1. 导读
实时2D关键点检测在计算机视觉中起着重要的作用。尽管基于CNN和基于Transformer的方法已经取得了突破性的进展,但它们往往无法提供卓越的性能和实时速度。本文介绍了MamKPD,它是第一个用于2D关键点检测的高效且有效的基于mamba的姿态估计框架。传统的Mamba模块在补丁之间表现出有限的信息交互。为了解决这个问题,我们提出了一个轻量级上下文建模模块(CMM ),它使用深度方向的卷积来建模面片间的依赖关系,并使用线性层来提取每个面片内的姿态线索。随后,通过结合Mamba对所有面片进行全局建模,MamKPD有效地提取实例的姿态信息。我们在人类和动物姿态估计数据集上进行了大量的实验,以验证MamKPD的有效性。我们的MamKPD-L在COCO数据集上实现了77.3%的AP,在NVIDIA GTX 4090 GPU上实现了1492 FPS。此外,MamKPD在MPII数据集上取得了最先进的结果,在AP-10K数据集上取得了竞争结果,同时与ViTPose相比节省了85%的参数。
2. 引言
实时二维关键点检测要求模型以低延迟定位实例中的关键兴趣点,因能够为虚拟现实、动作评估及人机交互等下游任务提供纯粹的动作信息,而广泛应用于多个领域。尽管二维关键点检测取得了以基于卷积神经网络(CNN)和基于Transformer的关键点检测框架为例的突破性进展,但这些方法往往受限于网络规模,通常需要昂贵的计算资源。
众多研究试图通过压缩网络规模或采用轻量级网络架构来提高关键点检测的效率。网络压缩方法通常利用剪枝或用更高效的替代组件替换部分组件,以提高推理速度。而轻量级网络方法则使用更高效的骨干网络,如YOLO、EfficientNet,以提升推理效率。然而,大多数方法在提高效率的同时牺牲了检测精度。尽管一些方法减少了模型的参数,但其性能也大幅下降。这引发了一个具有挑战性的问题:如何在不牺牲精度的情况下提高模型效率?
最近,以Mamba为例的状态空间模型(SSMs)在保持高效率的同时,展现了卓越的序列建模能力。受Mamba在计算机视觉任务中成功应用的启发,本研究首次探索了Mamba在二维关键点检测中的潜力。然而,传统的Mamba块在更新状态时仅聚合图像块,这限制了其捕获上下文特征(块间依赖关系)的能力。上下文信息对于关键点检测至关重要,因为块之间的关系使模型能够学习实例的结构信息。
