导读 今天分享的主题是:AI 饮食管家:让叮咚“买菜更简单、吃得更健康”。主要内容是 Agentic AI 在叮咚买菜的实践。整体来说,叮咚买菜在 AI 的应用的范围主要有三部分:1、供应链,从供应链的需求、库存、供应商管理,到物流、履约,直到消费者端的整个供应链;2、消费者侧,主要为 APP 端功能和体验;3、内部运营提效。这次分享主要侧重在消费者侧,其他部分简要带过。
今天的介绍会围绕下面六点展开:
1. Agentic AI 的基础-全链路数字化
2. 叮咚买菜 App 变了
3. 对话式AI
4. 个性化推荐
5. 运营提效(案例)
6. Q&A
分享嘉宾|周祥军博士 叮咚买菜 技术副总裁
编辑整理|Yuxiao
内容校对|郭慧敏
出品社区|DataFun
01
Agentic AI 的基础-全链路数字化

从商业模式层面分析,叮咚买菜采用前置仓模式。自 2023 年起,该模式的运行效率实现显著提升,基于这一优势,众多采用前置仓模式的生鲜零售企业也加快了在各城市的布局进程。
叮咚买菜的业务流程
在供应侧,传统供应端占主要部分的是品牌商和代理商,例如光明、蒙牛等,而在叮咚买菜,自有生产和农场基地采购占比较高。叮咚买菜的业务流程主要由三部分组成:源头供应、城市大仓和前置仓。源头供应的货物从全国各地采购,通过主干物流运至城市大仓。城市大仓进行统一的分拣、标准化、重新包装以及商品品质分级(部分商品品质分级在源头完成,例如西红柿等)。城市大仓分拣后,货物会在半天甚至更短的时间配送至对应的前置仓。叮咚买菜目前主要采用线上前置仓模式(只有极少前置仓支持自提),配送范围一般为三公里内的覆盖用户。
在全链路运营流程中,每个环节均设置了品控要求。采购环节前,已明确制定采购品控标准;货物采购完成后,在城市大仓节点,入仓与出仓环节分别执行对应的检验标准。从基地到大仓再到前置仓,都会再次进行校验,只是每层校验的侧重点不同。即便从城市大仓出仓到前置仓的校验,尽管该环节是由叮咚买菜自身操作,但也不会完全信任交付,也需要进行再次校验。每个环节都可能存在不符合标准被打回的情况。直至用户在 APP 下单,我们将商品送至用户手中。在经历了以上的环节后,用户购买的任何商品批次有问题,我们都能重新追溯,追查到底是链路中的哪个环节出了问题。这便是叮咚买菜对外宣称的7+1品控体系。
从采购基地方面,叮咚买菜有自己的生产标准,包括发布的 D-G.A.P 标准,这些标准都属于行业较高的品控标准。从基地到大仓,再到前置仓,叮咚买菜实现了所有产品和批次的数字化操作及溯源。
