Grace: Language Models Meet Code Edits
Priyanshu Gupta∗,Avishree Khare∗†,Saikat Chakraborty,Sumit Gulwani,Arjun Radhakrishna,Gustavo Soares
引用
Priyanshu Gupta, Avishree Khare, Yasharth Bajpai, Saikat Chakraborty, Sumit Gulwani, Aditya Kanade, Arjun Radhakrishna, Gustavo Soares, and Ashish Tiwari. 2023. Grace: Language Models Meet Code Edits. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023). Association for Computing Machinery, New York, NY, USA, 1483–1495. https://doi.org/10.1145/3611643.3616253.
论文:https://arxiv.org/abs/2305.14129
摘要
开发者为了修复错误或添加功能而频繁编辑代码。因此设计有效方法来预测代码编辑非常有意义,同时具有挑战性,因为代码编辑的多样且难以理解开发者的意图。我们通过赋予预训练的大型语言模型(LLMs)相关先前编辑的知识,提出了一种名为Grace(基于相关代码编辑的条件生成)的方法。LLMs的生成能力有助于处理代码变化的多样性,而基于先前编辑的条件生成代码有助于捕捉潜在的开发者意图。我们在零样本和微调设置中分别评估了两个知名的LLMs,codex和CodeT5。实验表明,Grace显著提升了LLMs的性能,生成的代码建议比当前最先进的符号和神经方法更准确。
1 引言
开发者在维护和修改现有代码上花费的时间远多于编写新代码。由于软件维护成本高,集成开发环境(IDE)提供了工具来支持开发者重构代码、修复缺陷、适应环境变化或添加新功能。代码编辑建议是其中一个理想的功能,利用开发者正在编辑的代码位置和上下文来生成建议的编辑。
研究人员提出了从源代码仓库中学习编辑模式的方法来自动化代码编辑建议,但这些方法有两个限制:它们只关注单个编辑,并且无法生成新代码。与此不同,神经语言模型能够生成新代码。例如,codex和CodeT5这样的预训练大型语言模型(LLMs)在代码生成方面表现出色,但它们在没有先前编辑知识的情况下无法推断开发者的意图。
我们提出了一种新方法,称为基于关联代码编辑的生成(Grace),它通过考虑先前的、相关的编辑来预测代码编辑。我们的方法与现有的符号或神经方法相比有显著优势,因为它可以利用LLMs的强大能力来生成新代码,而不仅仅是重用现有代码。
我们的实验使用了overwatch和c3po的代码编辑基准,并在zero-shot和微调设置中展示了Grace的优势。我们使用codex-davinci模型作为基线LLM,并在微调设置中使用CodeT5模型。结果显示,与未使用关联编辑的预训练模型相比,使用关联编辑可以显著提高模型预测下一个编辑的能力。在overwatch和c3po数据集上,我们分别获得了17%、30%和7.45%、9.64%的改进。
我们做出了以下贡献:
我们考虑了一个实际重要的软件工程问题——预测代码编辑,并提出了Grace,这种新颖的方法,利用强大的LLMs通过将其条件化在先前的编辑上来预测代码编辑。通过在两个数据集上的实验,展示了Grace在zero-shot或微调设置中显著提高LLMs的性能。Grace优于专门设计用于处理代码编辑的最新符号或神经方法。我们进行了实验,全面评估了Grace,并报告了从中获得的发现。2 技术介绍
2.1 激励示例
我们通过一个实际的代码开发场景来说明Grace的激励模式,并讨论它与现有方法的不同。我们考虑一个开发者正在重构代码,目标是使用特定的异常处理类。开发者首先进行了一次编辑,将Exception替换为SerializationException。目标是预测开发者接下来会进行的编辑,以便达到最终的代码版本。
预测代码编辑并非易事,因为需要考虑代码的上下文信息。例如,开发者可能需要导入一个尚未导入的命名空间。我们的关键是,预测应该基于过去的相关编辑。在本例中,我们通过观察如何从版本V1创建版本V2来预测版本V2的更新。

