2025 年 1 月 20 日,硅谷的很多投资人失眠了。
不是因为 OpenAI 发了什么炸裂的新模型,也不是因为谷歌又搞出了什么黑科技。
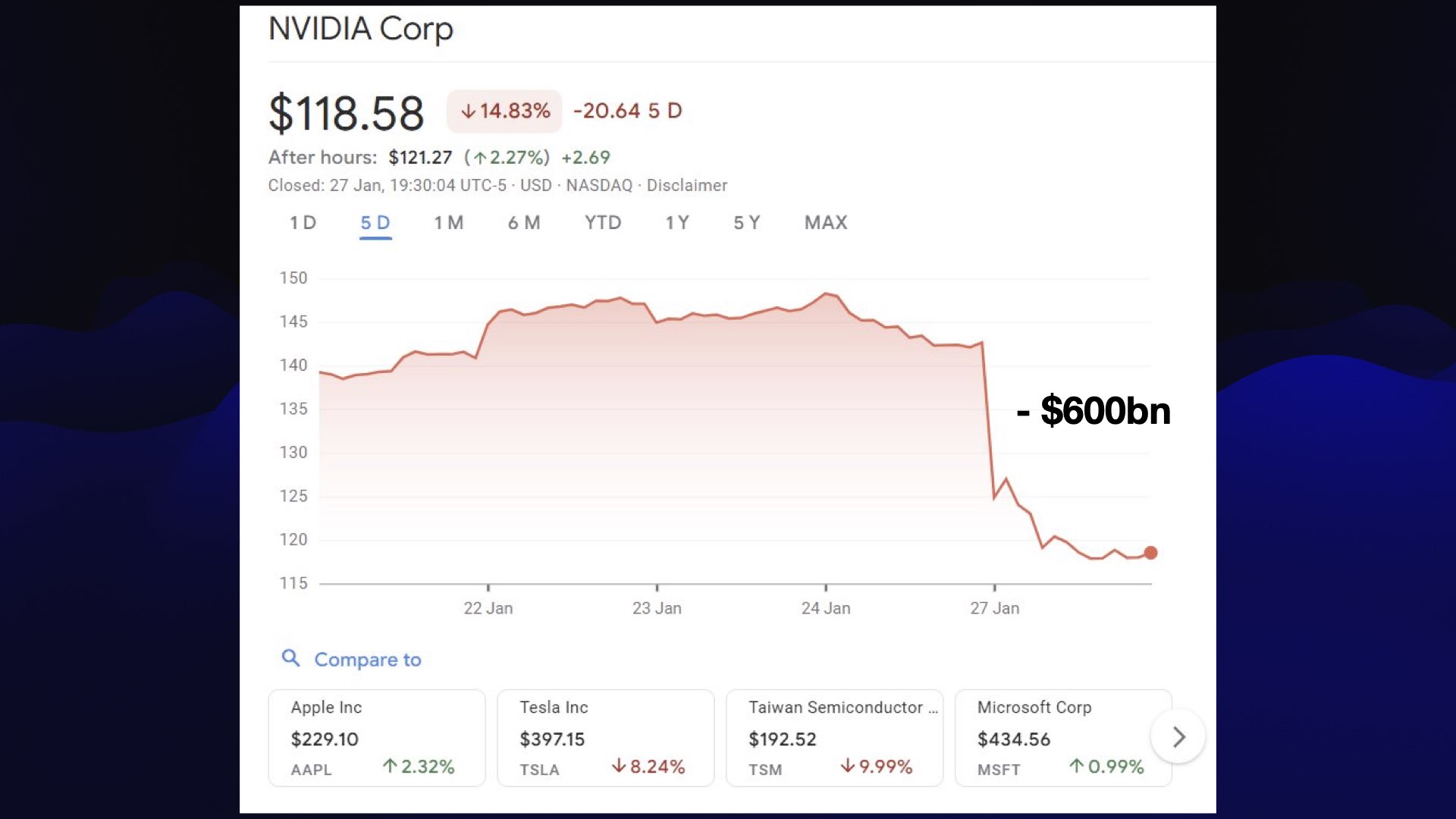
这一天,让所有人夜不能寐的,是一家中国公司发出的一个链接。
随之而来的,是英伟达股价的一根断头铡刀,单日蒸发 5930 亿美元。
这可能是科技史上最魔幻的一天:一个只花了 550 万美元训练出来的模型,竟然把一个万亿帝国的市值,瞬间打没了半个亚马逊。
说实话,我是真的看乐了。
这就像是你开着一辆几百万的法拉利在赛道上轰油门,旁边突然窜出来一辆改装过的五菱宏光,不仅超了你的车,司机还摇下窗户问你:“哥们,你这车油耗挺高吧?”