02
叮咚买菜 App 变了
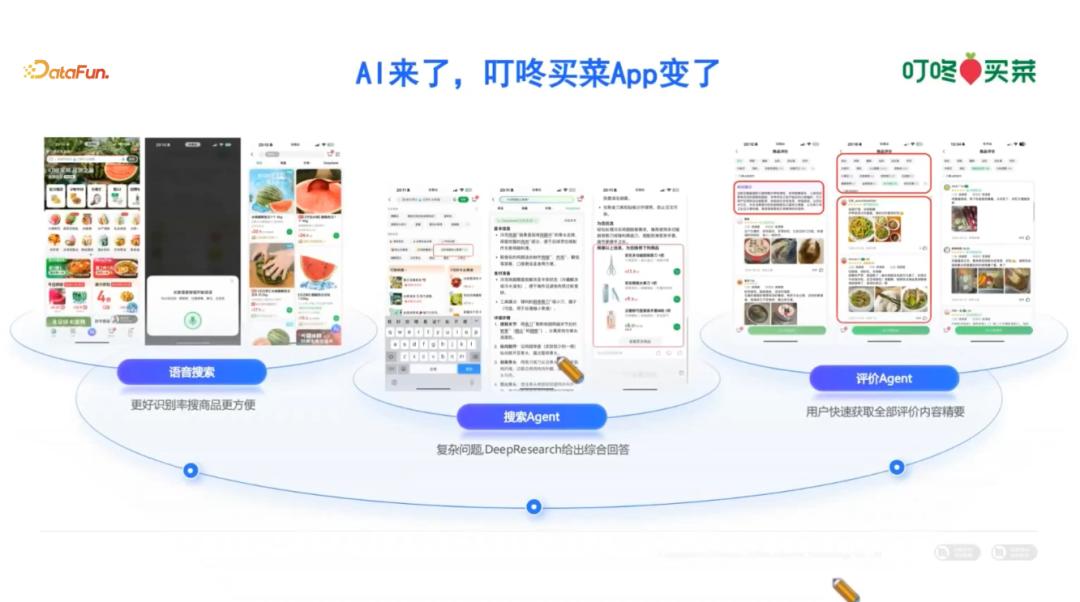
1. 语音搜索
2025 年上半年,叮咚买菜 App 集成大模型能力,推出新一代语音搜索功能。此前版本的语音搜索采用语音识别(ASR)技术,其核心流程为‘语音转文本→文本搜索’。而基于大模型后,语音搜索功能切换到了多模态解决方案这,不仅识别准确率有了更大提升,还能解决更多输入有困难的用户的需求,例如普通话不标准,发音有困难等用户。
2. 搜索Agent
在用户有了语音搜索功能后,搜索的 Query 会潜移默化地发生变化。这也是大模型发展后,交互方式可能发生的变化。以前更多是基于关键词的搜索,现在 Query 可能涉及较长的语音描述,很多时候用户语音搜索的不是关键词,而问的是一个解决方案,例如询问平台上蛋白质含量最高的鲜奶有哪些,这个问题是非常复杂的。目前叮咚买菜采用的方案是 Deep Research 框架,用于解决这一问题。
3. 评价Agent
在商品评论板块,叮咚买菜针对 AI 应用进行了两项优化升级。其一,新增自助式评论生成功能,为用户提供评论创作辅助;其二,基于用户真实评论数据,实现评论内容的页面化智能总结。叮咚商品不论好差评均是全部放出的,所以用户的评论是全部对外公开透明。基于此,大模型生成的评论摘要能迅速公正地总结出商品的特点,包括商品的优点和缺点。
03
对话式 AI

1. AI 饮食管家
叮咚买菜在 App 首屏入口增设 AI 对话入口,核心目标是推动 App 从单一的买菜购物工具平台,向具备多元化服务能力的用户生活助手转型,充分发挥平台在饮食相关服务领域的差异化优势。
现在在淘宝闪购、京东到家、饿了么、美团等平台,用户在这些平台上也能购买叮咚买菜的商品,相当于叮咚买菜的店铺或商家入驻。如果只是作为工具平台,很多途径都能实现买菜购物。但我们希望成为用户生活上的便利助手,而不仅仅限于买菜。从用户日志和搜索查询中,我们发现用户除了购买商品外,还关心很多其他方面,例如一些新奇商品的性质等。前段时间叮咚买菜推出的小葫芦,有用户在小红书上询问如何食用,实际上它只是一个把玩物品。此外,用户还关心购买后的使用方式,以及根据自身人群特点选择商品,如养胃食品或针对过敏情况的食品推荐等。同时,叮咚买菜也想解决一些搭配问题,例如用户购买菜品后可能还缺某些食材才能烹饪,我们会给出建议。此外,还包括烹饪方法的提供。另外,有很大一部分用户诉求是对商品有效期的提醒,例如,鲜奶的保质期有多种,如 28 天、14 天、7 天甚至 3 天,用户通常不需要自己记住所有有效期,基于我们的ERP系统与供应链数据库,平台可实时获取商品批次、生产日期及保质期等元数据。我们即将上线的效期提醒功能,可以自动提醒用户所购买的商品何时过期。