图1:开发者执行编辑1,2,从他们的代码版本V1到版本V2。这个编辑作为一个相关编辑,有助于预测从版本V2到V3所需的编辑2,3。
现有的方法,如c3po和overwatch,要么无法处理需要新标记的情况,要么无法匹配现有的学习模式。而代码的LLMs(大型语言模型)作为代码完成工具,提供了生成新标记的能力。我们讨论了没有相关编辑的LLMs和带有Grace的LLMs在预测代码编辑时的表现。没有相关编辑的LLMs在预测时可能会出错,而带有Grace的LLMs能够更准确地预测所需的代码更新。
表1:对图1示例的不同方法进行比较
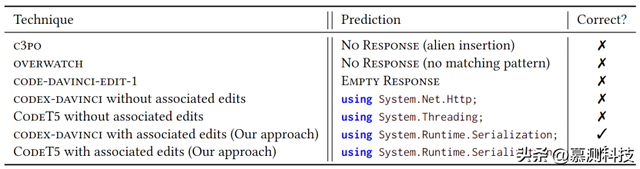
我们发现,相关编辑对于提高编辑预测的准确性非常有帮助。通过在代码生成模型的基础上构建代码变化预测模型,我们不仅能够扩大编辑预测的范围,还能在某些基准测试中超越现有方法。
2.2 相关代码更新
我们在本节中定义了相关代码更新任务。相关代码更新任务的灵感来源于EditCompletion任务和编辑可能性预测任务。
设为源代码文件的一系列版本。编辑是两个版本vi和vj之间的差异。我们将视为一个函数,它在输入时返回,即。
此外,相关编辑Δi是,对于某些0 ≤ j < k < n。
给定m个相关编辑, , ..., 以及版本,以及在中的位置L,相关代码更新任务是在仅假设中的位置L被更新的情况下预测版本vn。因此,我们希望模拟概率P(| L, ,, , ..., )。
首先,n − 1个版本不一定与底层源代码文件的历史匹配。实际的历史版本可能不同,实际上,在上述表述中,用于预测任务的不是完整版本本身,而是编辑。这里唯一重要的是当前版本vn−1。此外,m个过去的编辑集甚至不需要是所有时间上连续编辑的完整集合;它们可能是迄今为止执行的编辑的一个子集。因此,不一定非得是。
其次,编辑被允许在空间上彼此相距很远,也与版本vn−1中的目标位置L相距很远。虽然修改靠近目标位置L的编辑很可能被包含在编辑集m中是有用的,但距离L较远的编辑也可能相关。与EditCompletion任务不同,我们不对编辑的空间局部性做出任何假设。
子问题假设
在构建端到端工具时,我们忽略了三个关键的子问题:编辑定位、编辑粒度和相关编辑识别。我们假设用已有解决方案来处理这些问题。
编辑定位:我们需要确定开发者应在哪里进行编辑(位置L)。例如,在IDE中,光标位置指示了开发者想要更改的地方。我们也可以建立模型,预测基于先前编辑的下一个编辑位置。在overwatch中,位置选择基于特定模式是否与代码匹配。
编辑粒度:这个问题涉及定义什么是一次“编辑”。我们假设有方法来确定何时一个局部代码更改构成一个编辑。例如,两个版本间所有能成功解析的更改可以视为一个编辑。或者,我们可以将提交中空间上相近的所有更改视为一个编辑。
相关编辑:我们要找出历史编辑中哪些对预测当前版本中特定位置L的更改最有帮助。空间上接近目标位置的编辑很可能是相关的。同样,时间上接近的编辑(近期发生的)也可能是相关的。我们可以通过时间和空间的接近性来确定一组可能相关的编辑。为了预测目标位置的更新,我们可以分析时间上接近的编辑来理解开发者的意图,空间上接近的编辑来帮助理解目标代码片段。我们还可以根据编辑的语法结构和它们共同出现的可能性来选择相关编辑。我们的目标是展示,即使这些编辑是启发式生成的,它们在预测相关代码更新时也非常有用。
相关问题表述
现有的自回归语言模型(LLMs),如GPT-3和Codex,预测给定提示的补全。如果提示包含工件的当前版本,那么这些LLMs预测的文本旨在附加到以生成新版本。这些模型依赖于变更位置L附近空间的文本来进行预测。这些模型是在建模概率P( | ),与我们正在考虑的问题不同。我们展示了相关的代码更新表述提供了一种简单但有效的方法来提高LLM在软件开发任务上的性能。
EditCompletion任务被形式化为研究P(2,3 | L, v2, 0,1, 1,2),其中两个给定的编辑是在当前位置的空间附近进行的编辑,一个在当前位置之前,一个在之后。EditCompletion任务不考虑可能在空间上较远的相关编辑。我们的问题表述是对EditCompletion问题的概括,但方法不同。
编辑可能性预测问题明确考虑了研究P(| , , ..., ),但它使用P(| , , ..., )作为估计前者的一种方式。这个问题与相关的代码更新问题有两个不同之处:它包括作为更大问题一部分的找到需要编辑的位置L的子问题;它考虑整个编辑历史作为一个有序序列(以自回归的方式),而我们专注于一组相关的编辑。
2.3 利用相关编辑
预训练语言模型
目前有许多预训练语言模型,它们在大量网页数据上训练,将数据视为标记序列,适合表示自然语言文本。这些模型即使没有针对特定任务的训练,也能执行多种任务,展现了零样本任务迁移的能力。然而,它们在处理代码时效果不佳,因为代码有严格的语法和语义要求。我们设计了专门的代码表示方法,并训练了相应的模型。随着预训练模型规模的增长,它们的跨任务性能和少样本学习能力得到了提升,成功应用于理解、操作或生成代码的任务。
提示大型语言模型
我们尝试了不同的prompt设计,并选择了一种用于实验。codex模型家族包括完成、插入和编辑三种变体。完成模型预测跟随提示的代码;插入模型除了提示外,还考虑后缀提示;编辑模型接收需要编辑的字符串和编辑指令。我们选择使用插入模型进行代码更新任务,因为它允许在目标位置之后包含代码,并且不需要编辑指令。

