短剧出海的翻译流程,卡在第一步的团队比想象中多得多。
原因很简单:大多数短剧在制作时没有留存独立的字幕文件。字幕是在后期剪辑时直接烧录进视频画面的——行话叫"硬字幕"或"内嵌字幕"。
这意味着你拿到的源文件是一个 MP4,字幕像素与画面图层融合,无独立可编辑文本轨道,没有任何结构化的文本数据可以直接拿去翻译。
要翻译,第一步必须解决:把字幕从视频帧里提取出来,还原成带时间轴的 SRT 文本文件。
这件事听起来简单,工程上并不轻松。视频是连续的图像序列,字幕区域只是画面的一小部分,背景可能是复杂的场景画面,字体样式因剧而异,还可能混有水印、台标、装饰文字。OCR 引擎需要在这些干扰项中准确定位字幕区域、识别文字内容、对齐时间轴,最终输出格式规范的 SRT 文件。
因此,基于 OCR 的视频帧字幕检测、识别与时间轴对齐,成为短剧出海自动化翻译的核心前置能力,NarratorAI 的字幕君(字幕提取 Agent)把这个过程拆解为 10 个步骤,每一步对应产品界面进度条上的一个阶段。下面逐步拆解。

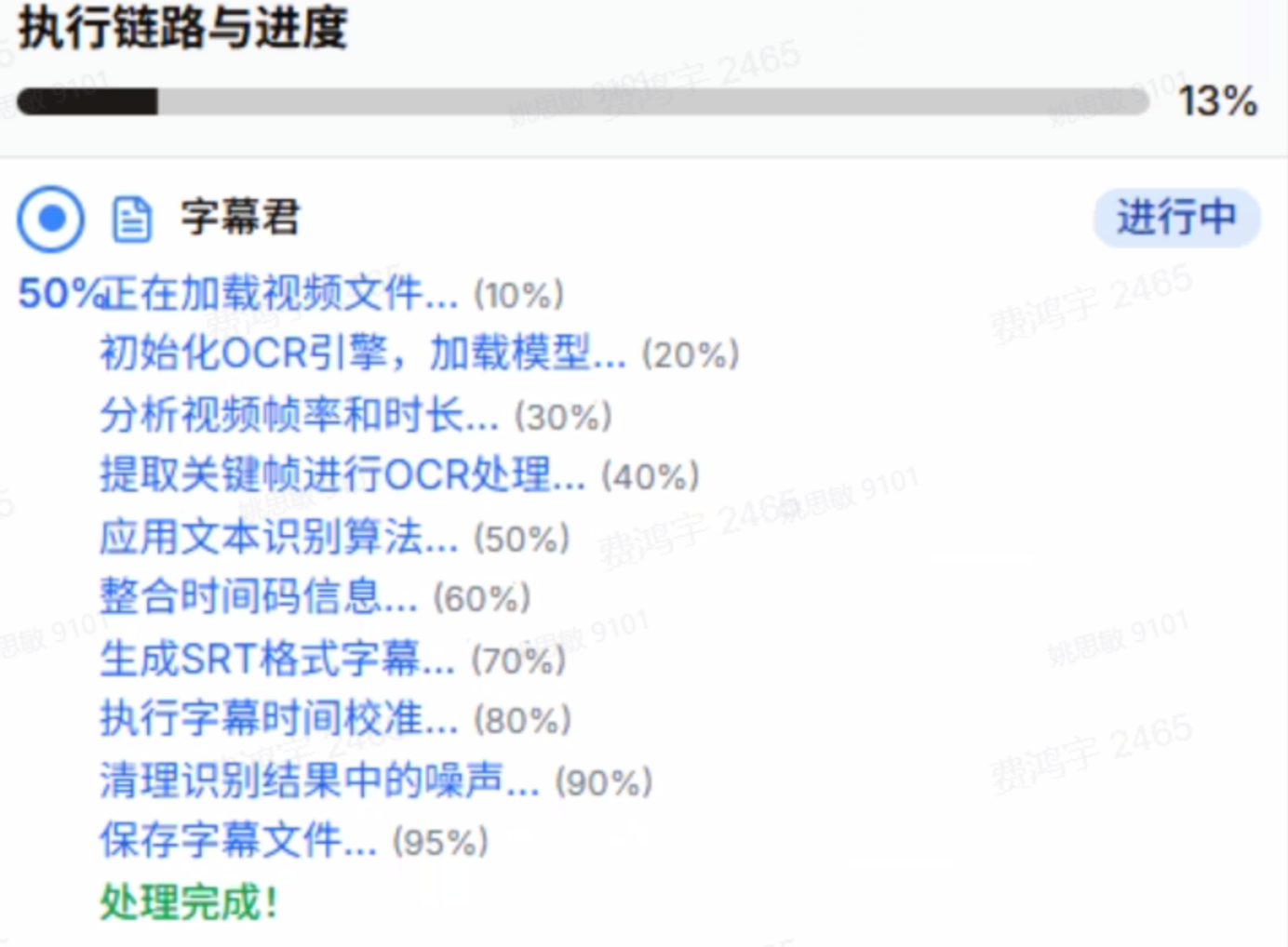
第一步是文件解析,不是 OCR。
系统需要读取视频文件的容器格式(MP4 的容器是 MPEG-4),解封装出视频流和音频流,获取基础元数据:分辨率、总帧数、编码格式(H.264/H.265)、色彩空间。
这一步的意义在于为后续处理建立参数基线。分辨率决定了字幕区域的像素坐标范围,编码格式决定了解码策略,总帧数决定了关键帧提取的采样密度。
暂不支持 MOV、AVI 等封装格式,聚焦短剧主流 MP4 场景。
Step 2|初始化OCR引擎,加载识别模型(进度 20%)OCR 引擎初始化包含两件事:加载文字检测模型和文字识别模型。
现代 OCR 系统通常是两阶段架构:
检测阶段:定位图像中的文字区域(输出文字框的坐标)
识别阶段:对检测到的文字区域进行字符识别(输出文字内容)
针对短剧字幕的特点,检测模型需要对画面底部区域有更高的敏感度(字幕通常在画面下方 1/4 区域),同时需要过滤掉画面其他区域的文字干扰(台标、水印、场景中的文字道具)。
Step 3|分析视频帧率和时长(进度 30%)这一步决定了后续关键帧提取的策略。
帧率(fps)是视频每秒包含的图像帧数,常见值是 24fps、25fps、30fps。单集 30 分钟短剧总时长 1800 秒,24fps 下总帧数可达 43200 帧,逐帧 OCR 算力消耗极大,而且完全没有必要——字幕在相邻帧之间几乎不变,一条字幕通常持续 1-4 秒,也就是 24-96 帧显示的是同一段文字。
分析帧率和时长的目的,是为关键帧提取建立采样参数:以什么频率采样,才能在不遗漏任何字幕的前提下,把计算量压到最低?
Step 4|提取关键帧,执行OCR处理(进度 40%)关键帧提取是整个链路里计算量最集中的环节。
策略上,系统不是按固定时间间隔均匀采样,而是通过帧差检测(基于字幕固定底部 ROI 感兴趣区域做像素差分计算,缩小检测范围、降低算力。)来识别字幕切换时机:当相邻帧之间的字幕区域像素差异超过阈值,说明字幕发生了切换,这一帧就是关键帧。
这个策略的优势是自适应:对话密集的场景(字幕切换频繁)会提取更多关键帧,静场或纯音乐段落(无字幕)会跳过大量帧,整体计算量和字幕密度成正比,而不是和视频时长成正比。
对每一个关键帧,OCR 引擎执行检测+识别两阶段处理,输出该帧的字幕文字内容和对应的帧编号。
Step 5|应用文字识别算法(进度 50%)文字识别阶段的核心挑战是字幕样式的多样性。
