
什么???英伟达员工来了,也得考公???

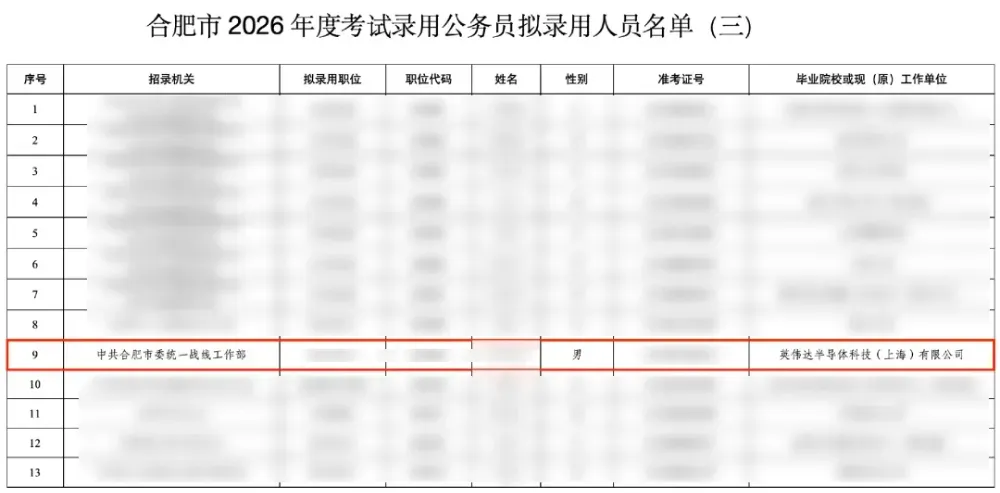
起因是,近日网上流传出一则《合肥市2026年度考试录用公务员拟录用人员名单》公示,其中,有一哥们的原工作单位特别显眼:
英伟达半导体科技(上海)有限公司!!!!!!!
果然啊果然,再高的薪,也阻拦不了人们上岸的心。
要知道,作为在全球AI热潮中收益最大的公司之一,英伟达堪称“当红炸子鸡”,红利吃到喉咙管冒油。公司里的正式员工,更是人均一大大大碗肉汤。

但就是这么一家无数毕业生的“梦中情企”,和编制一比——
啧,好像也没那么香了。(bushi)
在这个全民“考公热”的时代,船长突然有了个大胆的想法:
你说,让AI们也来考一个公?他们考得明白吗?!
谁会顺利上岸,谁又会绝望下岸呢?(好奇.jpg)

是骡子是马,也该拉出来溜溜了。
我们依次准备了豆包、千问(Qwen3.7-Max)、元宝(Hy3 preview)、Kimi、DeepSeek 5款国产AI App。并且,都开了“深度思考”模式。
为了让豆包深度思考,所以我们选择的是“专家模式”(豆包大模型2.0Pro),在Kimi的时候,则选择切换了“K2.6思考”模式。
D老师要稍微吃点亏,本想试试D老师的专家模式,但无奈不支持上传图片。

往往,我们想要get到模型的能力几何,都会先把它们网线拔了。
但这回,我们不,我们全部联网,相当于给AI“开卷考试”,放水放到太平洋。
总之,能上的手段都上了,不能上的也上了。所有准备工作齐全,本以为都到这份上了,各位AI的表现应该不会太撇。也许、可能、我说大概,是的吧?
结果?结果!
看得人低血糖犯了。先给各位一个最直接、最简洁的结论:拉完了。
能把卷子从头到尾完全做完的,只有豆包、千问和Kimi。
正确率也没我想象中那么高。比如,至少有个85+???
事实却是,欲知后事如何?您自个儿接着往下看吧。。。

