CAN LARGE LANGUAGE MODELS FIND AND FIX VULNERABLE SOFTWARE?
David Noever
PeopleTec, 4901-D Corporate Drive, Huntsville, AL, USA, 35805
david.noever@peopletec.com
引用
Noever D. Can large language models find and fix vulnerable software?[J]. arXiv preprint arXiv:2308.10345, 2023.
论文:https://arxiv.dosf.top/abs/2308.10345
摘要
在这项研究中,我们评估了大型语言模型(LLM),特别是OpenAI的GPT-4在检测软件漏洞方面的能力,并将其性能与Snyk和Fortify等传统静态代码分析器进行了比较。我们的分析涵盖了许多软件库,包括美国国家航空航天局(NASA)和国防部的软件库。GPT-4发现的漏洞大约是同类产品的四倍。此外,它还为每个漏洞提供了可行的修复方法,误报率很低。我们的测试涵盖八种编程语言的129个代码样本,发现PHP和JavaScript的漏洞最多。GPT-4 的代码修正使漏洞减少了90%,而所需的代码行数只增加了11%。一个重要的启示是,LLMs 能够进行自我审计,对其发现的漏洞提出修复建议,并强调其精确性。未来的研究应探索系统级漏洞,并整合多种静态代码分析器,以获取对LLM全面潜力的认识。
1 引言
软件系统日趋复杂且无处不在,这就要求采用先进的方法来确保其安全性。虽然HP Fortify或Snyk等传统的基于规则的静态代码分析仪在识别软件漏洞方面发挥了重要作用,但它们基于规则的特性有时会遗漏细微或不断变化的威胁。OpenAI的ChatGPT等大型语言模型(LLM)为应对这一挑战提供了新的途径。在大量文本数据的支持下,LLMs在理解和生成代码方面已显示出潜力,这表明它们可以很好地找出并纠正软件漏洞。
最近的探索展示了LLM在检测安全漏洞方面的能力,有时甚至超过了传统方法。例如,一个LLM在单个代码库中发现了213个安全漏洞,凸显了其作为安全工具的潜力。此外,LLM还被应用于各种编码环境,从可视化编程到Java函数,LLM常常显示出在代码生成和理解方面的能力。此外,LLMs还能应对代码演化、高性能计算和自我协作代码生成等挑战,显示出很强的适应性。
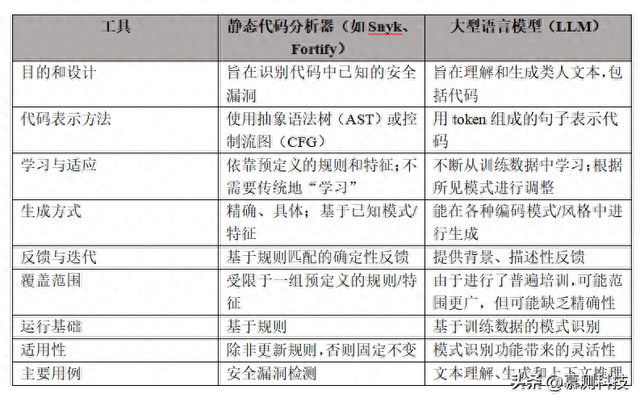
在本文中,我们将全面考察LLM在识别和纠正软件漏洞方面的性能。通过使用LLM和代码分析器检查GitHub上的大量软件源,我们旨在对比它们在解决软件安全问题方面的功效。通过比较,我们可以深入了解LLM在软件漏洞检测和纠正方面的优势和局限性。表 1比较了两种方法识别软件漏洞的意图和设计。
