导读 本次分享深入探讨了阿里巴巴 1688 平台在推理型推荐方面的落地实践。随着大模型技术的兴起,传统的推荐系统面临着“信息茧房”的挑战。1688 通过引入推理型大模型,旨在提升推荐系统的“发现性”,帮助B类买家发现新品、趋势品和潜在商机。本文将从背景介绍、整体架构设计、挑战与解决思路以及未来展望四个方面,详细解析 1688 推理型推荐的完整落地过程。
主要内容包括以下几个部分:
1. 背景介绍
2. 整体架构设计
3. 挑战与解决思路
4. 未来展望
分享嘉宾|邵建智 阿里巴巴1688 算法专家
编辑整理|邱邱
内容校对|郭慧敏
出品社区|DataFun
01
背景介绍
1. 推荐发现性:打破信息茧房
2. 背景
在电商推荐场景中,“发现性”一直是一个重要的议题。传统的推荐系统,特别是基于 ID 类范式建模的系统,往往会导致推荐内容越来越集中,用户看到的商品趋于同质化,从而形成“信息茧房”效应。这种现象使得用户难以发现新的、多样化的商品,限制了其探索广度和深度。1688 作为 B 类批发平台,其买家对新品、趋势品和商机的需求尤为强烈,因此,提升推荐的发现性对于平台和买家都至关重要。
3. 发现性定义
为了解决信息茧房问题,1688 的目标是通过大模型对平台买家长周期行为的深度思考和生意经营推理分析,从而推理出用户的发现性品类或商机商品,全面提升推荐系统的发现性能力。
我们可以从两个主要视角来理解“发现性”。从供给视角来看,它关注的是新品、趋势品和新商家的曝光机会。对于 B 类买家来说,他们需要及时掌握市场动态,包括值得采购的新品、当前流行趋势以及潜在的合作伙伴。例如,当某个热门 IP(如“拉勾股”)走红时,买家会希望推荐系统能迅速推送相关的玩偶、抱枕或带有该 IP 元素的服装等商机。从用户视角来看,发现性则衡量用户行为类目的广度是否有所提升。这里的“类目”是一个广泛的概念,它不仅包含平台现有的三级层次类目体系,也包括基于生成式语义 ID 的码本体系。通过观察用户行为所涉及的类目广度,我们可以评估推荐系统在帮助用户拓宽视野方面的表现。
4. B/C 用户发现性差异
B 端(商家)用户和 C 端(消费者)用户在“发现性”需求上存在明显差异。C 端用户的发现性主要以个人自用为目的,更侧重于跨品类的推荐。例如,当消费者购买了一件上衣,系统可能会推荐一件与之搭配的下装。而 B 端用户的发现性则主要针对批发采购,其维度更为宽广。B 端用户不仅关注跨品类的组货需求,还非常重视在主营品类下发现新的商机。这意味着他们既需要发现与自身主营业务相关的潜在新品,也需要了解不同品类之间的搭配组合,以满足其多样化的经营需求。
5. 推理型推荐的优势
