导读 在搜索/推荐领域,业界常用的多场景多目标建模方法通常采用部分共享参数结合部分独有参数的一类结构,例如经典的 MMoE+Task Tower,虽然有效,但在如今精排模型越来越复杂的趋势下,现有的建模范式存在两个主要问题:
(1)场景和目标信息与模型主体结构(特征交叉部分)的交互有限;
(2)场景和目标难以统一建模。
基于上述问题,字节抖音搜索团队提出了一种全新的多场景多目标建模思路——MDL。该方法受 LLM 通过“Prompt”来处理下游任务的启发,尝试对场景、目标这类多分布信息通过 Token 化表达,将其视作 LRM(Large Recommendation Model)的“Prompt Token”,通过设计的一系列交互方式实现了多场景多目标的统一建模和预估。由于 Token 化的形式可以更充分和更灵活的与其他信息交互,显著提升了多场景多目标的预估效果,实现了抖音搜索业务指标与用户体验的双重提升。
主要内容包括以下几个部分:
1. 研究背景
2. 方法简介
3. 实验结果
4. 总结与展望
分享嘉宾|王哲
内容校对|郭慧敏
出品社区|DataFun

论文:https://arxiv.org/abs/2602.07520
关键词:排序模型、多场景建模、多目标建模
01研究背景在真实的推荐/搜索系统中,主精排模型往往是一个多分布预估模型,需要服务于多个业务场景和多个业务目标,一般场景的数量在数个到数十个不等,预估任务数量也在数个到数十个不等,比如短视频业务常预估的点击、点赞、收藏、分享等。在不同的场景下用户存在不同的心智和诉求,进而表现出不同的用户行为,体现在算法层面的则是多种数据分布的混合,因此对于精排模型来说,如何合理的建模这些多分布差异的数据,能用一个统一的模型服务于复杂的多场景业务和多目标预估,是一个有价值有挑战的课题。
针对多场景多目标预估,业界经典的建模方式主要采用多 Expert 结合多 Tasknet 的方案,通过对不同的目标和场景路由不同的 Expert 信息来建模分布差异,最后通过特定场景的 Tasknet 作为最后的输出,一些进阶的工作也都在围绕这套建模范式做进一步升级,也取得了一定效果突破。但这类方法在随着算法模型日益复杂和业务逻辑日益复杂的背景下,逐渐暴露出新的问题:
