Improving ChatGPT Prompt for Code Generation
Chao Liu1 , Xuanlin Bao1 , Hongyu Zhang1 , Neng Zhang2 , Haibo Hu1 , Xiaohong Zhang1 , Meng Yan1
1School of Big Data and Software engineering, Chongqing University, China
2School of Software Engineering, Sun Yat-sen University, China
引用
LIU C, BAO X, ZHANG H, et al. Improving chatgpt prompt for code generation[A]. 2023. arXiv: 2305.08360.
论文:https://arxiv.org/abs/2305.08360
仓库: https://anonymous.4open.science/r/guiding-chatgpt-for-code-generation-0B0E
摘要
本文讨论了用ChatGPT进行自动化代码生成的有效性,其重点是通过基于需求自动生成代码来减少软件开发的工作量。本研究通过评估CodeXGlue数据集上对ChatGPT进行文本到代码及代码到代码的生成任务效果,揭示了提示设计的重要性。实验采用思考链策略和多步骤优化设计提示,结果表明精心设计的提示能显著提高代码生成性能。研究还分析了影响提示设计的因素,旨在为未来研究提供指导。
1 引言
代码生成是一种旨在基于开发者需求自动生成代码的技术。它可以减少重复的编码工作并提高软件开发的生产力。这些需求可以以自然语言(NL)的形式表达,允许开发者以直观的方式确定他们的需求。例如,开发者可以要求代码生成工具执行“将Java中的整数变量n转换为字符串”,该工具将生成对应的代码示例,如:“String s = Integer.toString(n)”。这个过程被称为文本到代码(T2C)生成。另一种代码生成类型是代码到代码(C2C)生成,它将一个编程语言中的现有代码片段翻译成另一种编程语言。例如,C#代码“String s = n.ToString()”可以翻译成上述的Java代码。C2C生成在将现有代码移植到新的编程语言时很有用。
得益于它们能够在大量的非监督文本数据上进行预训练并在特定领域的数据集上进行微调,如情感分析、语言翻译,大语言模型(LLMs)成为自然语言处理(NLP)任务的强大工具。这种“预训练,微调”的范式已被应用于软件工程(SE)任务,例如代码生成,并取得了较好的结果。例如 CodeBERT,一个与BERT架构类似并在六种编程语言上预训练的LLM。CodeBERT可用于各种SE任务,如代码搜索和总结,表现良好。另一个值得注意的模型是 CodeGPT。CodeGPT使用GPT-2架构在Python和Java数据集上进行预训练,并针对多种SE任务进行微调,如代码生成和代码翻译。
最近,OpenAI推出了基于GPT-3.5架构的革命性LLM,ChatGPT,它可以处理包括代码生成在内的各种任务。与现有的LLMs不同,ChatGPT能够基于用户的文本输入(即提示)通过强化学习生成类似人类的回应。由于其在各类任务上的高有效性,ChatGPT在发布后仅两个月内就吸引了全球1亿活跃用户。然而,ChatGPT的性能高度依赖于使用的提示质量。设计更好的提示,这被称为提示工程。目前这类研究正在积极进行。
在这篇论文中,我们研究了使用各种提示工程方法的ChatGPT代码生成性能。我们使用广泛使用的CodeXGlue数据集对ChatGPT的代码生成能力进行了评估,包括T2C和C2C生成任务。最初,我们为任务使用了基本提示:“写一个Java方法,该方法” + NL描述,用于T2C任务,以及“将C#代码翻译成Java代码:” + 代码,用于C2C任务。实验结果表明,这些提示分别实现了22.76和39.37的CodeBLEU分数,其中CodeBLEU是广泛使用的综合评估指标。
