2026年4月24日,DeepSeek quietly发布了V4系列——包含V4-Pro(高精度科研)和V4-Flash(低成本部署)双版本。这条消息在技术圈激起的涟漪,远比大多数人意识到的更深远。原因在于:V4引入了一个听起来很学术、但实际影响可能极为深远的新架构——Engram(记忆印迹)。这个架构创新,可能从根本上改变大模型处理长上下文的经济账。
长上下文的"隐形炸弹":KV Cache要理解Engram架构的意义,必须先理解当前大模型面临的一个核心瓶颈:KV Cache的内存占用。当你向一个大模型输入10万token的文档,让它基于此文档回答问题,模型需要为每一个token维护一组"键值对"(Key-Value Cache),用于在生成每个新token时计算注意力。这些键值对消耗的内存,与上下文长度成线性关系。
具体来说:对于DeepSeek-V3(V4的上一代),处理100万token的上下文,KV Cache需要约96 GB的显存。这个数意味着什么?一张NVIDIA A100(80GB显存)根本跑不动;即使用8张A100组成集群,也有相当一部分显存被KV Cache占据,无法用于模型参数本身。这就是为什么,到目前为止,"百万token上下文"基本只存在于发布会上——实际应用中,极少有人真正在100万token的上下文窗口上跑模型。
DeepSeek-V4的Engram架构,给出的答案是:把KV Cache压缩到原来的10%。100万token上下文,KV Cache只需要约9.6 GB。一张80GB的A100,现在可以轻松跑起来。这不是通过降低精度(比如从FP16降到INT4)实现的——Engram是一种架构级创新,它改变了KV Cache的存储和访问方式。
Engram架构:受海马体启发的设计Engram这个词,来源于神经科学——它指的是大脑中物理层面的记忆痕迹。DeepSeek团队从这个概念出发,设计了一套全新的KV Cache管理机制:
核心思路是:在标准的Transformer模型中,KV Cache被完整地存储在GPU显存中,每个token的键值对都被保留。但人类大脑并不会把每一个感知细节都完整地存在神经元里——大脑会压缩、筛选、重组记忆。Engram架构模拟了这个过程:它将KV Cache中的冗余信息动态压缩为低维向量,存储在系统内存(甚至NVMe SSD)中,而不是全部放在昂贵的GPU显存里。当模型需要访问历史上下文时,按需从系统内存或SSD中召回相关部分。