因为我们把试题是以拼接的形式整合在了一张大图上,而显然D老师在识别这种大图上,心有余而力不足。毕竟,D老师手拿把掐的还是文本,就很吃亏。
我只能说,能理解但不想接受。老D啊,你可是我们眼中的“好学生”!!!!
众所周知(不知道也没关系),公务员省考考试分为两门:
《行测》和《申论》。
我们先端上桌的是这份传说中,并不算太难的2026年四川省考《行测》试卷,只有个别题比较“变态”。一共100道题,又分为政治理论、常识判断、言语理解与表达、数量关系、判断推理、资料分析5个板块。

最简单的还是政治理论和常识判断,特别是在没断网的情况下,简直是送分题。
而我们全程都是:“请做一下这几道题,并且将答案汇总给我,注意按顺序做题。”
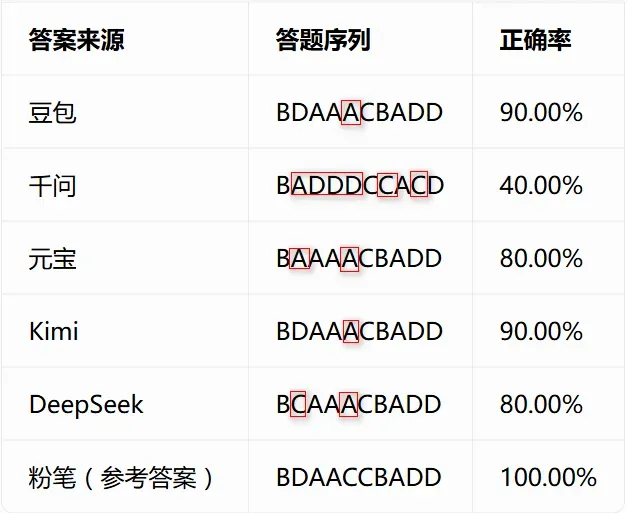
欧克!先来10道政治理论(1-10题)醒醒神:

图为:政治理论(试题源于粉笔)
以粉笔给出的答案为参考,豆包、千问、元宝、Kimi、DeepSeek的正确率分别为90%、40%、80%、90%、80%。
毫无疑问,在一轮,千问表现得最不尽人意……(你看看别人家的孩子都考了多少分!嗯?怎么上来就拉胯了呢?问。)
而且,咱还得给千问补上一刀。
都说了要汇总给我,别的同学都听明白了,来了个最后总结。结果呢,子涵千问同学汇而不总,还得我亲自去他的分析里找答案,看得我老眼昏花。
细节小扣一分,像极了,小时候你隔壁那个拿着题就跑,根本不读题的同桌。速度倒是挺快的,可是这个正确率嘛,简直是闻者伤心,听者流泪啊。

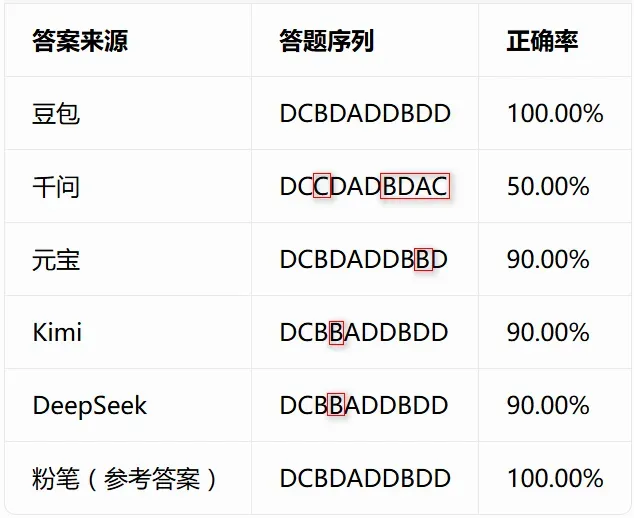
再看常识判断部分(11-20题)。

图为:常识判断(试题源于粉笔)
按道理,这个常识题对他们来说,是最最最最最最简单的。
更何况,我们还没有把网线掐了,可比大家伙蒙着眼睛在考场上乱撞强得多得多。
然而,不出意外地出意外了,千问的正确率仍然只有60%。没招了,真的没招了。
就,豆包在这一把倒是让人刮目相看,正确率100%???
具体来看看Kimi和DeepSeek都错了的14题:

其实仔细看看Kimi和DeepSeek的分析会发现,
他们都很快分析出了①写于海南儋州,②写于广东惠州,③写于湖北黄州,按从北到南的顺序排名就是——③②①。
结果,在选择答案的时候,Kimi和DeepSeek就像进入了“赛博鬼打墙”一样。
其实Kimi在答案核对时,是反应过来了的,应该选D,而不是B。
但他很有“脾气”,并没有改。

而D老师则表演的是什么叫过程全对,答案全错了。
好消息:③②①是排出来了的。坏消息:不妨碍他一头走入③①②的死胡同。
就这个左右脑互搏的过程,看得人以为D老师突然脑子短路,被降智了???

准确点说,这并不能证明是D老师推理能力不行,也就是不是“不会做题”。
而是非常典型的“答案映射错误”。
推理链正确,选项映射错误,导致最终答案与推理链不一致。
事实上,为解决这一问题,减少此类错误,保证最后一句一定与推理保持一致,很多大模型都会在推理过程中加上一句“密语”:
“Final Answer Consistency Check”,即推理完成→重新检查→再输出答案。所以,你看看,Kimi其实检查出来了,但最终没修改反馈。
前面还是开胃菜,就已经暴露出了许多问题。接下来的“重头戏”就更刺激了。
第三部分,言语理解与表达(21-45题)。
为什么我们会选择四川省考试卷,有很重要一个原因:言语理解与表达。四川卷是出了名的,在言语题上面,出题人经常是神一套鬼一套的。

图为:言语理解与表达(试题源于粉笔)
考得四川考生是叫苦不迭,而同样的坑,AI们也一个一个排队掉了进去。
先说,由于我的大长图是用5张图拼起来的,显然,超出了D老师的能力范围,他他他他宕机了。无论尝试多少遍,始终都是无法识别的状态,遂放弃。
接下来,其他几位在一关的表现如何呢?
豆包正确率60%,千问正确率48%,元宝正确率48%,Kimi正确率76%。

Kimi拿下本轮测验的头筹。而元宝,中途甚至还看岔劈了,给我整出了46题,直到我发现他的45题是把41题给看错了,而无中生有出来的。

考完语文能力,再考数学能力。
是本场考试中最难的部分:数量关系(46-55题)。船长查了一下,往往很多真考生在考场上做到这一部分,都是直接放弃。要么全选C,要么全选B。