虽然一些评估表明ChatGPT在漏洞检测方面具有潜力,但LLM在软件安全方面的广泛影响仍是一个未决问题。随着软件领域的不断发展,利用LLM与传统方法相结合的能力可能会为更安全、更强大的系统铺平道路。本研究旨在为这一不断发展的讨论做出贡献,更清晰地展示LLM在追求软件安全性过程中的地位。由于之前的工作侧重于从文本描述中生成代码的LLM,本研究将漏洞识别工作扩展到了缓解措施和软件修复。
我们将测试数据集从缓冲区溢出或命令注入等传统编程类别扩展到分析美国国家航空航天局(NASA)飞行系统和代码分析器、美国国家地理空间情报局、国防部挑战和安卓战术攻击工具包(ATAK),以及领先的人工智能视觉和微软研究院的网络代理和强化库等公共和重要的科学资源库。通过将挑战推广到编程案例研究以外的领域,我们试图与使用协作式编码工具来增强技能但往往并不打算自己成为专业软件开发人员的科学界建立联系。个人编码助手可以直接激发解决数学、物理、化学、生物和软件工程等领域问题的新思路,使这部分人受益匪浅。
作为最终评估,我们要求GPT-4重写存在漏洞的代码,删除所有问题,然后对修正后的同一存储库进行评分。这种方法为LLM提供了一个独特的测试,使其不仅能作为代码扫描器,还能作为代码修正中可审计的漏洞修复器。
表1. 两种代码分析方法的核心异同概述
2 技术介绍
该研究包括通过聊天界面自动访问的最新开放式人工智能模型(GPT-4),系统上下文设置为“充当世界上最强大的静态代码分析器,可分析所有主要编程语言。我将给你一个代码片段,你将识别该语言并分析其漏洞。输出格式为:文件名,检测到的漏洞作为编号列表,建议修复的漏洞作为单独的编号列表。”

图1:比较LLM(左图-GPT-4)与静态代码分析器(右图-HP Fortify)在识别跨站脚本攻击 Objective-C语言的HtmlViewController方法。
我们将这一背景应用于OpenAI的7个不同LLM,其参数大小跨越四个数量级:350M(Ada)、6.7B(Curie)、175B(DaVinci/ GPT3/GPT-3.5-turbo-16k)和1.7万亿(GPT-4)。不过,这些细节都是专有的,至少较大的模型是如此,因为Curie在GitHub多语言软件仓库和OpenAI Codex源代码中进行了数千兆字节的训练。在实践中,超过130亿个参数的扩展首次提示了程序员的技能,而不仅仅是代码注释或基于训练数据记忆的自动完成。自2023年2月发表以来,多个GPT版本更新都显示了更大模型的显著进步(参数缩放的数量级)。OpenAI对一系列技能的编码性能改进进行了评分,包括(简单)Leetcode考试分数从12/41 正确率(GPT-3.5)增长到31/41正确率(GPT-4)。

图2. 已发现漏洞和已修复漏洞的分类计数显示出密切关系。
在所有情况下,我们使用应用程序接口(API)自动查询LLM,在系统上下文中查找漏洞和修复措施,然后使用八种流行编程语言(C、Ruby、PHP、Java、Javascript、C#、Go和 Python)编写示例代码。在每种情况下,我们都要求LLM识别编码语言、查找漏洞并提出修复建议。
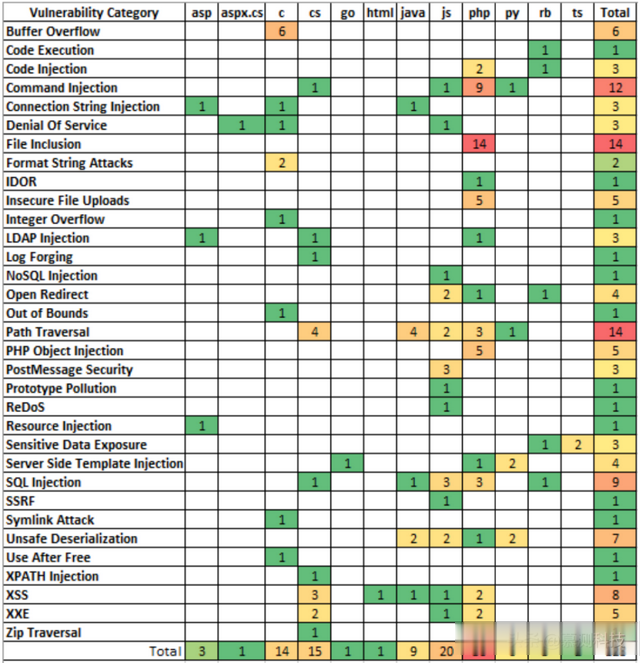