Limitation in scaling capability:受 LLM Scaling Law 的启发,现有的一些工作通过堆叠高效的特征交叉结构成功验证了推荐模型的 Scaling Law,取得了不错的效果收益,这种建模范式也在逐渐成为主流,根据相关公开资料,部分头部大厂核心场景的精排模型 Dense 参数量基本都能落地 1B 左右的规模,百倍于传统的推荐模型。在这种背景下传统多场景/多任务方法通常只作用于模型的“浅层”(如输出层的 Tower 或中间的 Gate),导致巨量参数无法感知到场景和任务的差异,参数利用率极低 。Difficulty in uniformity modeling:多场景建模主要建模输入分布的差异,而多任务建模主要建模输出分布的差异,由于建模特性的差异,之前的多场景多目标建模工作通常对这两部分单独设计,难以通过一套方法统一建模。随着业务的发展,当要建模的场景和任务数量逐渐新增时,这种建模方式注定是不方便的。为了解决这一问题,本文主要受到 LLM 处理下游任务方式的启发,提出了一种全新的多场景多目标建模思路,称之为 MDL(Multi-Distribution Learner)。MDL 的核心思想是“Tokenize-and-Interact”,其灵感来源于大语言模型(LLM)的 Prompting(提示词) 范式,在 LLM 中,一段 Prompt Token 就可以激活模型内部海量的知识,灵活地处理好下游任务。MDL 认为,场景和任务信息也可以被视为一种“提示标记(Prompt Tokens)” 。通过将场景、任务与原始特征全部“Token 化”,MDL 让这些分布信号能够像特征一样,从底层开始参与每一层的计算,从而彻底激活模型的巨量参数空间。同时将场景和任务的分布信息都以Token的形式组织,进一步统一了两者分别建模输入分布差异和输出分布差异的特点。
02方法简介具体来说,本文提出了 MDL 模型,整体架构如下图所示,主要包括:统一信息的 Token 化和领域感知的 Token 交互两部分。
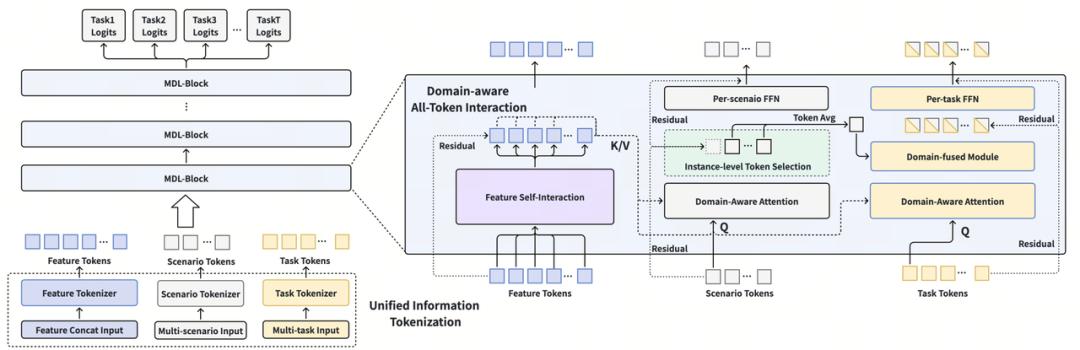 1. 统一信息的 Token 化(Unified Information Tokenization)
1. 统一信息的 Token 化(Unified Information Tokenization)这一步的目标是将特征信息、任务信息和场景信息转换为基础的“Token”表达,来消除不同类型数据的表示壁垒,将所有输入投影到同一个潜在向量空间,具体来说 Token 就是一组固定数量固定维度的隐层向量。