这个设计的精妙之处在于:大部分上下文的访问频率是极低的。在一个100万token的文档中,模型在生成第100万零1个token时,真正需要密集访问的,可能只是其中几千个token。Engram架构通过注意力模式的统计分析,动态地判断哪些KV对需要常驻GPU显存,哪些可以"下放"到系统内存,哪些甚至可以放到NVMe SSD上。
根据DeepSeek技术报告的实测数据:在1M token场景下,Engram架构将KV Cache占用压缩至V3的10%,推理所需FLOPs降至27%。这意味着,同样的硬件,现在可以处理的上下文长度扩展至原来的约3.7倍。
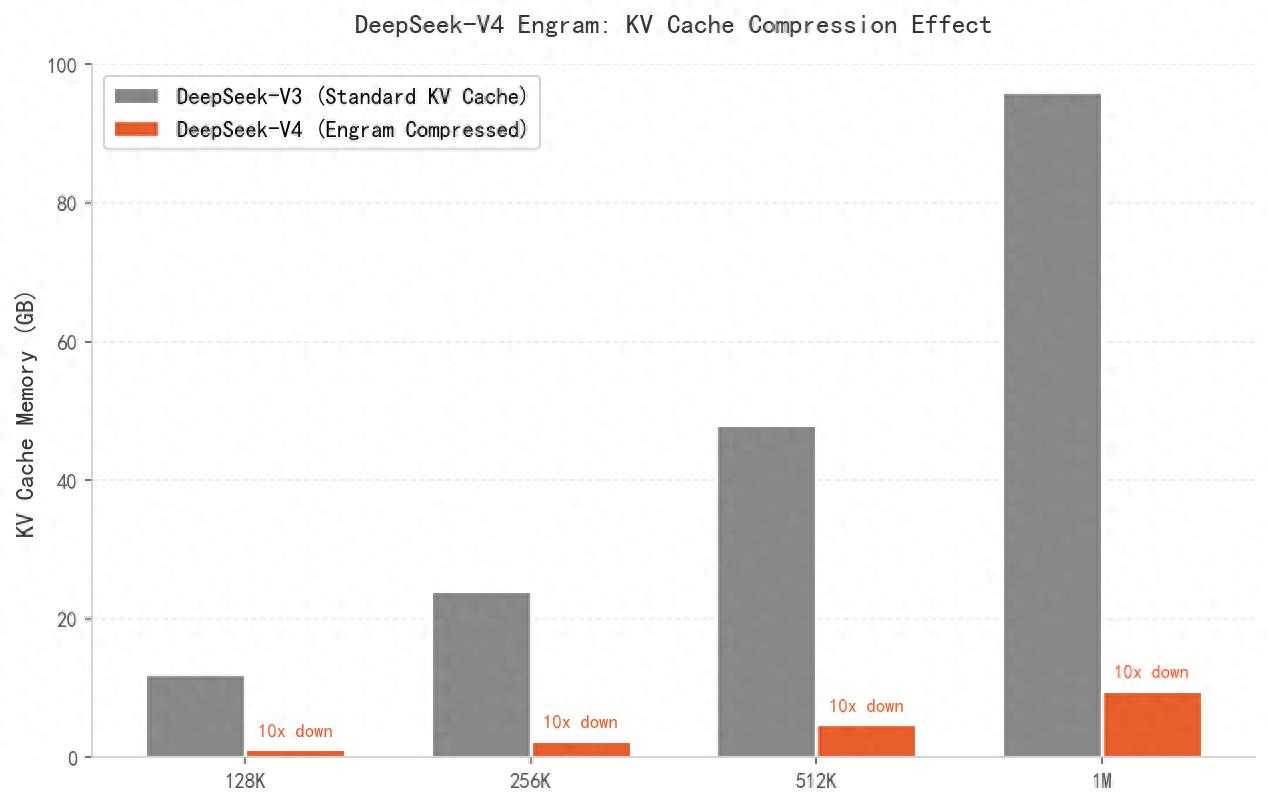
▲ 数据来源:DeepSeek-V4技术报告(2026-04-24)、腾讯云开发者社区《DeepSeek V4深度测评》(2026-04-24)。
mHC框架:解决超深层MoE的训练稳定性Engram是V4最引人注目的创新,但不是唯一的重要改进。与Engram配套推出的,还有一个叫mHC(multi-head Compression)的框架创新,专门解决超深层MoE模型训练不稳定的行业难题。
MoE(混合专家)架构的核心挑战之一是:梯度在多层专家之间传递时,容易出现不稳定。当模型参数规模超过1万亿(V4-Pro的总参数量为1.6T),这种不稳定性会被放大到让训练无法收敛的程度。过去两年,业界有多种尝试来解决这一问题(包括各种形式的专家dropout、负载均衡损失函数等),但效果都不够理想。
mHC框架的思路是:在每一层MoE专家输出之后,引入一个自适应压缩门控,动态抑制低贡献专家的输出,同时稳定梯度流。这听起来很技术,但效果是非常直观的:DeepSeek团队报告称,采用mHC框架后,1.6T参数模型的训练收敛成功率提升至92%。作为对比,不加mHC的同规模模型,在相同的训练配置下,收敛成功率仅有约60%~70%。
成本账:DeepSeek-V4如何做到"极致性价比"?技术亮点说完,来看一组更接地气的数据:推理成本。这是DeepSeek系列模型最核心的竞争力所在。
DeepSeek-V4的API定价(通过DeepSeek官方API):
V4-Flash:输入 $0.4/百万token,输出 $1.1/百万token。综合考虑输入输出(按1:1混合),总成本约$1.5/百万token。V4-Pro:输入 $1.2/百万token,输出 $3.8/百万token。综合成本约$5.0/百万token。作为对比:
GPT-5.5:综合成本约$40/百万token(输入$10 + 输出$30,按1:1估算)Claude Opus 4.8 标准版:综合成本约$90/百万tokenGemini 3.1 Pro:综合成本约$25/百万token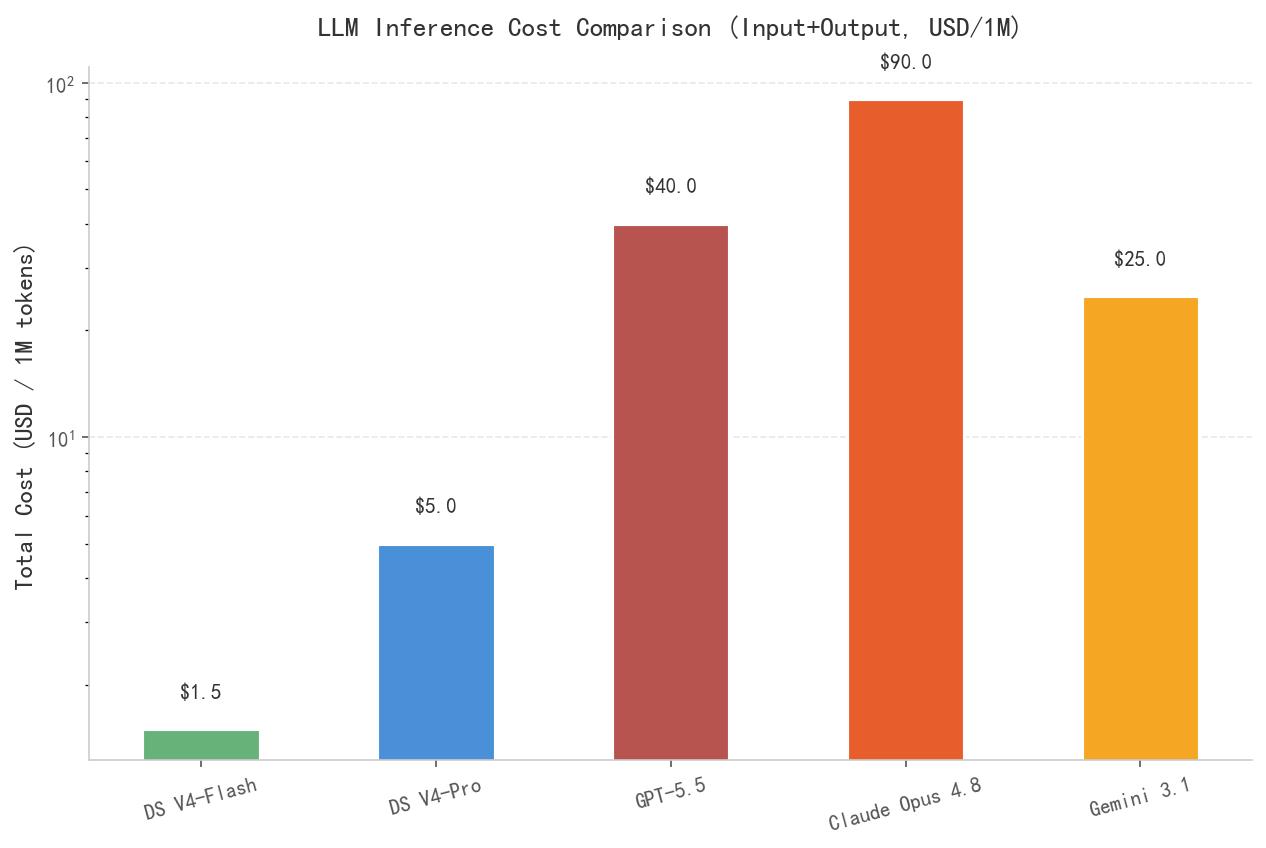
▲ 数据来源:DeepSeek官方API定价页(2026-04)、Anthropic API定价页(2026-05)、OpenAI API定价页(2026-05)。DeepSeek-V4-Flash的成本优势极为显著。
DeepSeek-V4-Flash的成本,是GPT-5.5的约1/27,是Claude Opus 4.8的约1/60。这个数量级的成本差异,不是在"薅羊毛",而是会实质性地改变AI应用的商业模式。举个例子:一家做代码补全的SaaS公司,如果每天处理10亿token,使用GPT-5.5的日均成本约为$4000;而使用DeepSeek-V4-Flash,日均成本仅为$150。一年下来,成本差异超过$140万。
性能代价:便宜是不是等于"不好用"?看到这里,一个必然的疑问是:成本低这么多,性能会不会大打折扣?这是一个完全合理的质疑。让我们用数据来回答。
在代码生成能力上(HumanEval+ Pass@1),DeepSeek-V4(作为内部Coding Agent)得分78.3%。作为对比,GPT-4 Turbo在该基准上得分为72.1%。V4的代码生成能力,已经超越GPT-4 Turbo约6个百分点。
在综合推理能力上,DeepSeek官方技术报告的数据显示,V4-Flash在多数编码和问答任务中,可以达到GPT-5.5性能的85%~90%。考虑到成本仅为GPT-5.5的1/27,这个"性能折扣"是非常值得的——特别是对于高频调用、对延迟敏感、且可以接受适当性能折衷的应用场景(代码补全、文档摘要、客服对话等)。
当然,DeepSeek-V4并非全面领先。根据已公开的数据,在高难度科学推理(生物遗传学、量子化学、高等数学证明)领域,V4-Pro落后GPT-5.5约15~20个百分点。这主要是因为DeepSeek-V4的训练数据中,这部分垂直领域的数据占比较低。对于科研级应用,GPT-5.5和Claude Opus 4.8仍然是最优选择。