推理型推荐作为认知推荐在近两年大模型兴起后的新发展,相较于早期的知识图谱,具有显著优势。首先,它能充分利用世界知识,增强需求发散能力。大模型能够整合海量的世界知识,从而更精准地理解用户需求,并进行更广泛、更具创造性的需求发散。其次,推理型推荐可检索外部信息,增强商机推荐能力。它能结合外部信息源(如 RAG 检索),获取最新的市场趋势和商机,有效提升对B类买家至关重要的商机推荐能力。最后,发现性商品可溯源,增强推荐可解释能力。通过推理型推荐链路,推荐结果的生成过程可以被追溯和解释,这增强了推荐系统的透明度和用户信任。
02 整体架构设计
1688 推理型推荐的整体架构分为三个核心层面。基建层主要基于用户在平台上的长短期行为数据,深入分析用户的生意需求。这里的数据不仅仅局限于短期行为,而是涵盖了用户一年内的点击、收藏、加购、询盘、搜索等全生命周期行为。由于 B 类用户的生意需求相对稳定,采用长周期数据能够更准确地理解其经营偏好。推理层的核心任务是推理出显式的用户需求趋势 Query。这是整个推理型推荐系统的关键模块,它负责将用户行为和市场趋势转化为具体的、可用于推荐的 Query。应用层则负责推荐链路的应用,包括通过向量检索引擎召回推荐商品,以及后续的调控机制,以确保推荐结果的有效性和精准性。
03 挑战与解决思路
在推理型大模型应用于推荐系统的落地实践中,1688 团队面临了多项挑战。首先,模型选型成本高昂。大模型基础模型的迭代速度非常快,DeepSeek、Qwen 等开源模型层出不穷。在项目推进过程中,团队需要投入大量精力对不同大模型的推理结果质量进行对比和评估,这带来了较高的前期投入成本。其次,模型推理成本也较高。对用户生意理解的指令微调需要进行多版本快速尝试。由于推荐生效链路涉及多个级联串联的算法子模块,初期迭代的资源成本高且周期长。第三,发现性评估难度大。这体现在两个方面:在算法模块上,由于用户个性化的存在,大模型推理的用户生意理解内容和需求 Query 的发现性质量评估相对主观。线上用户反馈信号稀疏,使得模型推理效果评估面临较大难度。在观测指标上,虽然类目宽度和新趋商品 PVR(Page View Rate,页面浏览率)等指标可作为参考,但这些过程性指标与项目最终目标(如 GMV 和 7 天成交转化率)无法完全对齐。最后,离在线推理资源需求大。1688 推荐用户规模庞大,大模型输入 Token 过长导致推理资源需求高。如何在有限资源下,高效分配离线和在线资源,对核心用户进行推理并实验上线,是一个重要挑战。
1. 用户需求与市场趋势理解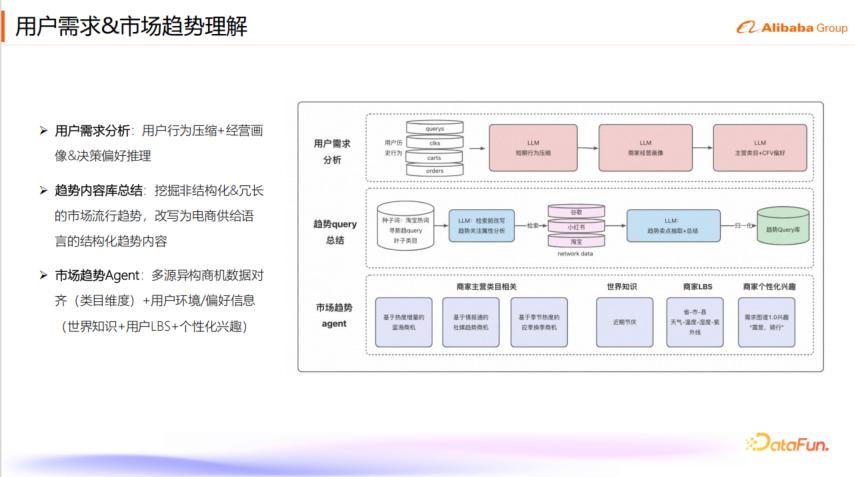
为了解决上述挑战,1688 团队在用户需求和市场趋势理解方面进行了深入探索和实践。
2. 用户需求分析
用户需求分析是整个推理型推荐系统的基石,其目标是理解用户的生意需求和决策偏好。1688 团队将用户需求分析分为三个阶段:
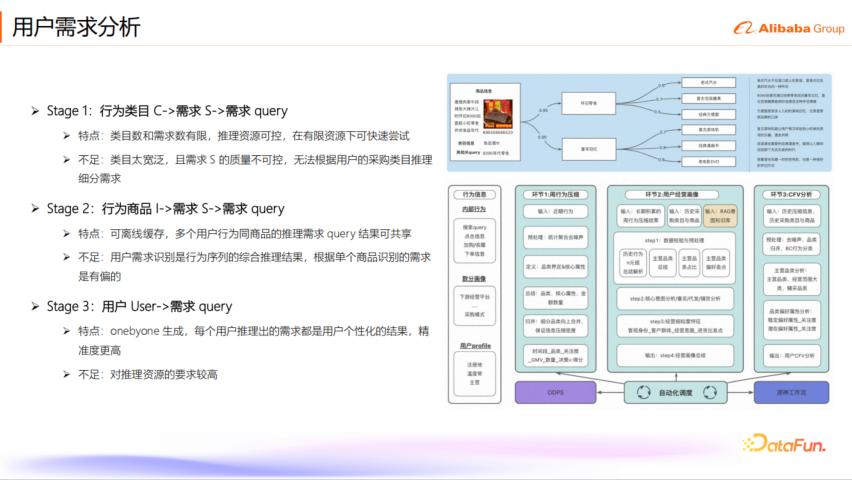