为了提高性能,我们利用了思考链策略与手动构造来增强不同任务的提示。这种方法使用来自ChatGPT的反馈进行多步优化。我们的实验结果表明:1)为提示添加更具体的要求分别使两项任务的CodeBLEU提高了73.58%和3.45%;2)直接要求ChatGPT在提示中生成简洁代码(例如,“写一个简洁的Java方法,该方法” + NL)使T2C任务的CodeBLEU进一步提高到50.18;3)共享一个ChatGPT会话进行多个提示测试也提高了C2C任务的CodeBLEU到48.80;4)由于提示中的具体指令,ChatGPT的随机性对生成性能影响很小。此外,我们还与经过精细调整的最先进LLMs的性能进行了比较,并分析了生成代码的正确性和质量。
本文的主要贡献如下:
使用广泛使用的CodeXGlue数据集评估ChatGPT在两个代码生成任务上的表现。提出提示设计和优化方法,通过提示工程引导ChatGPT生成更好的代码。发布复现工具,以便未来这一研究在社区中进行更深入探索。2 技术介绍
2.1 提示设计方法
ChatGPT常常对提示的设计敏感。为了增强提示,思考链(CoT)是关键策略,它通过引导一系列中间步骤使LLM解决问题,然后再给出最终答案。由于其有效性,CoT策略被广泛研究和应用。
通常,为了引导ChatGPT进行代码生成任务,我们设计了运用CoT策略的提示,并分为两步:1)提示描述,我们首先分析代码生成任务的需求,并以自然的方式设计一个基本提示。然后,我们提供基本提示给ChatGPT并询问“如何改进提示?”,根据ChatGPT的建议进一步改进提示。2)多步优化,我们在相关数据集的训练数据中选择一些样本测试第一步中的提示,根据结果分析生成性能,并通过向ChatGPT提供一系列新的提示来不断优化生成结果。
基于提示设计过程,我们生成了一些基线提示,并在测试数据上进行了评估。图1所示为提示设计和验证的概览。在提示设计和测试过程中,我们通过调用ChatGPT的API,使用默认设置(例如,使用GPT-3.5-Turbo模型)。

2.2 文本到代码的提示设计
提示描述。文本到代码(T2C)生成任务接受自然语言(NL)描述作为文本输入(例如,“将int转换为String”),并期望生成与描述意图相匹配的Java代码。根据任务描述,我们自然地提出了一个基本任务提示:“写一个Java方法,该方法+ #{NL}”(表I-P1)。为了评估提示的有效性,我们随机从训练数据中抽取100个实例,并要求ChatGPT根据提示生成代码。我们获得了较低的生成准确率,BLEU=5.29和CodeBLEU=22.76。
多步优化。使用表1中的提示模板,我们询问ChatGPT:“如何改进提示:写一个Java方法,该方法将int转换为字符串”。ChatGPT告诉我们,通过提供方法行为、编程上下文和输入/输出示例的更具体细节,我们可以创建一个更清晰、更具信息量的提示,帮助引导设计良好的Java方法的生成。我们注意到,数据集中提供的编程环境可以用作额外的上下文信息。因此,我们在任务提示前添加了一个上下文提示:“记住你有一个名为+ '#{CN}'的Java类,成员变量+ '#{MV}',成员函数+ '#{MF}'”(表I-P2)。在提示中,空白处#...将由数据集中给出的相应信息填充。注意,我们告诉ChatGPT记住这个类,因为如果我们不用清晰的指令引导ChatGPT,它将生成整个类。通过添加上下文提示,样本的准确率可以提高到BLEU=10.42和CodeBLEU=25.05。

在分析了ground-truth之后,我们观察到ground-truth在四个方面进行了预处理:1)移除了所有注释、抛出的异常和方法修饰符;2)方法名更改为“function”;3)所有的参数被重命名为“arg0”、“arg1”等;4)所有的局部变量被重命名为“loc0”、“loc1”等。根据这些观察,我们在任务提示之后添加了一个处理提示,包含一系列指令:“移除注释;移除摘要;移除抛出的异常;移除函数修饰符;将方法名更改为‘function’;将参数名更改为‘arg0’、‘arg1’...;将局部变量名更改为‘loc0’、‘loc1’...”(表I-P3)。注意,“移除注释”的提示不能移除部分代码片段生成的摘要,但是“移除摘要”可以。评估显示指标进一步改善到BLEU=13.11和CodeBLEU=36.00。