为解决上述问题,我们提出了一种新颖的二维关键点检测框架MamKPD,这是首个基于Mamba的二维关键点检测基线网络。此外,我们还引入了一个轻量级上下文建模模块(CMM),旨在增强块之间的通信。具体而言,MamKPD由一个主干网络、一个基于Mamba的编码器和一个简单的关键点解码器组成。在MamKPD中,我们首先使用一个简单的主干网络从输入中提取主要姿态特征,这有助于过滤掉不相关的噪声。接下来,采用一个三阶段的基于Mamba的编码器进一步提取姿态特征。在每个阶段,使用一个上下文建模模块来捕获块之间的依赖关系,随后使用二维选择性扫描(SS2D)模块来建模所有块之间的相互作用。最后,一个关键点解码器生成关键点热图。得益于其精简的架构,MamKPD有效地平衡了网络效率和准确性。我们在人体和动物姿态估计数据集上验证了MamKPD的有效性。实验结果表明,MamKPD在保持高效率的同时实现了具有竞争力的精度。
3. 效果展示
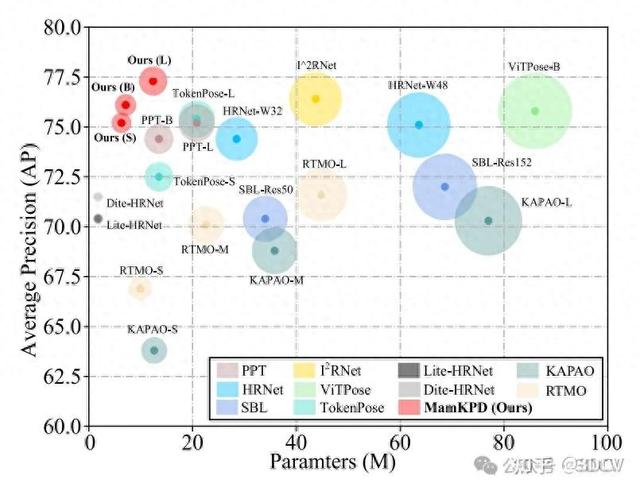
COCO val2017集上的性能和参数对比。圆圈的大小代表模型的比例,即模型参数的数量。
4. 主要贡献
本文的主要贡献概括如下:
• 我们提出了一种新颖且高效的二维关键点检测网络MamKPD,这是首个专为关键点检测任务设计的基于Mamba的架构。所提出的MamKPD在推理速度上超越了现有方法,同时保持了具有竞争力的关键点定位精度。
• 我们引入了一个简单的上下文建模模块(CMM),以增强原始的Mamba模块,从而提高其上下文特征建模能力。CMM模块与SS2D模块相结合,通过捕获块间和块内特征来提取丰富的姿态相关信息。推荐课程:
• MamKPD在人体和动物二维关键点检测数据集上取得了令人瞩目的结果,包括COCO、MPII和AP-10K数据集。在单个Nvidia 4090 GPU上,MamKPD的推理速度达到1492 FPS,关键点检测精度为77.3%,超越了现有的实时方法。
5. 方法
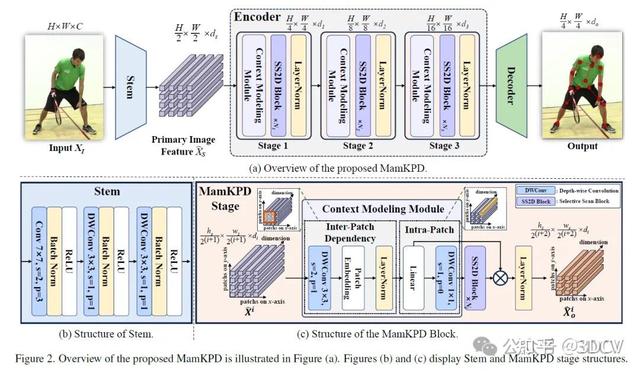
MamKPD的概述如图2所示。MamKPD由一个基于CNN的主干网络、一个基于Mamba的编码器和一个简单的解码器组成。给定输入图像。MamKPD旨在为图像中的每个人回归K个关节热图。
6. 实验结果
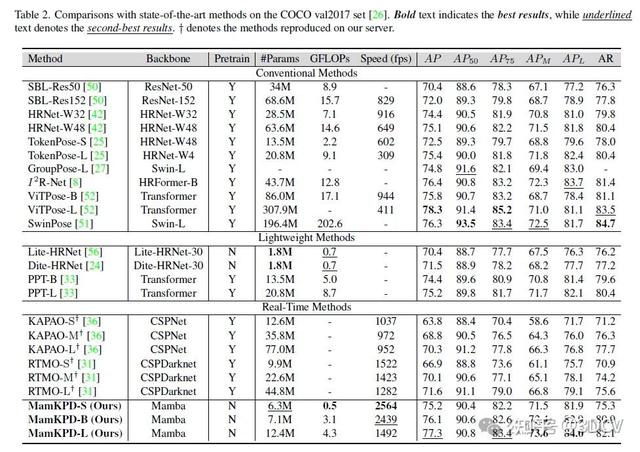