图2:与代码更新任务相关的Grace提示
我们设计的Grace提示包括当前文件版本、需要更新的代码位置和相关编辑。每个编辑分为四个部分:未更改的前缀、被替换的部分、新替换的部分和未更改的后缀。
插入模型预期预测在当前编辑标签下的<After>和</After>之间的字符串。提示设计类似于少样本学习,其中包含任务的示例。本文旨在比较使用相关编辑与不使用时预测代码更新的效果,并探讨是否可以将相关编辑更新任务视为代码更新任务的少样本提示。

图3:当未使用相关编辑时的提示。
微调大型语言模型(LLMs)
CodeT5-base是一个预训练的Transformer模型,原本在包含六种编程语言源代码的CodeSearchNet上训练,后加入了BigQuery的C/C#数据集。我们对模型的不同变体进行了微调,以预测代码编辑。每个变体有两个版本:一个结合相关编辑,另一个仅使用代码当前版本。微调使用相同的数据集和模型权重,区别在于数据准备方式。微调数据准备时,我们使用Grace提示格式,添加特殊标记以形成掩码跨度预测任务。在不使用相关编辑的情况下,我们用哨兵标记替换<CurrentEdit>下<After>和</After>之间的代码内容,让模型预测这些掩蔽部分。
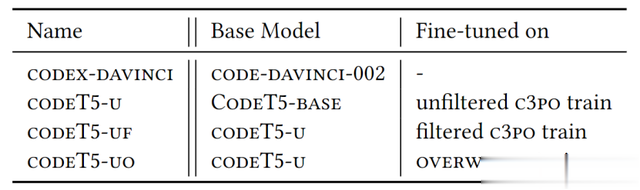
表2:我们实验中使用的模型。
3 实验评估
3.1 实验设置
我们的实验使用了两个数据集:c3po和overwatch。c3po数据集由53个热门 GitHub仓库的所有提交抓取而成,每个提交中的编辑构成一个示例。任务是预测编辑后的代码,基于编辑前后的代码及相关编辑。c3po数据集被分为训练、验证和测试集,分别包含39.5K、4.4K和5.9K个基准测试。overwatch数据集则从IDE会话中编辑的源代码文件版本收集而来,分为两个时期的版本,用于学习常见的编辑序列模式,并在第二个时期生成代码建议。
我们使用了两个模型:code-davinci-002(codex-davinci)和CodeT5-base。codex-davinci是OpenAI gpt-3.5系列的一部分,用于基于相关编辑进行预测。CodeT5-base由Salesforce提供,经过微调以适应c3po和overwatch数据集。我们使用两步微调过程:首先在未过滤的c3po数据集上微调,然后在过滤后的c3po和overwatch数据集上进一步微调。
实验设置包括使用OpenAI公共API进行codex-davinci模型的推理,以及在配备16个AMD MI200 GPU的虚拟机上进行CodeT5模型的微调。我们使用精确匹配作为评估指标,即预测与真实值在语法上匹配(忽略空格)。在所有结果中,我们报告Top-1预测的精确匹配率。
表3:用于微调和测试的数据集