这就叫降维打击。
这事儿咱们得从头撸一撸。
大家知道,直到 2024 年底,美国科技圈还普遍有一种傲慢。那种感觉就是:AI 是我们的后花园,卡是用不完的 H100,模型是遥遥领先的 GPT。至于大洋彼岸?也就是跟在后面吃点尾气,或者做点套壳应用罢了。
这种傲慢,在去年圣诞节第一次被打脸。
那时候 DeepSeek V3 发布。美国人一开始没当回事,觉得“哟,不错哦,能跟 GPT-4 掰掰手腕了”。
但紧接着,当他们看到那个数字时,笑容凝固了,训练成本 550 万美元???
你知道这是什么概念吗?这就像是大家都还在比谁烧钱快,OpenAI 恨不得把太平洋的水都抽干来发电训练模型,结果有人告诉你,他用几节干电池就把事儿办了。
如果说 V3 是打脸,那 1 月 20 号发布的 DeepSeek R1,就是拿着鞋底子往脸上抽了。
这是一个推理模型。在此之前,大家都觉得“推理”是 OpenAI o1 系列的护城河,是需要极高的算力门槛才能跨越的天堑。
结果 R1 一出来,直接把这个门槛踩平了。不仅性能硬刚 o1,而且——它是开源的!!!
MIT 协议,全套公开。
那一刻,华尔街终于回过神来了:坏了,逻辑变了。
以前他们的逻辑是:AI 越强=需要算力越多=英伟达显卡越贵。这是一个完美的闭环,所有人都躺在这个泡沫上数钱。
DeepSeekR1 把这个闭环捅了个窟窿:原来 AI 变强,不需要那么多显卡?原来靠算法优化,能省下几百倍的钱?
这就是为什么英伟达崩了。华尔街怕的从来不是中国 AI 变强,华尔街怕的是中国 AI 便宜。
一旦“便宜”这个潘多拉魔盒被打开,那种动辄几十亿美金训练一个模型的“暴力美学”时代,可能就要结束了。
这让我想起了一个特别尴尬的场景。
大家在职场上有没有经历过那种时刻?
开会的时候,老板突然问了你一个特别基础的数据,或者一个你本该知道的细节。那一瞬间,你脑子一片空白,喉咙像堵了团棉花。
你想解释,你想说我也很努力,但看着满屋子人等你答案的眼神,那种生理性的羞耻感,真的让人恨不得找个地缝钻进去。
我觉得那天,面对 DeepSeek R1 甩出来的那个 $5.5m,整个硅谷的精英们,大概就是这种感觉。
拿着几百亿美金的融资,烧着全美最贵的电,最后被一个“穷小子”用十分之一不到的钱教做人。这都不止是羞耻,这是公开处刑。
最讽刺的是,这次围剿美国 AI 霸权的,还不止 DeepSeek 一家。
看一眼 2025 年底的 Artificial Analysis 榜单,Kimi、DeepSeek、GLM、MiniMax、Qwen……琳琅满目的中国模型。
而且,全是开源的。
OpenAI 那个名字里带着“Open”的公司,现在的顶级模型全是闭源的。而这些被他们防着、卡着、制裁着的中国公司,却把最强力的武器直接放到了 GitHub 上,供全世界免费取用。
这一波,真就是“农村包围城市”。
回过头看,2025 年可能是 AI 历史上最关键的分水岭。
在此之前,大家比的是谁更有钱,谁卡更多。在此之后,游戏规则变了,比的是谁更聪明,谁能用更少的资源干更多的事。
这事儿告诉我们一个最朴素的道理:
你可以封锁技术,你可以封锁硬件,但你永远封锁不了那股想“活下去、活得更好”的倔强。
声明:本文内容 85% 左右为人工手写原创,少部分借助 AI 辅助,同时参考了 Contentany 的 AI 检测、同质化指标和人性化润色优化,以上所有内容和数据都经过本人严格审核和核对。