2. 多模态识别
当前,多款聚焦健康、运动及饮食领域的应用均具备相似功能,主要包括卡路里测算、营养元素识别及日常饮食拍照记录等。叮咚买菜在饮食 AI 领域的核心竞争力,源于‘技术能力 + 数据壁垒’的双重支撑:技术层面,通过大模型多模态能力实现拍照识别营养元素的功能落地;数据层面,凭借自营商品模式构建了独家且完整的商品知识库,其中包含商品营养元素、具体配方、脂肪与蛋白质含量,以及钾、钙等微量元素的精准数据,这些独有数据为 RAG 技术的高效应用奠定了基础,形成差异化优势。另外我们还有完整的供应链全链路数据,例如商品的批次,生产日期,保质期等,因此平台可以准确知道用户购买的商品的生产日期等信息。将这两者与拍照功能结合,叮咚买菜便可以提供更准确的商品信息和回答用户问题。

关于对话 AI,叮咚买菜内部产品叫叮小咚,其 AI 入口在 App 的首屏底部 C 位最中间的位置。做叮小咚的主要原因是希望逐步将购物工具转变为生活助手的角色,因此对应的架构也是一步一步计划来进行的。
在 Agent 的架构中,输入支持文字、语音和图片,暂不支持视频,但后续随着基础能力的发展,可能也会接入视频,实现多模态输入。输入进入后,会经过一个意图识别模块,这个模块是一个小型的开源模型。由于对性能要求较高,需要根据意图识别来决定后续 Agent 的调用。例如,如果涉及到商品搜索,对性能是有要求的,所以使用自己部署的模型并结合在线调用。中间的每个功能其实都是一个独立的 Agent。例如菜谱,叮咚买菜有一个专门的团队负责,包括自己生产的菜谱和 AI 生成的菜谱。如果模块发现用户在问菜谱,就会调用菜谱的 Agent。此外,还有一个比较独立且较大的售后客服 Agent 模块,叮咚买菜的客服系统其实是一个完整的系统。
在 RAG 部分主要是商品知识。用户会问促销相关信息、评价总结等。叮咚买菜接入的行业知识大模型会带一些相关的知识,但像专业的知识库,例如国家发布的膳食指南、药食同源等专业知识,也需要团队自己整理进来,作为知识增强的一部分。