安全漏洞单一代码库包含128个代码片段,以所有八种编程语言为例,说明了33个漏洞类别。这些类别从缓冲区溢出到敏感数据暴露不等。有50个案例涉及PHP,其漏洞与文件包含和命令注入有关。漏洞语言矩阵说明了附录A对探索代码扫描仪的总体覆盖范围。整个软件的可执行代码行数为2372行,不包括标记符和HTML。
我们向自动静态代码扫描器Snyk提交了GitHub上的六个公共存储库,亚马逊AWS云、谷歌、Salesforce、Atlassian和Twilio等公司的数百万开发人员和用户都依赖于该项目。这些不同扫描的作用在于说明大量可识别的漏洞(“发现”)以及LLM所解决的语言问题的广度。对于每个文件,Snyk都会提供漏洞情报仪表板,其中包含严重性(关键、高、中、低)、优先级分数(0-1000)、可修复性(可修复、部分可修复、无修复)、漏洞利用成熟度(成熟、概念验证、无已知漏洞利用和无数据)等综合指标、状态(开放、已打补丁 忽略)和依赖性问题的综合指标。

图3. LLM与Snyk的漏洞类别比较
作为最后的评估,我们使用应用程序接口向GPT-4自动提交了所有129个代码样本,但这次的提示只寻求修正后的代码。一般系统提示如下“充当世界上最强大的静态代码分析器,分析所有主要编程语言。我将给你一个代码片段,你将分析代码并重写它,删除任何已发现的漏洞。不要解释,只需返回更正后的代码和格式。”
在将 GPT-4 返回的代码后处理为文件并将文件上传到可扫描的GitHub之后,我们将修正后的存储库重新提交给Snyk,以便与存在漏洞的代码库进行比较。通过这种方式,评估试图对LLM的自我修正能力进行评分,因为LLM不仅能自动识别漏洞,还能自动重写代码,以确保整个代码库的安全,这一点已得到第三方静态代码扫描仪的客观验证。
3 成果
图1显示了一个初始示例,用于说明静态代码分析仪(HP Fortify)结果与LLM(OpenAI的GPT-4 2023AUG3版本)之间的比较。两种方法都能正确识别Objective-C语言中名为HtmlViewController方法中的三个漏洞。不过,LLM版本用简单的英语解释了漏洞产生的原因,以及攻击者如何利用用户输入利用漏洞。然而,本示例的重大区别在于针对每个漏洞提出了三个修复方案。为了完成漏洞查找和修复过程,LLM提供了经过修订的代码,对三种已识别的情况进行了修补,以对输入进行缺陷修复,在读取文件后检查错误,并验证预期的字符串格式。
安全漏洞单一代码库作者公布的漏洞列表指出,GPT-3(text-davinci-003)发现了213个安全问题,而Snyk只发现了99个(不包括Snyk未涵盖的C和Go中的16个文件)。在对213个漏洞中的60个进行随机人工检查时,只有4个是误报,但DaVinci和Snyk两种工具都有许多误报或漏报的漏洞。