第一个阶段:行为类目 -> 需求 -> 需求 Query。 这是初期尝试,主要根据用户购买的主营类目来推理需求。这个阶段的特点是类目和需求数量有限,推理资源相对可控。但其不足之处在于,类目维度过于宽泛,难以覆盖细分需求(例如连衣裙等大类目),导致推理出的需求质量不可控,也无法根据用户采购数据进行细分需求推理。
第二个阶段:行为商品 -> 需求 -> 需求 Query。 这个阶段基于用户行为商品进行需求推理。平台站内的商品数量有限,推理结果可以离线缓存,不同用户对同一商品的推理需求 Query 结果可以共享,从而提高了效率。然而,其不足之处在于,用户需求本质上是行为序列的综合推理结果,单个商品识别出的需求存在偏差,难以体现用户整体行为序列的差异。
第三个阶段:用户 -> 需求 Query。 这是当前采用的方案,进行一对一的个性化推理。系统会根据每个用户的历史行为,推理出其特定的个性化需求,精准度更高。但这种方式对推理资源要求较高,团队通过优化策略(如推理加速)来应对资源限制。
3. 长周期行为压缩 Agent

为了解决用户行为过长导致的信息漂移问题,并减少大模型推理的 Token 输入长度,1688 设计了长周期行为压缩 Agent。这个 Agent 通过数据侧的预处理聚合和大模型的压缩总结,提取用户行为的关键信息。其定位是解决用户行为过长带来的信息漂移,并降低大模型需求推理的难度。Agent 的输入是用户近期的历史搜索 Query 和历史行为商品标题(采用自研的多模态短标题),数据维度为 8 周,每用户每周数据独立输入输出,形成 52 行数据。Agent 的输出是一个五元组,包含`<周,品类,金额,数量,决策因子>`。为了优化 Token 长度,系统针对用户同品代发行为进行聚合,对周内行为进行长度估算和动态合并,从而充分利用推理资源。在推理资源优化方面,系统设计了自动化推理缓存机制,仅对老用户的新行为和新用户全量行为进行更新,并采用用户单双周分批更新策略,以适应整体用户规模和推理资源。
4. 多模态短标题:
传统的商品原标题存在大量商家 SEO 信息,且无法充分体现图像内容。为了解决这些问题,1688 自研了商品多模态短标题能力。该能力基于 Qwen-VL 等多模态大模型,理解商品的风格、款式等细节信息,生成可被文本大模型理解的多模态标题文本,从而将图像信息压缩整理到标题中,以适应文本推理链路。
5. PE 示例(Prompt Engineering)

长周期行为压缩 Agent 的 Prompt Engineering(PE)示例包括:任务定义是将其设定为数据摘要专家,负责总结分析用户行为。用户行为输入包含时间段、搜索词、点击商品(浏览时长_标题)、加购商品(标题)、支付商品(单笔 GMV_购买数量_标题)等格式化信息。相关定义明确了电商场景下的品类定义和决策属性值定义(决策属性值长度小于 5 个字,不包含品类词本身)。任务步骤分步执行,首先按明确品类归纳行为,然后按品类逐个商品分析并提取决策属性值。输出格式例如“##250504_卡片_22_65_3_魔童闹海:22|炽影包:7|五元包:5”,它包含了日期、品类、关注度得分(点击、收藏、购买)、品类 GMV 总额、品类购买数量以及细分属性和其关注度。