在 Memory 部分,由于 AI 助手的核心是让用户感觉到其是独一无二的,是为用户自己定制的,因此 AI 助手不仅仅需要知道用户的偏好,还需要知道用户的记忆。例如用户之前说过什么,以及最近关心什么等。如果用户之前提到对乳糖不耐受,那用户在买鲜奶时,AI 助手会尽量推荐像燕麦奶这样的产品。这些信息系统是需要长期记住的,但有些可能是短期的,例如用户最近上火,这时 AI 助手会尽量不要推荐重口味辣的食物,但用户偏好也可能是喜欢吃川菜,这相当于是在记忆模块中,需要考虑在何种上下文后提取相应的信息。叮咚买菜在记忆模块投入较多,将其视为大型工程系统处理,包括短期记忆的实时记录,如用采用Redis实现低延迟的短期记忆缓存,部分信息需要进入第二层到 MySQL。在长期记忆中,需要通过用户行为埋点与 NLP 技术,构建包含饮食偏好、过敏原、消费频次的多维画像。在 Memory 部分主要是围绕短期记忆、长期记忆和用户画像来做记忆体。
关于工具集,由于叮咚买菜是前置仓,在用户对话时是知道用户所属的前置仓的位置,如杭州、上海、北京或深圳,以及用户的收货地址是在家还是办公区。这使得在聊天时,系统知道应该提供哪些更丰富的上下文,包括用户当时的所处的天气情况等。
关于底座,叮咚买菜主要基于千问,部分使用 DeepSeek,如在 AI 搜索部分。从 2024 年底,叮咚买菜前后经历了文心一言、百川、智谱、豆包等。叮咚买菜另有平台可任意切换底座模型,每个切换都有自动评测集来对模型进行评测。
04
个性化推荐

在 2024 年前,叮咚买菜主要模型框架是基于用户的行为做推荐,使用的是深度模型框架。从双塔结构转换到 DIN 再到 SIM。这存在着冷启动的问题。另外,跨类目推荐困难的问题,因为用户行为的 ID 型数据难以泛化,例如用户买了蔬菜、咖啡后,难以推广鲜花等新的品类,基于用户行为是无法推断用户是否喜欢鲜花新品的,但大模型天然具备相关能力。大模型本身会携带知识性内容,例如,喜欢咖啡的用户可能偏年轻化,他们可能喜欢鲜花,这是从大模型中得出的。此外,大模型还具备推理能力。例如,大模型能基于行为判断两个人可能的某种关联。例如,之前遇到用户要求推荐下酒菜,基于 query,通常需要在商品标题、标签或类目中寻找。这需要为商品打标,并根据用户的 query 与商品进行相似性匹配才能得出结论。若没有对商品打对应标识,是无法获取结果的。但大模型能轻易获取部分知识,例如,一般用户认为酒鬼花生、卤菜等下酒菜很下酒。这些知识属于人的常识,之前会通过网络抓取并自行挖掘,然后打标到商品上,但工作量极大。因此,许多公司都有标注团队,而我们则缺乏这部分人员,于是考虑如何通过技术解决。