不同短剧的字幕字体、字号、颜色、描边样式各不相同。有的字幕是白字黑边,有的是黄字无边,有的字幕区域有半透明背景条,有的直接叠在复杂背景上。识别模型需要在这些变化中保持稳定的识别精度。
另一个挑战是中文字符的密度。中文字幕每行通常包含 10-20 个汉字,字符间距小,在低分辨率视频中相邻字符容易粘连,影响识别准确率。
这一步的输出是每个关键帧对应的原始识别文本,还没有时间信息,是纯文字序列。
Step 6|整合时间码信息(进度 60%)把"文字"和"时间"对应起来,是这一步的核心工作。
每个关键帧有一个帧编号,通过帧编号和帧率可以计算出精确的时间戳:
时间戳(秒)= 帧编号 / 帧率
但 SRT 格式需要的不是单个时间点,而是一个时间区间:开始时间 --> 结束时间。
系统通过分析连续关键帧的文字内容来确定时间区间:当某段文字在连续帧中保持不变,说明这条字幕从第一帧开始,到最后一帧结束。一旦文字内容发生变化(下一条字幕出现),前一条字幕的结束时间就确定了。
仅依靠单帧编号只能得到单点时间,系统通过连续关键帧文本相似度匹配,自动切分字幕起止区间。
Step 7|生成SRT格式字幕文件(进度 70%)SRT 是最通用的字幕格式,结构非常简单:
1
00:00:03,240 --> 00:00:05,800
你这个负心汉
2
00:00:06,120 --> 00:00:09,440
当初说好白头偕老的
每条字幕包含三个元素:序号、时间区间、文字内容。这一步把前面整合好的时间码和文字内容按 SRT 规范格式化输出,生成初始字幕文件。
这个初始文件是"毛坯",还需要经过后续两步的校准和清理才能使用。
Step 8|执行字幕时间轴校准(进度 80%)时间轴校准解决的是时间精度问题。
帧差检测确定的字幕切换时机,精度是帧级别(1/24 秒或 1/30 秒)。但实际上字幕的出现和消失往往发生在两帧之间,帧差检测会有半帧左右的误差。对于语速快的对话场景,这个误差会导致字幕和口型轻微错位。
校准步骤通过分析音频波形(语音起止时间)和字幕时间码的对应关系,对时间轴做微调,把误差控制在可接受范围内。
Step 9|清理识别结果中的噪声字符(进度 90%)OCR 识别结果里经常混入不属于字幕的文字:
台标:电视台或平台的 Logo 文字,通常固定在画面角落
水印:制作公司或版权信息
场景文字:剧情中出现的道具文字(书信、招牌、手机屏幕)
识别错误:把背景纹理误识别为文字字符
噪声清理通过几个规则过滤:固定位置出现的文字(台标通常在固定坐标)、出现频率异常高的文字(水印在每帧都出现)、字符长度异常短的识别结果(单个字符通常是误识别)。
Step 10|保存字幕文件,处理完成(进度 100%)清理后的字幕文件保存为标准 SRT 格式,进入下一个 Agent(本土文化君)的处理队列。
如果是手动确认模式(auto_run=0),流程在这里暂停,等待用户在线校对。
整套链路采用「 ROI 局部检测 + 动态关键帧采样 + 音频联动校准 + 规则化降噪」组合方案,兼顾识别精度与算力成本,更适配短剧批量、高频、低成本的出海生产场景。
三、提取完为什么还需要人工校对?OCR 提取的准确率在理想条件下可以达到 95% 以上,但"理想条件"在短剧场景里并不总是成立。
以下几种情况会显著降低识别准确率:
低分辨率源文件。 很多短剧的源文件是 720p 甚至更低,字幕区域的像素密度不足,细小笔画容易粘连或断裂。"己"和"已"、"末"和"未"这类形近字在低分辨率下极难区分。
复杂背景叠加。 字幕叠在快速运动的场景画面上时,背景像素的变化会干扰字幕区域的检测,导致部分帧的字幕被漏提取。
特殊字体。 部分短剧使用艺术字体或手写体字幕,这类字体和 OCR 模型的训练数据分布差异较大,识别错误率明显上升。