3.2 Grace对预测能力的提升
RQ1:提供相关编辑信息是否能提高代码更新预测的准确性?
为了回答这个问题,我们在c3po和overwatch测试集上分别测试了codex-davinci和CodeT5,一次是在提示中包含相关编辑,一次是不包含。
表4:相关的编辑改善了代码预测

结果:表4展示了在不同数据集上使用不同模型时,包含和不包含相关编辑时获得的完全匹配(Exact Match)结果。当在c3po数据集上提供相关编辑时,codex-davinci的完全匹配率比不提供时有30%的绝对增长,而在overwatch数据集上大约有17%的绝对增长。经过微调的CodeT5模型在两个数据集上都显示出大约10%的完全匹配率的绝对增长。我们还尝试了其他模型(包括来自gpt3和gpt-3.5系列的其他OpenAI模型)和不同的提示风格(例如,使用C#注释而不是标签来区分“之前”和“之后”的版本),在每一种情况下,完全匹配率至少有10%的绝对增长——通常这个增长要高得多。
Result1:将代码预测条件化在相关编辑上是有帮助的,这一点在不同模型和测试数据集上都得到了验证。
3.3 编辑相关性的重要性
在代码更新问题中,我们关注相关编辑对代码预测的影响。我们之前提到,选择相关编辑应基于它们与待更新代码的相关性。为了探讨这一点,将其与“少样本提示”相比较。
RQ2. 相关编辑对于代码更新预测是否重要,或者仅仅是作为代码更新任务的少样本示例?
表5:不太相关的编辑会降低预测准确率:对不同相关编辑的Codex-Davinci在过滤后的C3PO测试集上的表现
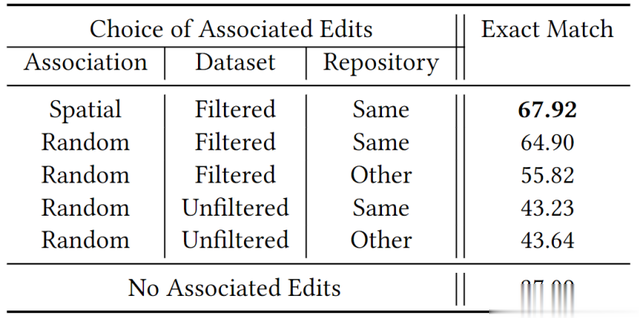
我们发现,当提示中包含与目标代码空间上接近的过滤编辑时,精确匹配率达到了67.92%。然而,当我们随机选择编辑时,性能有所下降。特别是,从其他仓库随机选择过滤编辑,性能下降到了55.82%。而从未过滤的编辑中随机选择,无论编辑来自同一仓库还是不同仓库,精确匹配率大约保持在43%。这表明,过滤步骤实际上去除了某些类型的编辑,如纯插入或删除,或导致代码无法解析的编辑,这降低了随机选择的未过滤编辑与目标编辑的相关性。
我们还发现,从目标编辑所在仓库以外的仓库选择编辑,也会降低编辑的相关性。这是因为同一仓库中的编辑可能使用相同的概念、类、方法和编程实践。尽管如此,使用其他仓库的未过滤编辑(43.64%的精确匹配率)仍然比完全不使用相关编辑(37.09%)要好,这可能是因为大型语言模型(LLM)利用了其少样本学习能力。
结果2:相关编辑在预测目标编辑中起着至关重要的作用,随着编辑对目标编辑的相关性降低,精确匹配度也会下降。
3.4 预训练模型优于定制模型
在处理代码和代码编辑时,预训练的语言模型(如codex和gpt3)和其他模型(如CodeT5)使用字节对编码(BPE)将代码分词,然后以标记序列的形式表示代码,这与自然语言的处理方式相同。然而,有些研究提倡使用定制的代码表示方法,这些方法能够捕捉代码的解析结构和编程语言的语义。
c3po数据集的引入论文也使用了预训练模型的空间编辑,但他们开发了一个定制模型,使用以代码为中心的表示方法来处理代码编辑。
RQ3. 我们基于大型语言模型的方法与基于定制神经模型的c3po方法在相关代码更新任务上相比如何?
表6:与C3PO的比较

