
从我们最熟悉的城市十字路口场景说起。
于是,坐在监控中心的工作人员,通过视频孪生大屏,可以清晰、直观地看到道路上的车水马龙,看到两侧显示当前车流量的统计图表,也能及时处理系统检测到的各种报警事件。
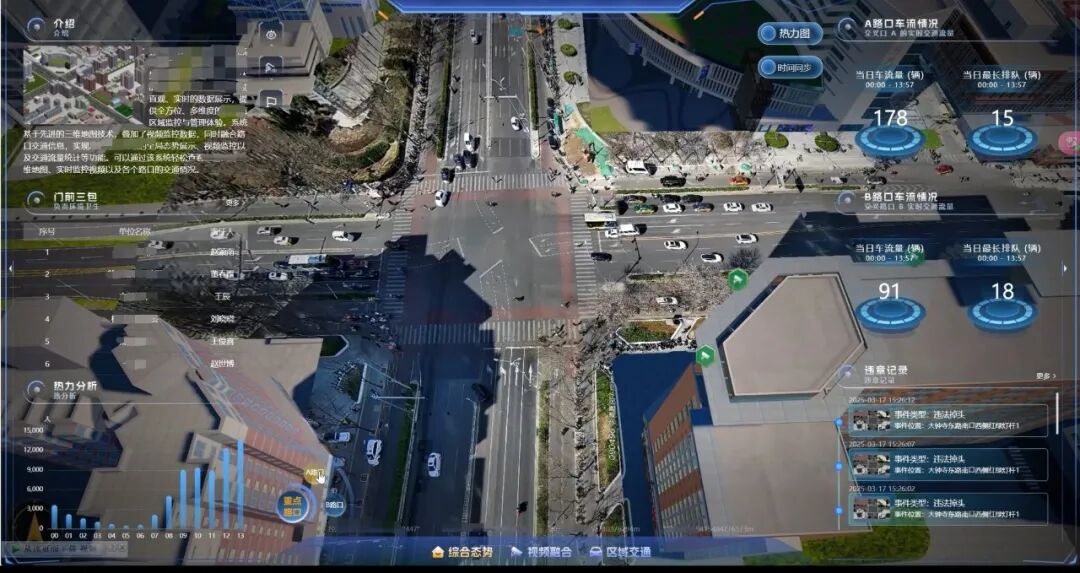
而在空间语义的世界里,同样是这个十字路口,系统似乎已经“懂得”了场景,并能做出精准地分析和预测:
从"看见"白色轿车,到"懂得"这辆车正以32km/h的速度从西向东经过十字路口,这不仅是功能的升级,更是哲学意义上的跃迁——数字世界从被动的"镜像空间"进化为主动的"认知主体"。
技术虫洞:视空映射链接2D与3D世界长久以来,2D视频与3D空间就像两个互不相通的平行宇宙。视频AI能识别出“画面中有一辆车”,却不知道“车在哪里,车辆行驶的方向、速度”;基于3D GIS的孪生引擎知道每一个精准的坐标,却看不懂视频画面,不知道什么是车。
打破了这层壁垒。它通过于是,视频画面中的车辆不再是屏幕上的一堆RGB颜色值,而是一个个可以被换算为(X, Y, Z, 航向, 速度)的空间对象。这不仅是几何变换,更是维度的跃迁:
对2D AI而言:视空映射提供了一个"像素→世界坐标"的反馈通道,让2D感知结果能在3D空间中被验证、关联、追踪。
对3D场景而言:视频流不再是可视化的纹理贴图,而变成了实时更新的空间数据源。
视空映射作为核心枢纽,让成熟的2D AI基础模型(如SAM、Depth Anything、YOLO)得以在3D空间中发挥威力。视空映射技术其实是智汇云舟长期以来一直在沉淀的技术,但直到今天,它的价值才被真正放大,这要归功于3D高斯泼溅(3DGS)的出现。当视空映射遇见3DGS,魔法才真正开始。
不同于传统手工建模用的三角网格,3DGS的最小单元不是一个“面”,而是一个“点”。数学上,这意味着3DGS是连续可微分的。这种特性加上视空映射技术,让3DGS的自动语义化成为可能。
如果说传统的基于MESH网格的模型是“给人看”的,那么3DGS可以说是第一个“为AI看懂”而生的模型格式。当3D场景的每个几何单元都可被AI理解、可被算法优化、可被语义标注时,智能就不再是附加功能,而是一种与生俱来的属性。所以,当数字世界学会"格物致知",人们认识和管理物理世界的方式,便永远改变了。