现在,大模型在这方面表现出色,效率高且质量更好。因此,叮咚买菜现在将行为与知识结合,用于整个搜推建模。而在召回方面,之前下酒菜的例子,在做 rag 的召回是非常有利的。此外,在排序方面,叮咚买菜也在采用生成式排序。原来基于 CTR 预估进行排序,例如预测用户和商品的点击率,但存在缺陷,即无法知道单个结果的点击率是否会让整体的点击情况更合理。现在,大模型的生成式推荐在抛开效率的情况下,其性能已经得到验证。团队现在更多关注其在用户体验上的效果和性能的优化。
05
运营提效(案例)
1. 商品运营
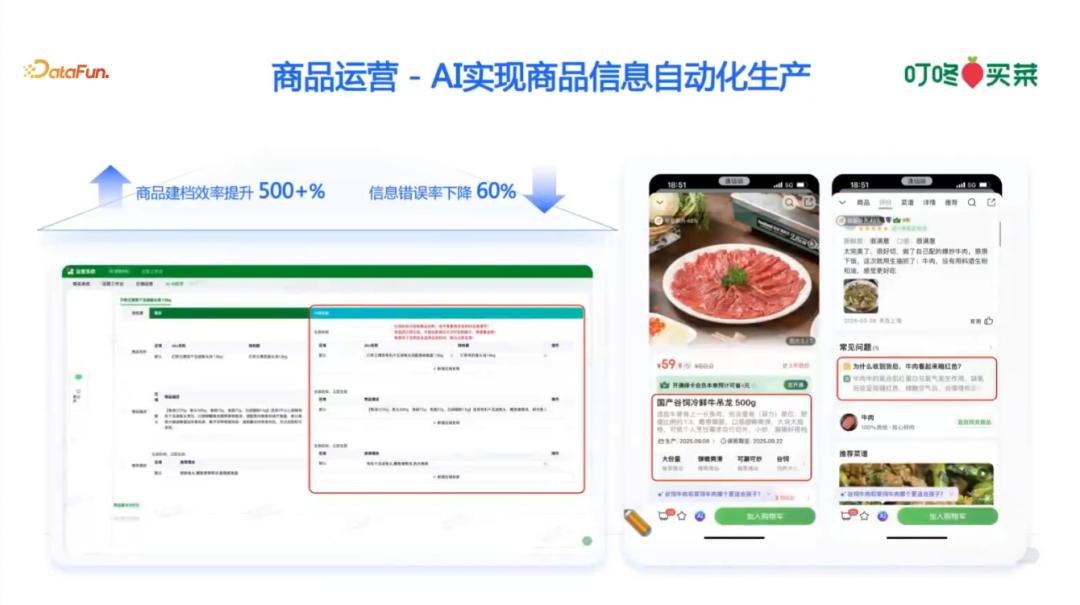
由于叮咚买菜的商品全部是上架自营平台,因此商品上架需经过复杂的商品上架信息录入系统。这些信息包括图片、视频、文本等,有的由供应商提供,有的由叮咚买菜员工自行整理。最终,这些信息需转化为结构化知识。之前,这项工作由人负责,工作量大且常出错。例如,曾出现将山药的长度从 20 多厘米误录为 20 多米的错误。尽管有规则可遵循,但仍会有意想不到的错误,这些错误无法全部罗列。在使用大模型后,系统能自动识别并录入信息,显著提高了效率和准确性,降低了错误率。通过对大模型的使用,叮咚买菜在商品结构信息化方面取得了很大收益。
2. 活动运营
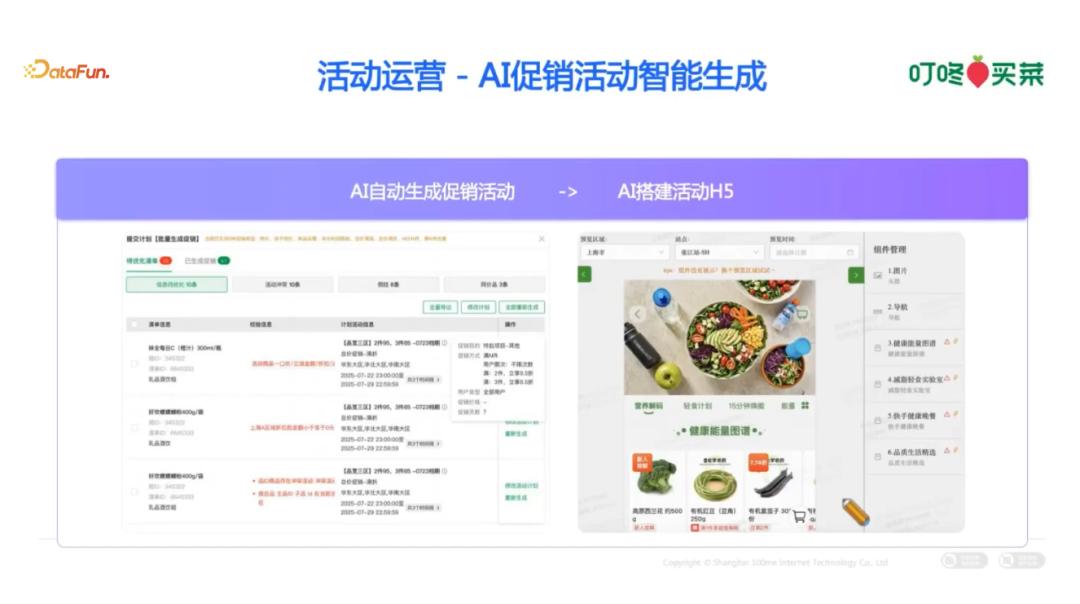
在促销活动搭建环节,从商品选品、折扣策略制定、活动 H5 页面自动生成到商家扣点核算等全流程,均已实现前端页面生成的自动化操作。这样,运营人员只需决定折扣力度和活动量,甚至后续这些决策也可以交给 AI 来完成,运营人员只需向 AI 提供的活动目标和上下文信息,即可实现自动化生成。
3. 客户服务
在客户服务方面,叮咚买菜的特色之处在于 VoC 方面。叮咚买菜从用户进线、用户退款、外部(微博、小红书、抖音等)投诉中提取信息,进行自动提取归类,判断是商品问题、服务问题还是其他问题,并定位到具体产品。这项工作每日都在进行,使团队能够持续关注每个品类的 VoC 变化,随时了解品类及具体产品的问题。此前,我们依靠人工打标和算法模型拟合来提高准确率,现在完全依靠大模型进行自动打标。打标完成后,判断规则由大模型执行,最后再进行人工抽样,例如针对系统判断出的异常 case 或执行度较低的 case,会进行少量人工打标。整个系统目前完全自动化运行,这对很多方面都有较大收益。
06
Q&A
Q1:请问意图识别部分是使用什么模型?