特征信息 Token 化 (Feature Tokenization)将输入的用户特征、物品特征、序列特征和交叉特征等,通过 Embedding Layer 或者序列处理模块转换为对应的特征 embedding ,然后参照 RankMixer[1]依据特征语义信息进行分组,让相关的特征信息 embbedding 分配到同一个组得到 组 embedding ,然后为每一组 embedding 通过 FFN 映射为固定的维度:
最后得到特征 Token 。
任务&场景信息 Token 化(Task&Scenario Tokenization)任务和场景信息的 Token 化方式基本一致,这里以场景信息的 Token 化为例来说,场景 Token 的作用是表达各个预估场景的信息,其主要由输入特征和非线性变换两部分组成:
输入特征:包含两部分(1)重要特征的新 Emb 参数 ,例如 user id,video id 等,和输入给特征 Token 的原始特征是一样的,但是用了新的 Emb 参数;(2)场景相关的特征 Emb ,例如对应场景下的用户行为序列。这部分输入保证了初始输入信息的丰富度和不同场景之间输入的差异性。非线性变换:将两部分输入特征 concat,然后通过一个非线性的 FFN 网络转化为固定维度:对于每一个场景 Token ,其使用的 FFN 参数是不一样的,为了增强不同场景 Token 的表达能力和差异性。最后获得对应的场景 Token,其中 是对应模型需要建模的场景数量,+1 代表一个额外的 Gloabl Token 被所有场景共享。
类似的可以得到对应的任务 Token 来表达不同的待预估目标,其中 是对应模型需要预估的任务数量。
2. 领域感知的 Token 交互(Domain-aware All-Token Interaction)在得到了初始的特征 Token、场景 Token 和任务 Token 后,本文进一步设计这三类 Token 之间的交互形式,来实现更为高效的多场景多目标建模。
特征 Token 自交互特征 Token 自交互为为推荐模型提供基础的信息表达能力,本文沿用了 RankMixer 中的 TokenMixing 和 Pertoken FFN 结构:
其中特征 Token 的自交互部分也可以被其他特征交互模块替代。
场景/任务 Token 与特征 Token 交互这部分内容主要是实现场景信息和任务信息对于参数量极为丰富的特征信息的利用,由于对任务信息和场景信息从底层进行了 Token 化,因此可以自底向且上逐层的与特征信息进行充分交互,来缓解之前仅通过一组 gate 值对复杂网络参数进行差异化利用困难的问题。具体来说本文设计了 Domain-aware Attention 机制,通过将场景/任务 Token 作为 Query,特征 Token 作为 Key/Value 进行 cross-attention 交互:
具体的任务 Token 和场景 Token 可以自适应的根据自身的数据特性选择性的聚合特征 Token 的丰富信息,实现不同任务以及不同场景的差异化建模,同时由于从底层做了 Token 化,因此这部分交互可以叠加多层,逐层的 cross-attention 交互保证了对复杂结构的信息利用。
场景 Token 与任务 Token 交互这一部分的交互主要为两者信息的融合,即在 Token 化的背景下实现特定目标在特定场景下的模型差异化预估。两者的交互主要由 Domain-fused Module 控制
其主要包含两步:(1)样本粒度的场景Token选取;(2)场景信息与任务信息的融合。首先根据样本对应的场景信息从 中选取对应的场景 Token ,以及 global token ,假设模型需要建模 个场景,对于每一条样本,其必然属于其中的某一个或某几个场景(场景存在交叉的情况),根据这个信息做场景 Token 的选择。对于选取的场景 token,对其信息进行聚合,具体信息聚合采用了 mean pooling 的方式:
后续利用 来表达样本对应的场景信息。
接下来将聚合得到的场景 Token 信息 融合到任务 Token 上,对于每一个任务 Token ,本文直接采用 sum pooling 的方式融合两者信息:
通过这种 Token 化的信息融合,解耦了场景与任务之间的强关联,可以灵活地做任何场景与任务之间的组合。
逐层的执行这三类 Token 交互,并通过残差连接叠加多层。最后选取任务 Token 的最后一层输出 外接一层 Logits Layer 作为模型不同预估目标的输出。
更多的技术细节可以参考论文原文:https://arxiv.org/abs/2602.07520
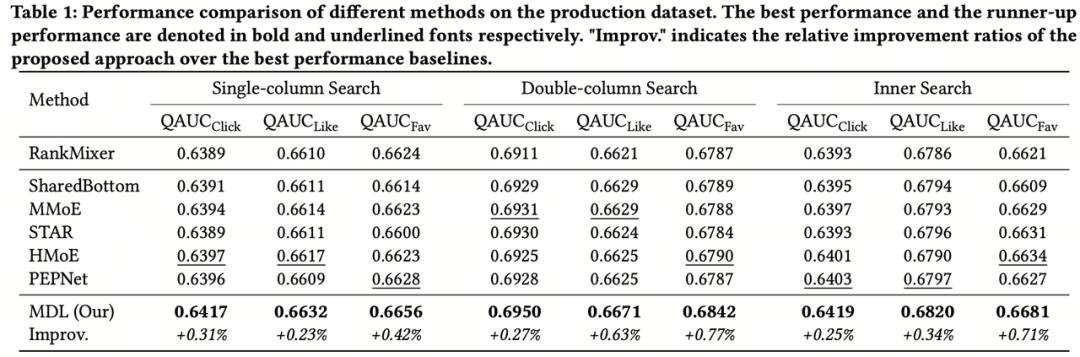
03实验结果1. 效果对比在抖音搜索业务上进行验证,抖音搜索精排模型包含三个主要建模场景和数十个预估目标。这里列举了三个场景下几个重要预估目标的效果,可以看到相较于一些多场景多目标建模方法,MDL 都取得了相对显著的效果提升。尤其是在一些数据相对稀疏的场景和目标上取得了更为明显的提升。
 2. 消融实验