6. 用户生意画像理解 Agent

在行为压缩之后,第二个大模型 Agent 会根据压缩结果输出用户的经营画像。团队与产品团队经过多轮沟通,定义了 B 类用户的经营画像,主要包括:
主营类目分析,例如女装(70%)和配饰(15%),并进一步细化到风格、材质、功能功效、适用场景和设计元素等。垂类 B 买分析旨在识别用户是否为专业买家。代发买家及铺货类型分析用于识别用户是否为代发买家以及其铺货类型(如精铺)。核心意图是总结用户关注的核心意图,例如“[显瘦气质套装,减龄通勤,气质小香风]”。买家画像构建则包含多个维度:客观身份,例如“平台电商-铺货型-高频跟爆精铺商贸公司,专注于女装、时尚套装分销领域”;客户群体,例如“都市蓝领女性,偏好显瘦、通勤风格的服饰”;经营思路,例如“以季节性采购为主,聚焦中高价位商品,复购率高,长期稳定补货”;进货出发点,例如“[显瘦效果显著,品质优先,风格紧跟潮流]”;最后是对买家画像的总结,例如“该商家为专注女装领域的精铺型电商平台……”。
7. 用户 CFV 偏好示例(Cate-Factor-Value)

CFV(品类-因子-值)是电商场景中的专业名词,它指的是在特定品类下用户关注的核心细分决策因子。用户 CFV 偏好分析包括两个主要方面:
品类分析涵盖了主营品类、主营大类、辅采品类、垂买分析和代发分析。例如,一位主营女装的用户可能还会辅采工业品(如包装材料)。CFV 分析则包括用户的长期偏好属性、近期偏好属性和潜在偏好属性。例如,在“连衣裙”品类下,用户的长期偏好可能是“法式:9|碎花:8|黑色:7|收腰:6”,近期偏好可能是“气质:9|蓝色:8|收腰:7|高级感:6”,而潜在偏好可能是“法式:法式复古:10|碎花:刺绣花纹:8|黑色:深蓝:7|收腰:高腰设计:6”。
通过对用户历史行为序列的压缩、生意画像的理解以及 CFV 偏好的分析,1688 才能够真正读懂 B 类用户的经营诉求,为后续的商品召回提供准确的方向。
8. 趋势内容库挖掘

在理解用户需求的基础上,还需要挖掘与平台供给相关的市场趋势,并将相关商品推荐给用户。这部分工作面临的挑战是:直接 RAG(Retrieval Augmented Generation)的趋势内容多样性高但准确性不足,且非结构化、冗长的趋势信息有效信息熵低。
9. 方案