A1:意图识别模块部署了两套模型服务:一套为大模型蒸馏后的轻量化模型,另一套为基于传统自然语言处理(NLP)技术构建的基础模型。目前线上使用的是自己部署的千问 32B 的蒸馏模型。如果大模型性能有问题,自动降级到基础模型。
Q2:想问一下老师,有没有针对个人偏好和特殊体质做一些推荐的参考变量?
A2:我们的基座模型没有重新训练,更多是在上层处理。在记忆模块,原本就有用户的 profile,即用户本身的画像和基本用户信息。而在整个对话中,也会把对话信息提炼并蒸馏,以此来做推荐。针对大模型本身的参数调整方面,我们暂时还没涉及。
Q3:为什么考虑的是千问 32B 的模型,是速度方面的考量吗?
A3:对,32b 在速度和质量上相对性价比很高,我们的应用域非常聚焦,主要是用户的 query,且这些 query 基本围绕叮咚买菜。其质量相较于线上直接调用,准确率差别非常小,相对来说性比很高。另外,性能很好,可以做到秒以内响应。这并非小流量测试,而是线上版本 app 的全流量。顺便提一下,由于现在这个应用还有很多功能还在分流测试,也没有推广,所以渗透率目前还不高,AI 搜的并发不高,还没有明显的性能瓶颈。
Q4:产品上线后,如何定义效果指标?
A4:产品上线后,效果指标的定义可能因阶段而异,这里只能分享一下我们的情况。首先我们虽然身处电商平台,但并非以 GMV 为目标。目前首要关注的是用户的日活,相当于把它当作内容产品来做,看用户是否愿意使用。其次是复访率,即用户除了日活外,是否还愿意再次使用。第三个是互动次数,即单次会话中用户主动与我们互动的次数。这是我们整个团队在当前的目标中关注的最重要三个指标。
Q5:我之前是内容行业从业者,曾做过食谱项目。当时有些用户会针对身体的小病因进行询问,由于我们无医学背景,所以无法回答。请问叮咚买菜目前是否出现类似场景?例如,用户说最近失眠,询问能否推荐食物或饭菜以缓解失眠情况。
A5:基本上是可以的,因为我们的基模基本上能跟 Qwen、DeepSeek 以及豆包回答的质量对齐。你说的这种情况,我觉得分两类。一类涉及医学,AI 的回答还不具备权威性,因为需要非常严谨的医学资质对齐。但关于药食同源相关的食谱的问题,回答还是比较在线的。对于用户询问如何调理等问题,从对话角度来说,系统可以回答,但严谨程度来说,还需要一定判断。不过,我们可以确保,基于 RAG 知识,例如回答商品何时过期等问题,是准确的。同时,我们接了药膳食指南项目,比如哪些菜、哪些水果是低 GI 的,或者西瓜是否含糖过高。这些知识我觉得没问题,但涉及医学诊断,需要完全另外一个垂直的知识,后面也许可以去对接。另外,叮咚买菜也在专门做菜谱,除了自己做一批,还有人工生产一批,还有基于 AI 生成的,然后做一定微调,包括文生图结合起来的部分也是在做的。
Q6:RAG 用的框架工具是什么?
A6:在 RAG 框架工具选型阶段,我们对多款主流工具进行了对比测试,初期选用 dify 框架;后续基于业务需求进行模块重构,实现了 RAG 相关模块的自主开发。例如单独的记忆模块,短期记忆通过 Redis 缓存实时对话上下文,长期记忆通过向量数据库存储用户画像特征,更长期的数据则依赖大数据平台,比如 HDFS 做长期存储。
Q7:问诊膳食指南有专门部署哪些知识库?
A7:中国营养膳食指南是国家开放的,可以直接在网站上获取。另外,我们还会整理一些自己的知识,例如鲜花应该怎么养护,牛奶应该怎么保存,菜应该怎么做等。膳食指南不像医学领域那么专业,还是偏知识型。同时,类似于百科全书,比如本草纲目等内容,我们也会索引到自己的知识库里面。
以上就是本次分享的内容,谢谢大家。