通过将生成的代码与ground-truth进行比较,我们注意到ChatGPT可能会生成具有不同API和异常处理设置的代码。自然地,我们会要求ChatGPT根据其响应和用户的具体需求重新生成代码。为了提取API和异常处理的需求,我们分别用提示“列出以下Java方法中仅使用的方法名称,去除多余解释:#{Code}”和“代码中包含异常处理吗?+ #{Code}”输入ChatGPT进行ground-truth的查询。之后,我们编写脚本来分析API和异常处理有无的需求。有了这两个需求,我们用行为提示替换任务提示:“写一个Java方法#{调用...},带[不带]异常处理来#{NL}”。我们发现,考虑到API需求,生成准确率可以得到提升(BLEU=22.14和CodeBLEU=44.18)。同时,使用完整的行为提示(即,API + 异常处理),性能可以进一步提升至BLEU=27.48和CodeBLEU=46.78。
2.3 代码到代码的提示设计
由于代码到代码(C2C)生成在提示设计的过程中与文本到代码(T2C)生成相似,我们在这一小节主要展示它们的关键区别。
提示描述。根据第III-B节的任务描述,我们的C2C生成任务旨在根据给定的C#代码函数生成Java代码方法。基于任务需求,我们形成任务提示:“将C#代码翻译成Java代码:#{Code}”(表I-P1)。对于从训练数据中随机选取的100个样本,生成性能为BLEU=9.76和CodeBLEU=39.37。
多步优化。与T2C生成相比,我们可以发现C2C生成任务中有许多不同之处:C2C数据集不涉及相关类;ChatGPT不会为代码生成注释和抛出异常;ground-truth没有对方法名称、修饰符、参数名称和局部变量名称进行预处理。然而,ChatGPT会根据C#代码生成注解,但ground-truth移除了所有注解。因此,我们在任务提示中添加了一个简单的处理提示:“不提供注解”(表I-P3)。此外,我们发现ChatGPT能够理解提示中的markdown语法。因此,在任务提示中,我们将#{Code}更改为”’#{Code}”’作为更新后的任务提示(表I-P4)。在处理提示后的样本上测试,生成准确率在CodeBLEU(45.28)上有所提高,但在BLEU(8.55)上没有提高。更新任务提示中的代码格式后,我们进一步提高指标到BLEU=15.44和CodeBLEU=45.00。
与T2C生成相同,我们从ground-truth中提取API使用和异常处理的需求。随后,我们将这些信息添加到任务提示中,作为行为提示:“将C#代码翻译成Java代码:”’#{Code}”’ #{调用...} 带[不带]异常处理”(表I-P5)。在样本上的实验结果显示,通过添加API使用(BLEU=13.37和CodeBLEU=46.17),生成准确率在CodeBLEU方面略有提高。此外,使用完整的行为提示也显示出BLEU的降低(8.90)和CodeBLEU的轻微增加(46.88)。我们观察到ChatGPT可以理解翻译上下文并生成良好的结果。但添加更多请求可能会给生成带来不确定性。因此,这种行为提示可能对C2C生成任务有负面影响。
3 实验评估
3.1 实验设置
研究问题
在本研究中,我们提出了一种引导ChatGPT进行两种代码生成任务的方法。为了验证该方法的有效性并分析相关影响因素,本研究调查了以下研究问题:
RQ1:为ChatGPT设计的提示有效性如何?
我们利用链式思考(CoT)策略手动为两种代码生成任务增强提示,并进行了多步优化。第一个RQ旨在评估设计的提示在相应测试数据集上的有效性,并验证我们的设计方法的有效性。
RQ2:简洁请求如何影响ChatGPT?
在提示设计中,我们观察到ChatGPT经常生成详细的代码,远比真实代码复杂得多。因此,多步优化的一个目标是引导ChatGPT使用一系列提示生成简洁的代码。值得进行研究的是,通过直接请求ChatGPT生成简洁代码是否可以进一步提高生成性能。
RQ3:会话设置如何影响ChatGPT?
在与ChatGPT交流时,我们为每个提示开始了一个单独的会话。同时,众所周知ChatGPT可以学习会话上下文并从上下文中生成更好的回应。因此,这个RQ旨在回答,通过输入到带有多个提示的会话,ChatGPT是否可以生成更好的代码。
RQ4:生成随机性如何影响ChatGPT?