图为:数量关系(试题源于粉笔)
那AI们呢?
由于在这一轮中,出现了两位满分选手——豆包和千问。
所以我们就不过多BB。说明这种题,对他们来说,还算是舒适区。

而D老师,在55题的推算中同样也是算出了正确答案,但在复核时,又错了。
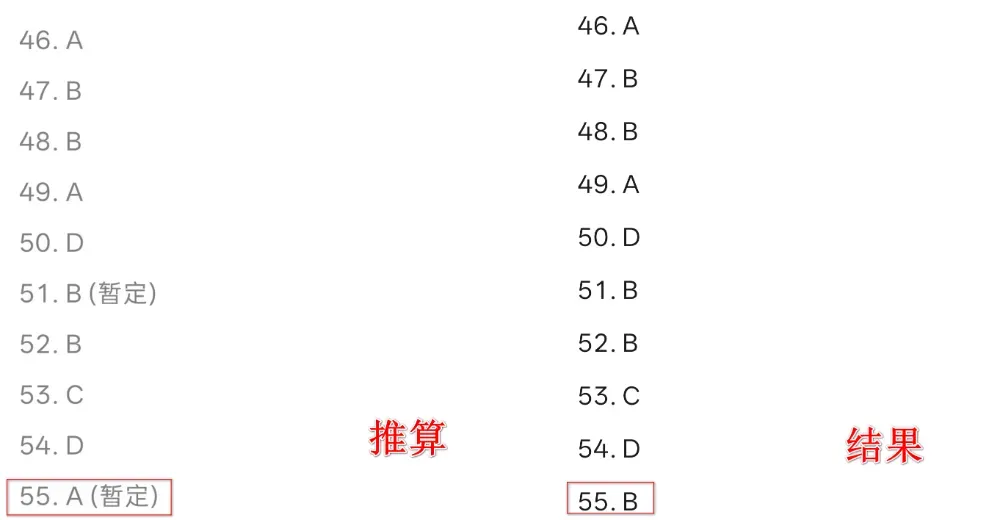
错过,才是常态啊。
到第四部分的推理部分,我们将之拆分成了图形推理和推理。
D老师同样在这一个环节不参与,因为他压根连题目都读不了。
在图形推理(56-63题)方面:
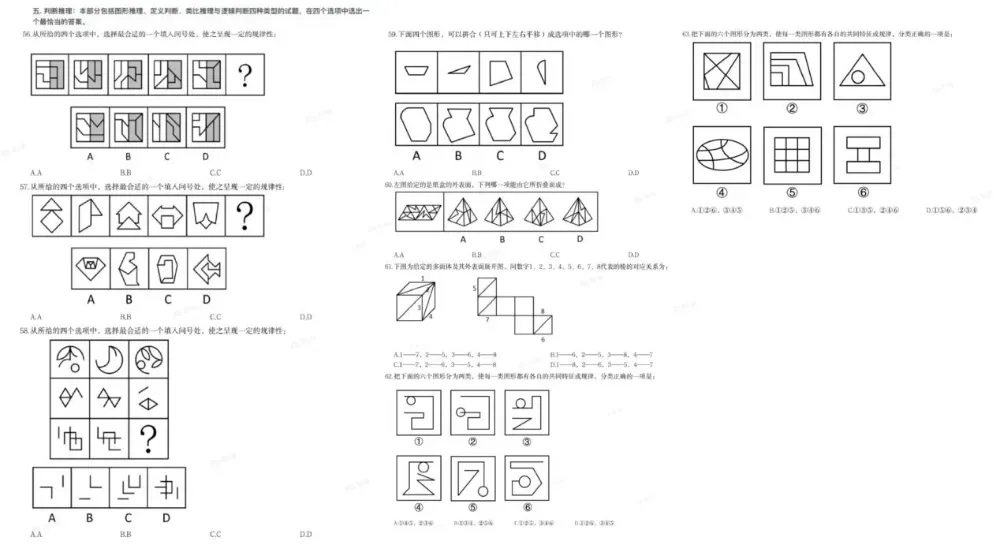
图为:图形推理(试题源于粉笔)
从惨淡的正确率来看,我就一句话:
“你们简直是我带过的最差的一届”。(bushi)
当然,在一个环节里,可以看出,豆包作为多模态模型,在识图上确有优势。

语言推理部分(64-85题):

图为:语言推理(试题源于粉笔)
这一部分基本上可以说是“废了一半”。
D老师完全不能识别就不说了,元宝做着做着,眼睛花了,脑子烧了,眼睛花了,题号有不少出错的,并且是从71题才开始做,大约有接近小一半的题没做出来。

图为:元宝答案
元宝、千问、Kimi都基本在最后两三道小题上卡了很久。
一方面,是我们这张图,确实识别题目有难度。另一方面,是因为这一部分所考的逻辑推理,正是大模型最“瑟瑟发抖”的逻辑。
你想想,连“走路50米去洗车”都能成为一道经典的逻辑陷阱题,所以当豆包遇上让她去分豆沙月饼的逻辑推理题时,直接给干成原地转圈了。
CPU烧了……
咱豆姐就一直卡在这个重新推导月饼组合这里:

直到我们反复投喂了三次题目,第三次才做出来。
豆姐:我已力竭,我已麻木。
当然,千问在84题志愿者那道逻辑题上给干“关机”了,不过后面他自个儿重启了一下,又这么从头再推了一次才算理顺。

最后嘛,豆包、千问、Kimi的正确率如下:

(豆包漏了79题,用X替代)
不得不说,Kimi在逻辑推理上,比其他两家,在这简单的22道题里表现得更出色。符合我对Kimi老师的“刻板印象”。就是Kimi老师,你你你,要会员。
终于,终于写到了最后的资料分析(86-100题)。
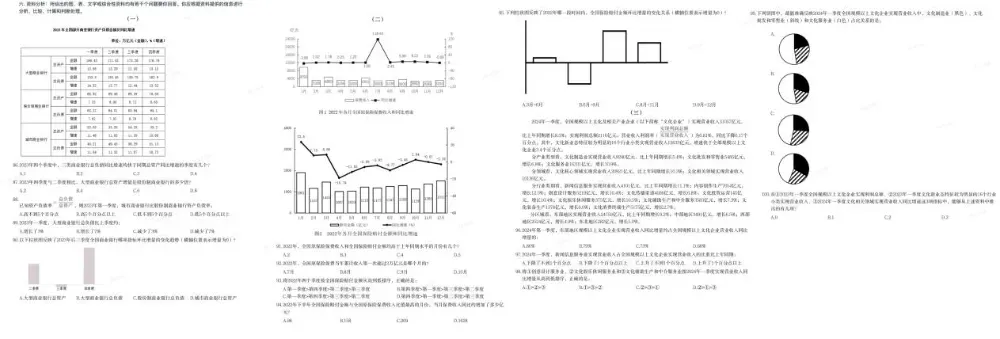
图为:资料分析(试题源于粉笔)
BGM起:离考试还有15分钟,请考生们抓紧时间。
紧张了,家人们,好紧张,真的。
紧张到D老师仍然无法识别。

紧张到元宝只识别并做出了86-90的5道题。

而能把题做完的,还是只有豆包、千问和Kimi:

要说完成度和正确率的话,豆包、千问和kimi在测试过程,算是相对比较突出的。至少人能把答题卡都填上。总比空着强是吧。。。
甚至,豆包,在常识题和数量关系上,还拿了两次满分。
但讲真,我算了算,就算按照豆包这个做题能力,最终得分也就在77分左右。而一个四川考生,想要真的上岸,行测大概在70分以上才算希望较大。
所以啊,如果你能在这套卷子上拿下80分的高分,那恭喜你,比以上几款AI都要强。如果暂时还没有的话,朋友们,上岸之路,道阻且艰,唯有努力。
但是,你以为咱们要宣布,豆包真的就是最后的赢家了吗?
啊,nonono。
各位发现没有,船长的几张答案对比图的格式是不一样的,原因是,最开始我们让豆姐出来卖个力,作图。
诶嘿,咱豆姐连题目的数量都*****(手动消音)给我输错了!制的图根本不能直接用,我还得手搓加工。
甚至一共就10道题,她能给我数成11道???就很离谱,家人们。

为了省事,中途我们也请了“外援”——ChatGPT。
有一说一,GPT老师制图的美观性和准确度比豆老师要高很多(带蓝色儿的都是他出手的),关键信息一目了然。
但是!魂淡!GPT老师在框选错误答案和计算正确率时也出错,也要我人工告知。然后,我一说,他就明白。。。
让老C以最正确、最直接的方式来制图。比豆老师强,但也不是万能的。

然后吧,然后,我又发现——
其实在纠正GPT老师时,我也把本该是48%的千问正确率,算成了44%……
真是,好尴尬啊。世界就是个巨大的草台班子,真的。
至此,我认为,本次测试没有赢家。散会。