本研究扫描了与Snyk相同的代码库,并在运行中发现了98个漏洞,其中约三分之二的漏洞被列为高度严重(H- 66、M-20、L-12)。使用3AUG2023 GPT-4 API,我们的结果显示发现了393个漏洞,几乎是DaVinci(213个)的两倍,是Snyk(99个)的四倍。我们对GPT-3-Turbo-16K的评分大致相当于对GPT-3的评分结果,发现的漏洞数为217个。对Curie和Ada模型的随机检查表明,它们只是在重复行业术语,并没有提出修复漏洞的具体建议。这一观察结果表明,在60亿到1750亿个参数之间,OpenAI GPT系列中表现出了重要的代码理解。
一个值得关注的特点是,GPT-4建议的代码修复数量也等于398个,这支持了较低的误报率,因为询问解决方案会迫使模型证明漏洞识别的合理性,并纠正任何错误陈述或幻觉反应。图2显示了按129个文件中每个文件的漏洞数量排序时,发现的漏洞与提出的修补程序之间的联系。该图证明了一个观点,即真正的结果也必须有建议的修补方案(或在某些情况下,不止一个)。
表2. 存在安全漏洞的单一代码库(SLOC = SW 代码行数)

图3着重说明了LLM分析(GPT-4)与Snyk相比发现的漏洞类别。对于排名前两位的漏洞类别(路径遍历和文件包含),GPT-4发现的安全漏洞数量是 Snyk的三到四倍,并且同样为每个发现提出了修复方案。
表2总结了LLM代码自动修正的评估结果。与原始的漏洞代码库相比,LLM增加了 11%的软件代码行来缓解已识别的漏洞。当Snyk对修正前后的漏洞严重性进行评分时,LLM 将高严重性漏洞的数量减少了94%,中严重性漏洞减少75%,低严重性漏洞减少了92%。单从数字上看,代码库缓解措施将漏洞数量从98个减少到10个。
图4显示了按编程语言分列的LLM漏洞识别和修复情况,其中PHP和JavaScript占了近一半。GPT-4在所有编程语言中成功地正确识别了类型(如python),而无需在系统上下文中包含该提示。这种自动识别代码的方法可实现潜在的自动化目标,适用于具有复杂遗留软件堆栈的大型代码库。
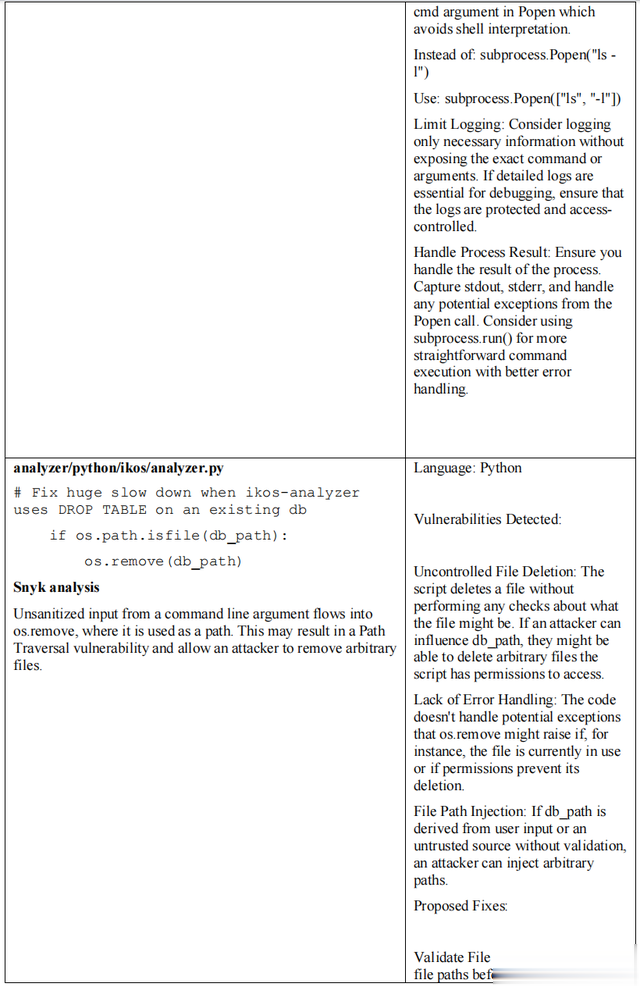
附录B重点介绍了Snyk输出与LLM (GPT- 4)分析的并排比较,后者针对的是用PHP编写的易受攻击图片上传程序。
为了探索现实世界中更突出、更复杂的代码库,我们向Snyk提交了七个公共GitHub存储库,并在表3中收集了已识别漏洞的数量和严重程度。国防部软件库中的“黑客卫星(HAS)”项目指的是在DEFCON黑客马拉松之前的资格挑战,因此强调一些潜在漏洞是其任务的一部分。美国国家航空航天局(NASA)为验证和核查(VnV)进行软件扫描的软件显示,Snyk扫描的漏洞数量位居第二。
表3. 大型代码库和Snyk发现的严重软件漏洞

表中显示的GitHub星级代表了其受欢迎程度,因此也代表了其在现实世界被利用的可能性。我们使用cloc可执行文件计算软件代码行数(SLOC),作为代码复杂性的替代度量。
