,TTS技术的进步让短剧出海的配音门槛大幅降低。
以前:需要找配音演员,录音、后期,成本高、周期长现在:AI配音,15分钟生成多语种版本,成本降低90%
但技术只是工具,内容才是核心。好的短剧出海翻译工具应该让技术透明化,让创作者专注于内容本身。
短剧出海的配音技术还在快速演进,未来会有更多突破。但核心始终是:让AI不只是"读文字",而是"用声音演戏"。