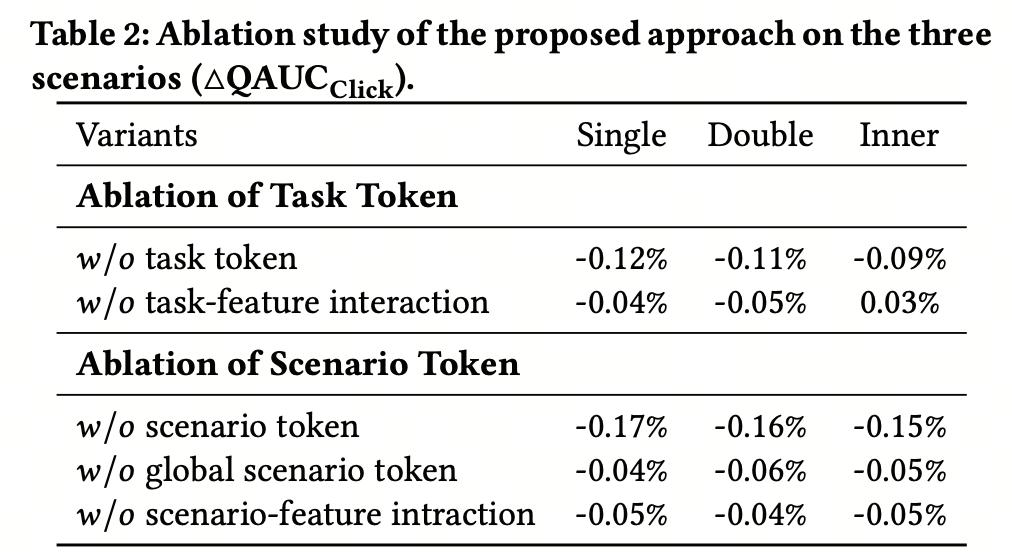
2. 消融实验MDL 消融了相关 Token 化的思想与 Token 交互的设计,如下表所示,消融实验表明了场景和任务 Token 化表达的有效性和设计的 Token 交互方式的有效性。
 3. Scaling 实验
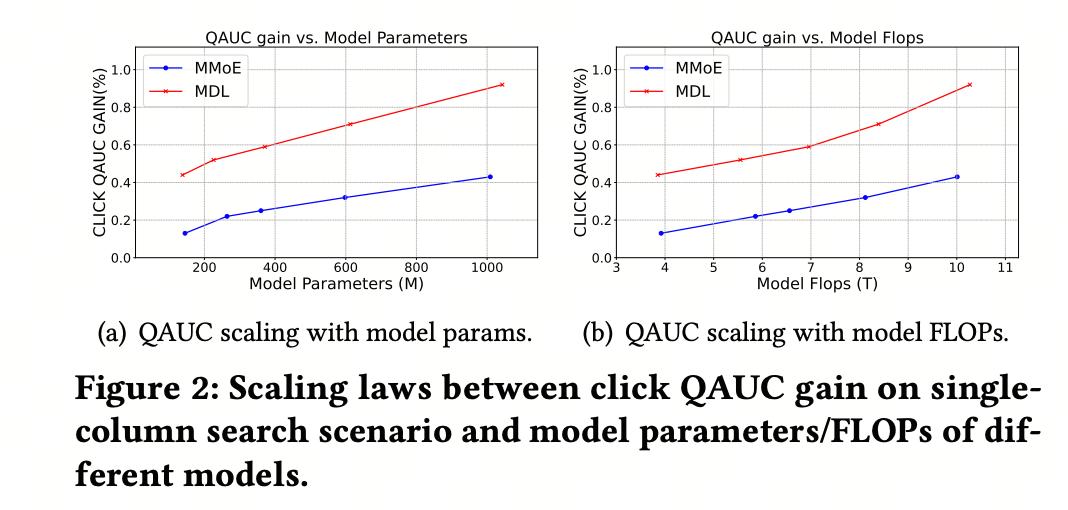
3. Scaling 实验通过对比 MDL 和经典的 MMoE 结构,在不同不同模型参数量和 FLOPs,MDL 也都显著优于基线,同时随着模型参数量以及 FLOPs 的增长,MDL 的提升效果更加明显。
 4. 在线 A/B 指标
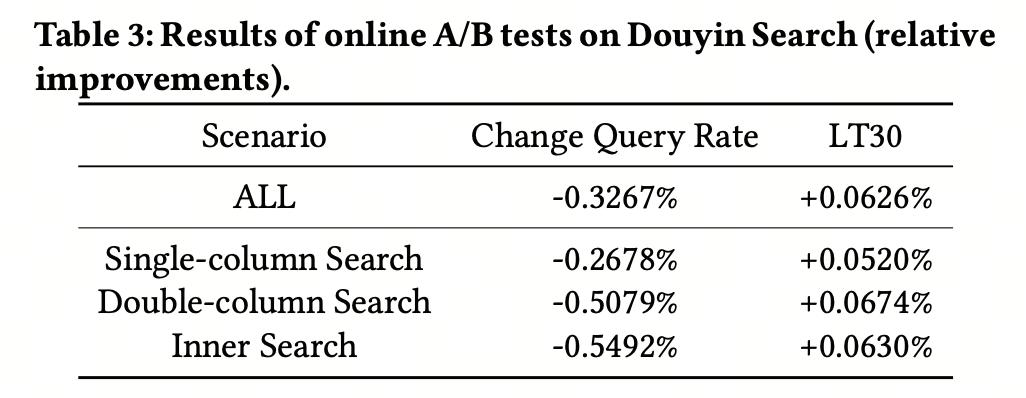
4. 在线 A/B 指标在线取得了抖音搜索整体 LT30 +0.0626%,换 query 率 -0.3267% 的显著提升。并且分场景也均为正向。
 04总结与展望
04总结与展望在推荐模型日益复杂化的背景下,本文提出了一种全新的多场景多目标建模思路,可以进一步提升下游多场景多目标的预估效果,并可以做到场景和目标这两个维度的统一建模。其核心思想是受 LLM 通过 Prompt Token 处理下游应用任务的启发,本文通过对多场景和多目标进行 Token 化建模来加强与主体模型的交互,取得了一定的效果。类比 LLM,本文的愿景是希望多场景/目标信息扮演的是不同 Prompt 信息,通过较少的代价,可以灵活且充分的激活推荐大模型的潜在能力,为后续多场景多目标的建模打开了一种新的思路。
我们是抖音搜索算法团队,是国内当前最领先的图文/短视频搜索业务,我们正在热招 社招 / 校招 / 实习 的同学,共同打造下一代 AI 搜索引擎。base 地:北京/杭州/上海我们的技术方向:
排序大模型:探索个性化大模型、多模态大模型、生成式大模型、百万超长序列等前沿技术,不断突破技术边界,重新定义下一代搜索大模型范式,让排序更精准、更贴合用户需求。机制策略:深耕 LTR 等排序策略、多业务重混排、流量分发机制等,优化搜索全链路效率,平衡多场景业务需求与用户体验,实现业务价值与用户价值的双赢。召回技术 / 相关性技术 / 生态优化 等欢迎加入我们,联系方式:mushanlei@bytedance.com / hsy-24-6666(微信)/ wushikang@bytedance.com,邮件名:[社招/校招/实习][方向][base地][姓名][学校]
以上就是本次分享的内容,谢谢大家。