我们比较了c3po定制神经模型与codex-davinci和微调后的CodeT5在过滤后的c3po测试集和overwatch测试集上的表现。结果显示,codex-davinci和微调后的CodeT5在这两个数据集上的表现都显著优于c3po模型。c3po模型在c3po测试集上的准确率为53.2%,而codex-davinci和微调后的CodeT5都取得了更好的成绩。特别是,codeT5-uf模型的精确匹配率达到了81.83%,远高于c3po模型的53.2%。在overwatch数据集上,c3po模型的最佳配置只能达到10.5%的精确匹配率,而codex-davinci、codeT5-u和codeT5-uo的表现都显著更好。
在未过滤的c3po测试集上,c3po模型没有报告结果,因为它包含了一些超出其技术范围的基准测试。Grace能够处理这些基准测试,评估显示,codex-davinci的精确匹配率为43.47%,而codeT5-u在使用Grace时为57.3%,不使用时为45.30%。这些结果表明,未过滤的基准测试比过滤的基准测试更具挑战性。
我们还对涉及外来插入的基准测试进行了评估。在这些测试中,使用Grace的codeT5-u的精确匹配率为17.6%,而不使用Grace的为10.28%。codex-davinci模型在使用Grace时的精确匹配率为17.37%,不使用时为10.67%。这表明,基于相关编辑的条件化有助于处理困难的基准测试。
尽管c3po模型的参数量较小(750K),但预训练的大型模型(如codex-davinci和CodeT5)可以快速微调或进行提示工程,而无需大量的训练数据。此外,预训练模型的应用范围更广。
结果3:预训练的语言模型可以调整以产生比定制的c3po模型更高的精确匹配率,用于相关的代码更新预测。
3.5 时间编辑预测
时间编辑预测问题适合使用Grace。overwatch是这一领域的先进技术,它处理的是与相关编辑预测不同的问题。overwatch的输入是IDE的精细版本历史,记录了源代码文件的每个版本。这些编辑历史非常详细,记录了每次按键操作。例如,开发者输入变量名时,编辑历史会记录每个中间版本。overwatch通过这些版本历史训练,生成一系列编辑序列模式(ESPs),在IDE运行时预测下一个编辑。ESPs的任务是识别版本历史中的相关编辑序列,并基于这些序列预测下一个编辑。
RQ4. 我们的基于LLM的方法能否与overwatch的时间相关编辑识别结合使用?与overwatch的符号编辑预测组件相比如何?
表7:与Overwatch的比较

我们在399个版本历史(超过200,000个版本)上运行overwatch,收集了ESPs能识别的相关编辑,形成了1048个案例的数据集。在训练时,overwatch从682个版本历史中识别出9.9K个编辑序列,这些序列是ESPs的基础。我们用这些数据进一步微调了codeT5-u模型。在1048个测试案例中,除了codeT5-u外,我们的所有模型在预测性能上都比overwatch的预测组件高出约10%。
结果4:我们的基于LLM的技术,结合像overwatch这样的系统,创造了神经符号解决方案,比纯粹的符号技术更擅长预测下一个编辑。
3.6 定性分析
我们的实验揭示了两个关键点:首先,大型语言模型(LLMs)能够预测现有技术无法处理的代码编辑;其次,结合相关编辑可以提升LLMs预测代码编辑的性能。以下是对这些发现的深入分析。

图4:用户在第3行添加了BadRequest错误代码,并移动到第5行,我们应该预测插入NotFound。

图5:用户将第5行的“ex”替换为“ex.Output”,并移动到第3行,我们应该预测将“ex”替换为“ex.Input”。
与现有技术的比较表明,LLMs的生成能力在预测插入方面具有优势。例如,c3po无法插入未在上下文中发现的标记,而overwatch可能无法预测由于缺失映射而导致的不完整模板。LLMs通过预训练和提示设置,可以访问广泛的标记,不受这些限制。这使得LLMs能够预测出新标记,如在添加HTTP错误代码的场景中所示。
LLMs在提示中访问局部空间上下文的能力也是其优势之一。overwatch依赖于从编辑序列中学到的模式,但有时这些模式过于通用,无法准确反映目标编辑周围的上下文。LLMs通过预训练,能够理解标识符的语义,从而预测出基于上下文语义的编辑模式。
使用相关编辑的好处包括:
明确开发者的编辑意图:相关编辑为开发者下一步可能进行的编辑提供了强烈信号,有助于LLMs提高预测的准确性。强调相关代码上下文:LLMs能够处理大量标记,但无关信息会影响模型的注意力。相关编辑帮助模型专注于正确的代码部分,提高预测的准确性。提供编辑代码元素的信息:相关编辑包含了之前编辑中可能被删除或替换的变量信息,这对于理解目标代码位置的上下文至关重要。转述:吴德盛