众所周知,对于相同的提示,ChatGPT可能每次生成的代码都有细微差别。为了研究随机性如何影响生成性能,我们多次重新运行引导的ChatGPT并分析生成性能的稳定性。
RQ1提示设计的有效性
目标。为了评估设计的提示的有效性,我们提出一些基线,在相应代码生成任务的测试数据上测试它们,并就预测准确性方面分析有效性。
方法。本研究提出了三个基线,它们可以使用带有三种级别提示的ChatGPT生成代码:1) ChatGPT-task,我们使用表I(P1)中的任务提示作为ChatGPT的输入,因为它们可以代表具有直接代码生成请求的常见情况。2) ChatGPT-detail,我们合并了任务、上下文、处理和两个任务中更新的任务提示(表I P1-P4)。注意,T2C生成没有更新后的任务提示(P4),而C2C生成没有上下文提示(P2)。3) ChatGPT-behaviour,在ChatGPT-detail的基础上,我们进一步使用行为提示(表I-P5),以对代码生成提供更多指导。尽管上文说过,P5对于采样数据的C2C生成任务有负面影响,我们仍然为C2C生成设置了这个基线,以进一步确认之前的观察。
结果。在T2C生成任务上,表III显示ChatGPT-task的生成准确率为BLEU=5.63和CodeBLEU=28.05。对于ChatGPT-detail,带有一系列扩展提示的生成性能为BLEU=14.09和CodeBLEU=39.90,分别在BLEU和CodeBLEU方面超过ChatGPT-task 140.27%和42.25%。此外,最后的基线ChatGPT-behaviour在T2C生成上获得了更好的性能,BLEU=21.59和CodeBLEU=48.69。我们可以注意到,ChatGPT-behaviour在BLEU和CodeBLEU方面分别提高了ChatGPT-task的性能283.48%和73.58%。这些结果表明,我们设计的提示与设计方法可以显著改善ChatGPT的T2C生成。
就C2C生成任务而言,表III显示与T2C生成任务相比,ChatGPT-task可以获得更好的性能(BLEU=10.61和CodeBLEU=46.12)。此外,ChatGPT-detail显示出更好的生成准确率,BLEU=15.79和CodeBLEU=47.71,分别超过ChatGPT 48.82%和3.45%。然而,我们发现ChatGPT-behaviour表现较差,BLEU=9.47和CodeBLEU=47.38。因此,ChatGPT-detail的性能优于ChatGPT-behaviour。这些结果意味着对于C2C任务,设计的提示也可以改善ChatGPT的生成性能。

对RQ1的回答:我们的提示设计方法可以通过用更好的提示引导ChatGPT,显著提高T2C和C2C生成任务的性能。
RQ2简洁请求的影响
目标。在提示设计中,我们引导ChatGPT移除不相关的代码组件。然而,我们观察到生成的代码仍然比真实代码更复杂。如果没有更多信息,我们无法设计更好的提示。因此,这个研究问题旨在调查我们是否可以通过直接要求ChatGPT生成更简洁的代码,而不是手动添加特定指令,来改变任务提示。
方法。RQ1显示,ChatGPT-behaviour和ChatGPT-detail分别是T2C和C2C生成任务的最佳基线。对于向它们的提示中添加简洁性请求,我们找到了一种可行且简单的方法,即在生成目标之前添加单词“简洁”。具体来说,对于T2C生成,ChatGPT-behaviour的行为提示更改为“写一个简洁的Java方法...”(表I-P5)。同样地,对于C2C生成任务,ChatGPT-detail的任务提示更新为:“将C#代码翻译成简洁的Java代码...”(表I-P4)。为了评估简洁性请求的影响,我们在测试数据上测试了修改后的提示。