语速极快的对话。 每条字幕显示时间不足 0.5 秒时,关键帧提取可能遗漏这条字幕。
这些情况下,5% 的识别错误率意味着一部 100 集短剧里可能有数百条字幕存在问题。如果不经过人工校对直接进入翻译流程,错误会被翻译放大——原文识别错了,译文也会跟着错,而且译文错误更难被发现。

这是手动确认模式存在的核心理由:给专业用户一个在错误扩散之前介入的机会。
四、全自动模式 vs 手动确认模式两种模式通过 auto_run 参数控制,适用场景有明确区分:
维度全自动模式(auto_run=1)手动确认模式(auto_run=0)适用场景源文件质量高、字幕清晰、批量处理低分辨率源文件、艺术字体、高质量要求处理速度快,全程无需人工介入慢,需在关键节点人工审核质量控制依赖模型精度人工兜底,可修正识别错误适合团队追求效率的批量出海团队对翻译质量有严格要求的精品内容团队介入节点无字幕提取后、本土化清单生成后、翻译结果生成后手动确认模式下,用户可以在产品界面的字幕在线编辑器里直接修改 OCR 提取结果:修正识别错误的字符、调整时间轴、删除噪声条目。编辑完成后点击确认,任务继续流转到本土文化君。
五、独立调用字幕提取功能完整开源代码:https://github.com/Narrator-AI/NarratorAI

字幕提取不必绑定完整翻译流程,可以作为独立工具单独调用。适用场景:只需要提取字幕做内容归档、字幕文件用于其他用途、先提取后手动翻译。
import requestsAPI_BASE = "https://openapi.jieshuo.cn"HEADERS = {"Content-Type": "application/json", "APP-KEY": "your_api_key"}
仅提取字幕,不触发翻译流程response = requests.post( f"{API_BASE}/api/narrator/ai/v1/tasks/extract-subtitle", headers=HEADERS, json={ "task_type": "video_extraction", "auto_run": 1, "resources": {"file_set_name": "你的项目名称"} })task_id = response.json()["data"]["id"]print(f"提取任务已创建:{task_id}")查询提取结果:import timewhile True: status = requests.get( f"{API_BASE}/api/narrator/ai/v1/tasks/{task_id}", headers=HEADERS ).json() if status["data"]["status"] in [2, 9]: print("字幕提取完成,可下载 SRT 文件") break print(f"处理中,当前状态:{status['data']['status']}") time.sleep(10)
修改OCR提取的字幕内容requests.post( f"{API_BASE}/api/narrator/ai/v1/videoTasks/update/{srt_id}/originSrt/content", headers=HEADERS, json={"content": "修正后的字幕内容"})确认继续,进入本土化处理阶段(操作不可逆)requests.post( f"{API_BASE}/api/narrator/ai/v1/confirm/task/flow/{task_id}", headers=HEADERS)