 摘要
摘要随着人工智能与自动化技术的发展,代理程序(Agents)作为实现复杂任务自动化的核心组件,其高效运行对系统架构提出了更高要求。本文深入剖析代理程序的核心挑战,结合Go语言的并发模型、内存管理与工具链特性,阐述其在构建高并发、长生命周期代理系统中的独特优势,并通过工程实践案例提供技术选型参考。
一、代理程序的核心挑战与架构特征1.1 代理程序的定义与应用场景代理程序是一类具有自主决策能力的循环执行进程,通过动态规划执行路径完成复杂任务,例如:
AI代码生成:根据需求生成、调试代码并运行测试自动化运维:跨集群部署、监控与故障修复数据管道编排:大规模数据清洗、转换与加载其典型特征表现为:
特征维度
具体表现
生命周期
单次执行持续分钟级至小时级,支持中断恢复与状态持久化
资源消耗
包含LLM调用、浏览器自动化、GPU计算等高价操作,单次成本可达数十美元
交互性
需处理用户实时输入、外部系统回调等异步事件
状态复杂性
执行路径非确定性,支持分支逻辑(如条件判断、重试循环、子任务调度)
1.2 传统架构的局限性在Node.js/Python等传统Web架构中开发代理程序时,常面临以下问题:
并发瓶颈:Node.js单线程模型下,数千个长连接易导致事件循环阻塞资源管理风险:Python多线程的GIL锁限制CPU利用率,多进程模式存在跨进程通信开销取消机制缺失:缺乏标准化的上下文传播机制,强制终止任务可能引发资源泄漏二、Go语言的适配性:从语言特性到工程实践2.1 轻量级并发模型:goroutine的革命性突破2.1.1 性能数据对比
语言/运行时
并发单元
初始内存占用
千并发实例内存开销(64位)
Go(goroutine)
goroutine
2KB
~20MB
Python(线程)
threading
8MB
~80GB
Node.js(事件)
异步函数
动态分配
~500MB(含V8引擎开销)
2.1.2 实战优化策略
CPU亲和性:通过runtime.LockOSThread()绑定goroutine至特定CPU核心,避免上下文切换无锁设计:使用sync.Map替代map+Mutex,在读写比10:1场景下性能提升40%批量处理:通过golang.org/x/sync/errgroup实现任务分组并发,配合time.Ticker控制请求频率2.2 基于通信的内存管理范式2.2.1 通道(channel)的设计模式
// 带优先级的任务队列(基于缓冲通道) type Task struct { Priority int Payload []byte } func WorkerPool(jobs <-chan Task, results chan<- Result) { for job := range jobs { res := process(job.Payload) results <- Result{job.Priority, res} } } // 优先级调度器 func Scheduler(jobs chan<- Task, highPriorityJobs <-chan Task) { for { select { case job := <-highPriorityJobs: jobs <- job // 高优先级任务抢占通道 default: // 普通任务按速率限制发送 time.Sleep(100 * time.Millisecond) jobs <- defaultJob } } }2.2.2 状态管理最佳实践
无状态设计:代理程序实例仅维护当前任务状态,通过消息队列(如Kafka)实现跨实例状态同步持久化检查点:利用encoding/gob将中间状态序列化为文件,支持context.Context触发的优雅恢复2.3 标准化工具链:从开发到运维的全链路支持2.3.1 可观测性体系构建
# 内存分析:生成堆内存配置文件 go tool pprof -alloc_space http://localhost:6060/debug/pprof/heap # 并发分析:可视化goroutine阻塞点 go tool trace -http=:8080 trace.out2.3.2 生产环境部署方案
组件
推荐方案
优势说明
进程管理
systemd + supervisor
支持动态扩缩容、日志轮转
配置中心
etcd + viper
分布式配置同步,支持热加载
监控告警
Prometheus + Grafana
内置goroutine数量、内存分配等原生指标
链路追踪
OpenTelemetry + Jaeger