1688 的解决方案是多管齐下的:首先,建立全面的种子 Query 库,其中包含了全叶子类目、淘宝热搜词、站内增速词、站内寻新趋词等多种来源。其次,进行品类趋势分析,对特定品类(如儿童连衣裙)进行深入分析,识别与 IP、风格、色系、款式设计等相关的关键属性。第三,整合多元 RAG 下游信息源,将小红书、Worthbuy、Google、淘宝等多个信息平台作为 RAG 的趋势来源。第四,总结趋势卖点,对检索到的趋势内容进行精简和提炼,形成电商语言下的下游趋势 Query 和趋势理由。例如,将“儿童连衣裙”改写为“2025 儿童连衣裙趋势解读,爆款/新款/趋势品,热门流行风格,创新色系”等长文本,再进行 RAG 检索。最后,进行趋势Query归一化,基于大模型 Embedding 相似度对趋势 Query 进行聚簇归一化。
10. 市场趋势 Agent

用户了解市场趋势商机具有多样性,包括下游消费者热搜、时令节日需求、同行采购等。市场趋势 Agent 利用多元异构商机数据进行对齐,主要包括:用户需求兴趣,基于前序用户画像工作,获取核心场景需求词,例如“露营”、“学走路”。LBS+天气,结合用户地理位置(省市县)、天气、气温、湿度、紫外线等信息。节气节日,利用节气节日库数据,提前推理节日相关商品,例如国庆的国旗、中秋的月饼。应季换季,沉淀商品应季分析,获取类目与应季世界知识。蓝海商机词,挖掘站外蓝海商机 Query,通过类目预测获取相关信息。情报通,利用阿里内部的情报通能力,挖掘全网热词(如“恋与深空”IP)和全网话题(如“十二生肖符咒转场”),并判断其电商承接潜力。相关性分析,判断检索内容与词条的相关性,只对相关内容进行分析。商机分析,评估词条及相关内容是否存在潜在电商品类商机,例如明星同款、影视 IP 衍生品。商机 Query 抽取,如果存在商机,抽取核心电商关键词(如“杨幂同款”、“新手爸妈”),并总结 5 个商机品 Query,确保是实体商品而非虚拟商品。
11. 趋势 Query 生成
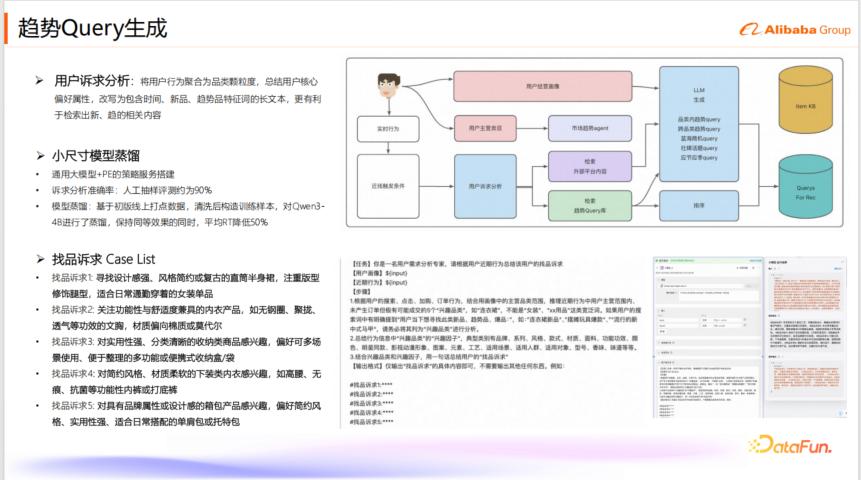
趋势 Query 生成是将用户行为聚合为品类颗粒度,总结用户核心偏好属性,并改写为包含时间、新品、趋势品特征词的长文本,以利于检索出新、趋相关内容。
用户诉求分析:系统将用户行为聚合到品类颗粒度,总结其核心偏好属性,并改写为包含时间、新品、趋势品特征词的长文本。这用于检索趋势内容库中的推荐理由,从而实现用户需求语言与趋势语言的对齐。
小尺寸模型蒸馏:为了解决推理资源限制,团队对 Qwen3-4B 小模型进行了蒸馏。在保证效果不变的前提下,平均 RT(响应时间)降低了 50%。蒸馏数据是基于初版线上打点数据清洗后构建的。
找品诉求 Case List:例如,用户可能希望“寻找设计感强、风格简约或复古的直筒半身裙,注重版型修饰腿型,适合日常通勤穿着的女装单品”。模型会将这类描述作为 Query 进行检索。
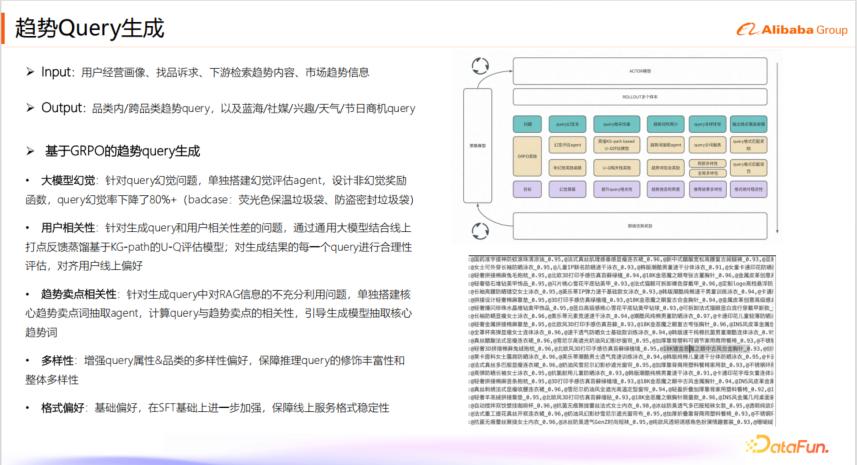