在COCO数据集上与现有方法的比较。表2展示了在COCO val2017数据集上的比较结果。在COCO val2017数据集上,MamKPD超越了Lite-HRNet和Dite-HRNet。MamKPD-S在与PPT性能相当的同时,参数数量减少了53.3%。此外,MamKPD-L在平均精度(AP)上比PPT-L高出2.1%,而参数数量却减少了约40%。尽管MamKPD-L在AP上比ViTPose低1%,但其所需的参数仅为ViTPose的4%。而且,MamKPDB仅以ViTPose-B参数数量的8.3%,就实现了超越ViTPose-B的性能。这些结果证明了MamKPD的有效性。
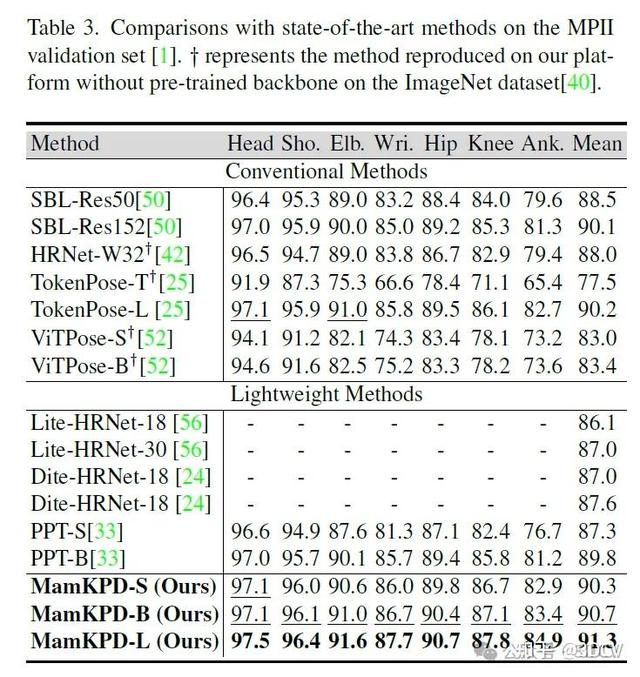
在MPII数据集上与现有方法的比较。表3展示了MamKPD在单人姿态估计数据集MPII[1]上与现有方法的比较结果。如表3所示,MamKPD-S的整体性能已经超越了现有方法。此外,MamKPD-L在每个关键点的定位上都取得了最佳结果,与先前方法相比,手腕和脚踝的定位精度有了显著提高。
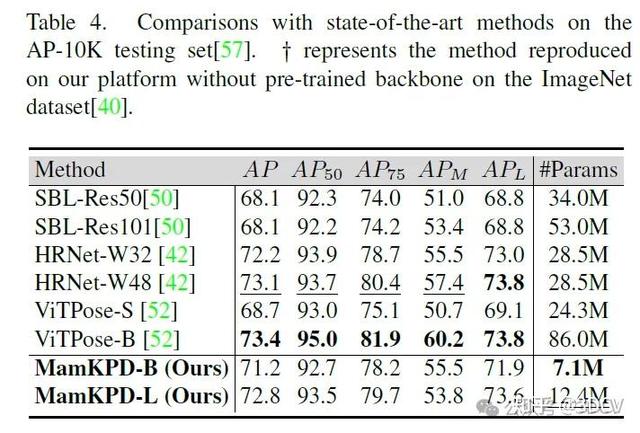
在AP-10K数据集上与现有方法的比较。我们使用AP-10K数据集[57]验证了MamKPD在动物姿态估计任务中的有效性,实验结果如表4所示。与基于卷积神经网络(CNN)和Transformer的方法相比,我们提出的MamKPD在保持轻量级的同时,实现了具有竞争力的性能。具体而言,与ViTPose-B相比,我们的方法在获得相似精度水平的同时,节省了约92%的模型参数,这表明我们提出的MamKPD对于动物二维关键点检测任务也同样有效。
7. 总结
本文提出了一种新颖且高效的二维关键点检测框架MamKPD,这是首次验证Mamba在二维关键点检测任务中的潜力。
我们引入了一个简单的上下文建模模块,以增强Mamba模块建模块间依赖性的能力。MamKPD在人类和动物姿态估计数据集上都取得了令人瞩目的结果。此外,MamKPD展现出了卓越的推理效率,MamKPD-L在单个4090 GPU上实现了超过1400帧每秒(FPS)的帧率,而MamKPD-B和MamKPD-S的帧率则超过了2400 FPS。我们希望所提出的算法及其开源实现能够满足工业应用中的一些实际需求。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~