华为昇腾适配:一个被低估的战略信号DeepSeek-V4还有一个值得关注的"隐藏亮点":对华为昇腾NPU的原生支持。根据DeepSeek技术报告的附录,V4-Flash在华为昇腾910B NPU上的推理速度达到120 tokens/秒,支持FP8和INT4量化,且可以通过OpenClaw工具链直接部署。
这个能力的战略意义,可能比表面看起来更重大。目前,全球AI算力市场(特别是大模型训练和推理)高度依赖NVIDIA GPU。美国对先进AI芯片的出口管制,使得中国公司在获取最新NVIDIA GPU方面面临越来越大的困难。DeepSeek-V4对昇腾的原生支持,意味着中国公司现在可以用国产算力芯片,跑一个世界级的代码生成大模型。这个组合(DeepSeek-V4 + 昇腾910B)的推理成本,甚至比"NVIDIA GPU + DeepSeek API"的组合还要低。
从更宽的视角看,DeepSeek-V4 + 昇腾的组合,可能正在开创一种"非NVIDIA依赖"的大模型技术路线。这条路线的核心特征是:模型架构专门为国产芯片优化(Engram架构降低显存需求,恰好契合国产NPU显存较小的特点),推理框架开源( OpenClaw工具链),预训练权重开源(DeepSeek社区协议允许商用)。这三条加在一起,构成了一个完整的、不依赖NVIDIA的AI技术栈。
结语:架构创新,才是真正的护城河DeepSeek-V4发布满月,行业对它的讨论,大多还停留在"又一款便宜好用的开源模型"这个层面。但如果你仔细读它的技术报告,你会发现:V4最值钱的,不是"便宜",而是Engram架构所代表的"架构创新"能力。
过去两年,大模型领域的创新,很大程度上是"算力驱动"的:堆更多GPU、用更多数据、训练更大模型。这条路的边界,现在已经越来越清晰了——算力不可能无限增长,数据也不可能无限获取。下一步的突破,必然来自架构层面的创新。Engram架构是这方面一个非常值得尊敬的早期探索。它不一定是最优解,但它证明了一件事:在大模型架构上,还有很大的创新空间。
数据来源备注:1. DeepSeek-V4技术报告(2026-04-24):Engram架构与mHC框架详细说明2. 腾讯云开发者社区《DeepSeek V4深度测评》(2026-04-24):代码能力实测数据3. DeepSeek官方API定价页(2026-04):V4-Flash与V4-Pro定价4. CSDN《代码生成超越GPT-4》(2026-02):DeepSeek-V4代码能力对比数据5. OpenClaw工具链文档(2026-04):昇腾910B适配与推理速度数据