基于 GRPO 的趋势 Query 生成:为了优化趋势 Query 的生成,团队采取了多项措施:首先,解决大模型幻觉问题。针对 Query 幻觉问题(例如生成“荧光色保温垃圾袋”),团队单独搭建了幻觉评估 Agent,并设计了非幻觉奖励函数,使 Query 幻觉率下降了 80% 以上。其次,提升用户相关性。通过通用大模型结合线上反馈,蒸馏了基于 KG-path 的 U-Q 评估模型,对每个生成的 Query 进行合理性评估,以对齐用户线上偏好。第三,增强趋势卖点相关性。针对 RAG 信息利用不充分的问题,团队单独搭建了核心趋势卖点词抽取 Agent,计算 Query 与趋势卖点的相关性,引导生成模型抽取核心趋势词。第四,增加多样性。增强 Query 属性和品类的多样性偏好,确保推理 Query 的修饰丰富性和整体多样性。例如,为用户生成 20 个 Query 时,避免全部集中于一个品类或属性。最后,强化格式偏好。通过 SFT(Supervised Fine-Tuning)加强格式稳定性,确保输出为 JSON 等可被工程链路直接对接的格式。
12. Query 与商品召回的取舍
在生成 Query 时,团队发现如果 Query 过长(6-8 个字甚至更长),电商供给可能不充分,导致召回的商品很少。因此,在商品检索时,不强制要求商品完全匹配 Query 的所有属性。例如,上层 Query 有三个属性词和一个品类词,如果召回商品能满足其中两个属性和一个品类,也是可以接受的。这种取舍旨在解决供给不足的问题,并允许生成更长、更具发散性的 Query。
13. 近线链路设计
为解决首猜 RT(响应时间)限制、资源限制和兴趣时效性问题,1688 在原有离线链路基础上新增了近线链路设计。
14. 出发点
近线链路设计的出发点主要有三方面:首先是首猜 RT(响应时间)限制。多个串行环节需要大模型推理,单个模块的推理 RT 可能超过 10 秒,这对于实时性要求高的首猜场景构成了约束。其次是资源限制。在线机器资源有限,需要完善的调控机制来最大化利用现有资源。最后是兴趣时效性问题。离线链路无法捕捉用户当日的实时行为,导致推荐内容可能滞后。
15. 近线方案
近线方案主要包括触发 Trigger 设计和功能模块。
在触发 Trigger 设计方面:
全域行为触发:用户不一定只在推荐场景活跃,他们可能在搜索、旺铺等私域场景有大量行为。当首猜行为稀疏时,仅凭首猜行为无法及时承接用户兴趣变化。因此,系统采用了全域行为触发策略,例如用户在私域搜索或成交几次、点击几次商品后,即触发用户需求推理。全网商品行为窗口:系统接入了实时 Blink 数据流,基于用户行为数量窗口动态调整推理更新频率。例如,设定窗口阈值为用户在平台看过 5 个商品详情页,即触发需求推理。窗口数量可以根据动态资源情况进行调整,以平衡时效性和资源消耗。在功能模块方面:
用户离在线数据收集:系统收集用户的长期经营偏好、全网点击/收藏/加购/下单等行为,以及 RAG 拓展的品类热门卖点知识。两阶段个性化生成召回:这包括 U2Q(User to Query),即基于大模型的 U2Q 生成,以及 Q2Vec(Query to Vector)技术,将用户转化为 Query 向量;以及 Q2I(Query to Item),包括非个性化高相关性的 Q2I 和个性化动态调权 UQ2I,将 Query 转化为商品。统一粗、精排打分模块:对召回的商品进行粗排和精排,以确保推荐质量。链路平均 RT:经过优化后,链路平均响应时间控制在 7-10 秒。
16. 推理结果示例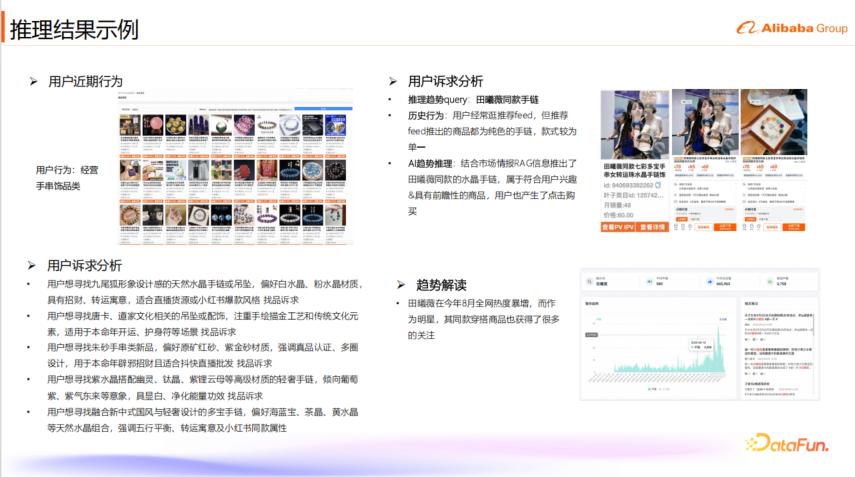
通过上述链路,1688 的推理型推荐系统能够生成精准且具有前瞻性的推荐结果。例如,在用户近期行为方面,用户可能经常浏览推荐 Feed,但推荐的手链款式较为单一。经过用户诉求分析,系统发现用户可能想寻找九尾狐形象设计感的天然水晶手链或吊坠,偏好白水晶、粉水晶材质,且具有招财、转运寓意,适合直播货源或小红书爆款风格。通过 AI 趋势推理,结合市场情报 RAG 信息,系统推理出“田曦薇同款水晶手链”。由于田曦薇在近期全网热度暴增,其同款商品不仅符合用户兴趣,还具有前瞻性,用户点击购买,从而实现了成功的发现性推荐。
其他找品诉求示例可参考上图(用户诉求)。
04未来展望
1688 推理型推荐的未来发展将聚焦于以下几个方面,以持续优化推荐效果和用户体验。
首先是发现性定义优化。当前类目维度的发现性更适合 C 端用户。对于有主营品类生意的 B 端用户,过细的同款簇和过粗的类目簇都不适合用于监控。未来将推进使用生成式语义 ID 的 Codebook 前 N 位作为商品簇,以更精细化地定义和衡量发现性。
其次是用户需求偏好优化。系统将结合用户图搜、询盘等 B 类特有的行为数据,增强用户需求推理的准确率和召回率,从而更全面地捕捉 B 端用户的真实意图。
第三是多模态推理能力的加强。当前系统主要依赖文本信号,视觉信息丢失严重。尤其在女装等非标行业,商品的风格和款式主要体现在图片中。未来将加强多模态推理能力,更好地利用视觉信息进行推荐。
第四是 Agentic RAG 的应用。市场环境 Agent 将整合小红书、Google、淘宝等多个 RAG 源,以及时令节日、城市、气温等不同类型数据。模型将根据用户长期经营需求,自主决策使用相关的 RAG 数据,实现更智能、更灵活的信息检索。
最后是生成式 Query 召回。模型基于用户需求生成 Query 后,将利用泛语义 ID 形式(基于多模态表征训练得到)进行生成式召回,进一步提升召回的精准性和多样性。用户需求分析、多源异构的市场趋势挖掘、以及优化的近线链路设计,1688 显著提升了推荐系统的发现性和商机推荐能力。未来,随着多模态推理和 Agentic RAG 等技术的进一步发展,1688 将持续为 B 类买家提供更智能、更精准、更具前瞻性的推荐服务,助力商家生意增长。
以上就是本次分享的内容,谢谢大家。