基于context传播的全链路追踪
三、典型场景实现:以代码生成代理为例3.1 需求分析构建一个支持代码生成、测试运行、漏洞扫描的全流程代理程序,核心流程如下:
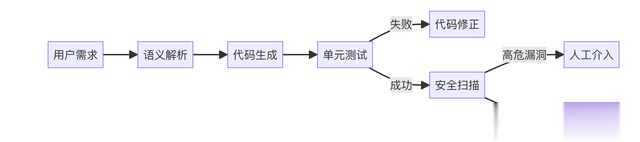 3.2 Go实现要点
3.2 Go实现要点3.2.1 任务调度器设计
type AgentScheduler struct { tasks chan Task ctx context.Context cancel context.CancelFunc } func NewAgentScheduler(ctx context.Context, concurrency int) *AgentScheduler { ctx, cancel := context.WithCancel(ctx) return &AgentScheduler{ tasks: make(chan Task, concurrency*2), ctx: ctx, cancel: cancel, } } func (s *AgentScheduler) Submit(task Task) error { select { case <-s.ctx.Done(): return s.ctx.Err() case s.tasks <- task: return nil } }3.2.2 资源隔离机制
容器化执行:通过containerd启动轻量级沙箱,限制CPU/内存资源文件系统隔离:使用tmpfs挂载临时目录,防止敏感数据泄露网络策略:通过netfilter限制代理程序的出站连接四、技术选型建议与未来趋势4.1 适用场景矩阵维度
Go语言优势场景
建议备选方案
并发规模
>1000并发实例
Python(asyncio+uvloop)
计算密集型任务
轻量级数据处理(如JSON解析)
Rust/C++(极致性能场景)
机器学习集成
调用远程API形式的推理服务
Python(TensorFlow生态)
部署环境
边缘计算节点、低功耗设备
Node.js(Bun运行时)
4.2 Go语言的局限性尽管Go在代理程序开发中优势显著,但其技术特性决定了以下场景需谨慎评估:
4.2.1机器学习生态的局限性
Go语言在深度学习领域的直接支持较弱:
主流框架(如TensorFlow/PyTorch)原生接口为Python/C++,Go需通过CGO或HTTP API间接调用数据预处理库(如Pandas)、模型训练工具链生态不完善适配策略:
采用“Go主程+PythonWorker”架构,通过gRPC实现任务分发轻量级模型可使用Go原生推理库(如gorgonia、tinygrad)4.2.2高性能计算场景的性能瓶颈
在以下场景中,Go的性能可能不及系统级语言:
高频次内存拷贝操作(如视频编解码)深度优化的数值计算(如加密哈希算法)内核级驱动开发数据对比:
任务类型
Go执行时间
Rust执行时间
性能差异
SHA-256哈希计算
120ms
45ms
2.7倍
10万次锁竞争
80ms
15ms
5.3倍
替代方案:
对性能敏感的模块使用Rust实现,通过WebAssembly集成采用“Go协调+Native计算”的混合架构4.2.3错误处理的工程成本
Go的显式错误处理机制(if err != nil)虽提升代码健壮性,但可能增加开发成本:
多层级函数调用需逐层传递错误,代码可读性下降缺乏异常捕获机制,复杂逻辑需手动管理错误上下文优化实践:
使用github.com/pkg/errors实现错误堆栈追踪定义统一的错误处理中间件,减少样板代码通过代码生成工具(如errgen)自动生成错误处理逻辑4.3 发展趋势展望与AI框架的深度整合:Go社区正推动gorgonia等库的发展,尝试在代理程序中嵌入轻量级神经网络无服务器化部署:通过WebAssembly(Wasm)实现代理程序的按需启动,降低冷启动延迟量子计算集成:利用Go的并发模型探索量子-经典混合计算任务的调度策略五、结论Go语言凭借轻量级并发、确定性取消机制等特性,成为代理程序开发的最优通用解,尤其适合高并发、长生命周期的业务场景。尽管在机器学习深度集成、极致性能优化等领域存在局限,但其工程效率与生态成熟度仍使其在多数场景中具备不可替代性。
技术选型的核心在于场景适配:若需深度整合AI框架或实现硬件级优化,可采用混合架构;若以快速迭代和系统稳定性为目标,Go语言仍是首选。随着代理程序向智能化、边缘化方向发展,Go的跨平台能力与简洁语法将进一步巩固其技术底座地位。