结果。对于T2C生成任务,表IV显示简洁请求是有帮助的,BLEU=26.86和CodeBLEU=50.18(ChatGPT-behaviour-C)。与RQ1中的最佳基线(ChatGPT-behaviour)相比,这两个评估指标分别进一步提高了24.41%和3.06%。同时,我们注意到,通过向C2C生成任务添加简洁性请求,虽然BLUE分数提高了6.08%,但ChatGPT-detail-C的生成性能在CodeBLEU(46.62)方面与RQ1中的最佳基线(ChatGPT-detail)相比有轻微下降。这些结果表明,简洁性请求对T2C生成有用,但对C2C生成没有用。

对RQ2的回答:向提示中添加简洁性请求可以进一步改善T2C生成的性能,但对C2C生成显示出轻微的负面影响。
RQ3 会话设置的影响
目标。默认情况下,我们为每个提示打开了一个单独的会话并与ChatGPT通信,通信可以在一个连续的会话中进行,该会话为一系列提示生成响应。通过这种方式,ChatGPT可以从上下文中学习,并可能为代码生成任务生成更好的响应。因此,这个研究问题旨在分析会话设置的效果。
方法。在与ChatGPT通信时,我们使用一个会话为一系列提示生成代码。当数量达到最大限制时,进一步的提示将不会收到响应。然后,我们开始另一个新会话。通过这种方式,我们可以确保每个会话被充分利用并且ChatGPT可以更好地理解上下文。我们知道,对于会话中较早的提示,上下文信息的量会较低。探究会话设置如何影响代码生成性能是值得关注的。
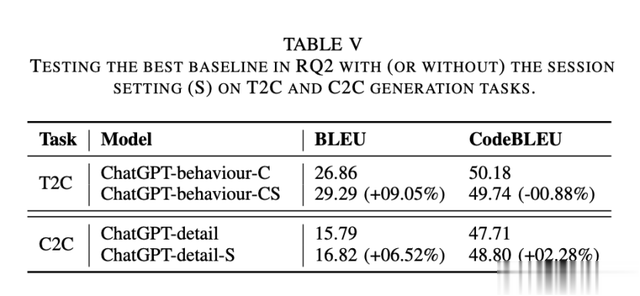
结果。如表V所示,使用连续会话(ChatGPT-behaviour-CS)对T2C生成没有显示出整体改善(BLEU=29.29和CodeBLEU=49.74)。与RQ2中的最佳基线(ChatGPT-behaviour-C)相比,BLEU分数提高了9.05%,但CodeBLEU下降了0.88%。而另一方面,连续会话对C2C生成任务(ChatGPT-detail-S)表现出改善,分别是BLEU=16.82和CodeBLEU=48.80。与RQ2中的最佳基线ChatGPT-detail相比,评估指标分别提高了6.52%和2.28%。这些实验结果表明,连续会话对C2C生成任务有益,但对T2C生成任务没有改善。因此,单独会话更适合T2C生成。
对RQ3的回答:连续会话对T2C生成任务有帮助,而C2C生成任务更适合单独会话。
RQ4生成随机性的影响
目标。通常,ChatGPT生成的回应会有轻微的差异。因此,生成的随机性可能会影响代码生成的性能。这个研究问题研究随机性如何影响设计提示的有效性。
方法。为了达到目标,我们分别对RQ3中的最佳基线(即,ChatGPT-behaviour-C和ChatGPT-detail-S)运行了五次。我们计算了这些多次生成结果的平均值(AVG)和标准差(STD)。基于这些测量,我们分析了生成的稳定性和随机性的影响。
结果。从表VI中,我们可以观察到,T2C生成的五轮结果显示出稳定的性能,其中BLEU从26.86到27.02变化,AVG =26.93,STD=0.08;CodeBLEU从50.07到50.20变化,AVG =50.16,STD=0.05。同时,C2C生成的多次运行也显示出稳定的预测准确性,其中BLEU从16.82到17.34变化,AVG =17.18,STD=0.21;CodeBLEU从48.80到49.17变化,AVG =48.86,STD=0.33。这些结果表明,使用我们设计的提示,ChatGPT将生成稳定的响应。我们观察到主要原因是提示中的指令是具体的,因此生成的随机性是有限的。由于随机性的影响可以忽略不计,我们没有用更多轮次的实验扩展这个研究问题。

对RQ4的回答:由于提示设计了具体指令,生成随机性对代码生成任务的影响很小。
转述:李昕