李飞飞团队于 2009 年推出的 ImageNet 标志着人工智能发展转向了一种由数据驱动的范式。
这一包含数百万张标注图像的大规模数据集,不仅奠定了为计算机视觉领域发展的基础,也为深度学习打开了大门。
但如李飞飞所说,“数字世界需要三维表征,才能与现实世界融合”[1]。未来的人工智能不仅需要理解静态图像,还需要具备对动态场景和三维空间的理解能力。AI 必须走出柏拉图的洞穴,才能真正地与人类的生活环境和复杂情景相适应。
而这也正是李飞飞大力押注“空间智能”(Spatial Intelligence)的原因。
然而,现有的用于评估多模态大模型(large multimodal models,LMM)的数据集大多集中于单张图像或短视频片段的理解,通常持续时间从几秒到不超过三分钟不等。如果想让模型处理需要长期理解的任务,例如对长时间视频中复杂情景和因果关系的理解,这些数据集显然就并不够用了。
在这一背景下,斯坦福大学的李飞飞和吴佳俊所在团队提出了一个专为长时间视频与语言理解设计的基准数据集——HourVideo。
相关论文以《HourVideo:1 小时视频语言理解》(HourVideo: 1-Hour Video-Language Understanding)为题发表在预印本网站 arXiv 上 [1]。

图丨相关论文(来源:arXiv)
HourVideo 包含了 500 段来自 Ego4D 数据集的手动筛选的第一视角视频,这些视频时长从 20 分钟到 120 分钟不等,覆盖了 77 种日常活动场景,如烹饪、修理、打扫卫生等。
并且,为了全面评估多模态模型对长时间视频的理解能力,研究团队设计了一套全新的任务集,涵盖了感知、理解和推理的多个层面,以最大程度地考察模型的长时间依赖和多模态综合能力,包括:
1. 摘要生成:对长时间视频中的主要事件进行总结,要求模型能够提炼出视频的核心内容。
2. 感知任务:包括回忆和跟踪,测试模型能否回忆视频中提到的具体信息(如物体和人物),以及跟踪这些信息在视频中的变化。

图丨 HourVideo 针对不同任务的 MCQ 示例(来源:arXiv)
3. 视觉推理:分为空间推理、时间推理、预测、因果和反事实推理,考察模型能否理解视频中的空间关系、时间顺序,预测未来发生的事件,分析因果关系,并进行假设性的反事实推理。
4. 导航任务:包括房间到房间的导航和物体检索,测试模型在虚拟环境中导航并查找特定物体的能力。

图丨 HourVideo 针对不同任务的 MCQ 示例(来源:arXiv)
这些任务的设计旨在确保模型需要从视频的多个时间段中提取并整合信息,而不仅仅是通过短时间的观察来进行局部理解。
其中,每一段视频对应着约 26 个五选一的多项选择题,共 12,976 个。这些问题由人工和大模型共同生成,每个问题都经过了复杂的生成和筛选过程,以确保这些问题的设计能真正考察模型对长时间视频的理解深度。

图丨 HourVideo 数据集生成 Pipeline(来源:arXiv)
具体来说,在筛选出符合任务要求的视频后,研究团队先利用大语言模型根据视频内容生成了初步的问题模板。团队为每个任务设计了详细的问题原型,并利用 Ego4D 数据集中的叙述信息,将这些叙述转化为结构化的数据格式,以便 LLM 生成候选多项选择题。
候选题生成后,由人类专家进行审核和反馈,验证问题的有效性,并改正不准确的答案。整个专家标注过程耗时超过了 400 小时,以确保所有问题与视频内容保持一致,且不包含模糊或错误的信息。
之后,使用两个盲大模型对生成的问题进行回答,过滤掉那些无需观看视频即可轻易回答的问题,保证题目确实需要长时间视频的理解。
最后,再有人工对每个问题进行精细化修订,确保问题足够具有挑战性。比如把“相机佩戴者把钥匙放在哪里了”这样的宽泛问题改为更为精准的询问“相机佩戴者购物回家后把自行车钥匙放在哪里了”,从而增强模型的理解和推理难度。
此阶段由专家耗时超过 300 小时完成。整个生成过程通过多层次的质量控制,确保 HourVideo 数据集中的每一个问题都能有效评估多模态模型对长时间视频的综合理解能力。
在此之后,研究人员评估了多种多模态模型在 HourVideo 数据集上的表现,包括 GPT-4V、Gemini 1.5 Pro 和 LLaVA-NeXT 等。在实验中,研究团队以零样本的方式对这些模型进行评估。
为了避免问题间的信息泄露,又能提高评估效率,课题组选择分批对问题进行评估,每批包含与特定任务或子任务相关的所有问题。这种方式不仅比独立评估更高效,也能在一定程度上保证模型对每个问题的独立理解。
结果显示,即便是目前最先进的多模态模型,其表现也只是比随机猜测(20%)略好一点。
在各类任务的表现上,GPT-4V 和 LLaVA-NeXT 的平均准确率分别为 25.7% 和 22.3%,而 Gemini 1.5 Pro 虽然在长时间视频理解方面表现稍好,但其准确率也只有 37.3%。相比之下,人类专家的平均准确率高达 85.0%,这说明当前的多模态模型在长时间视频理解方面与人类之间仍然存在巨大差距。
由此见得,现有的多模态模型对长时间视觉信息处理能力的明显不足。
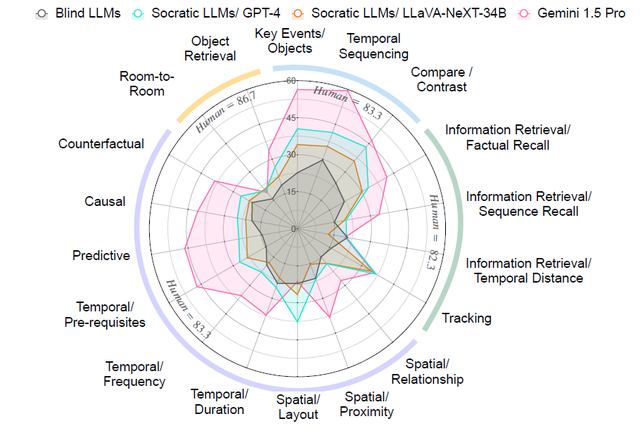
图丨 HourVideo 上不同多模态基础模型在不同任务/子任务中的表现比较(来源:arXiv)
而 HourVideo 数据集的设计正是为了填补这一空白,有望推动研究者开发出能够更好地理解长时间视频内容的多模态模型。
随着技术的不断进步,研究团队希望 HourVideo 能够推动开发出具备更强视觉理解能力的多模态模型,使其能够像人类一样处理长时间的视觉刺激,并在例如增强现实助手、具身智能体、互动视频平台等应用场景中发挥更大作用。
尽管 HourVideo 数据集在长时间视频理解领域迈出了重要一步,但研究团队也承认其仍有改进空间。未来的工作可以包括更广泛的视频来源,如体育视频和 YouTube 视频等,以进一步丰富数据集的内容。
此外,融入音频模态的支持也将是对多模态模型进行更全面评估的必要步骤。研究团队还指出,未来有机会探索其他感官模态(例如触觉)对多模态理解的影响,这将进一步推动人工智能向更全面的方向发展。
参考资料:
1.https://a16z.com/podcast/the-frontier-of-spatial-intelligence-with-fei-fei-li/
2.https://arxiv.org/abs/2411.04998
运营/排版:何晨龙