其中最受欢迎的资源库是Ultralytics的物体检测库,许多计算机视觉项目都在使用它。2022年,最受欢迎的资源库(TensorFlow)共有177,000 颗星,其次是Linux,共有156,000 颗星。在这个相对等级中,我们可以推断出YOLOv5的受欢迎程度可以与一些最大的公共软件库相媲美,达到40,900颗星。YOLOv5的SLOC总量仅是易受攻击代码库的四倍,这表明代码复杂度大致相同,尽管Python代码的大部分依赖于open-cv等未扫描的库。除了复杂性和受欢迎程度的代用指标外,NASA软件扫描仪中的漏洞也值得进一步调查,因为该 repo是关键太空资产的授权代理,如果存在某些未修正的缺陷,可能会危及人类生命安全。
这些项目的基于规则的代码扫描器和 LLM 示例见附录B。
4 讨论
本研究的动机之一是扩展“单一安全漏洞代码库”的基准,以识别假漏洞代码,并对不同编码语言和漏洞类别的修复和分布情况进行编目。这里要测试的一个假设是,GitHub上的Python、C和Java等语言数量较多,是否有利于模型发现漏洞代码的能力。
第二个动机集中在LLM的批评上,即他们的输出似乎不可靠或容易产生幻觉,因为其基本优化是执行下一个标记或单词预测,只有在成熟后期才会受益于可靠性检查。OpenAI 在其聊天界面上承认,“ChatGPT可能会生成不准确的人物、地点或事实。”
因此,这项工作研究了漏洞与修复的匹配是否是一个自我反思的触发器,迫使模型重新评估其最初的结论。从某种意义上说,对模型识别缺陷的可靠性进行最有效的测试,就是迫使它找到修复方法,然后在能正常运行的代码中实施修复。这种良性循环为基于规则的专家系统(如静态代码分析器)补充LLM提供了强有力的支持。如果假定GPT-4案例与实际漏洞数量相当接近,那么这一发现表明,在1,750亿到1.7万亿个参数之间,LLM系列比小型模型减少了一半的错误否定,比Snyk实例减少了四分之三。未来的计划应将此分析扩展到 HP Fortify和Snyk之外的其他静态代码分析器,以提高通用性;SonarQube仍然是一个值得尝试的流行开源版本。
值得注意的是,测试的代码片段通常只有几十行或几百行,因此发送到模型的令牌数量限制在500个以下。这种提示和令牌响应限制(1024)使API方法无法分析系统级漏洞或查看依赖关系或库错误。由于漏洞测试的规模,这种方法是合理的,但未来使用OpenAI最近发布的代码解释器的工作应能实现系统级查询,如附录B所示。
最显著的结果包括使用LLM作为代码扫描器发现的漏洞增加了四倍,而使用GPT-4代码修正则减少了90%的漏洞。从简化的角度看,只有11%的额外软件代码行能消除已发现的安全漏洞。
在目前没有应用程序接口的情况下,如果有适当的提示和进一步分析探索的提示,手动用户的后续问题很可能会扩展模型答案的深度。向自己的代码“提问”有一个引人入胜但往往被低估的优势,那就是互动形式可以激发想法,而静态响应往往会将想法扁平化或转化为繁琐的工作和冗长的待办事项清单。我们可以预见,未来的副驾驶或编码助理角色将演变为导师与门徒之间的关系,在这种关系中,软件需求将得到满足。按编程划分的GPT-4发现和修正。在人类和机器之间进行语言优先排序,以交付最高效、最不易受攻击的软件。
附录A:单一代码库数据集中查找和修复覆盖率的漏洞语言矩阵
附录B:GPT-4与Snyk在安全代码库上发现的漏洞和修复示例






转述:叶豪