3月27-29日北京,TsingtaoAI与某5A级全国学术学会合作,面向军工科研院所研究和工程团队,组织具身智能与大模型技术实训。本实训TsingtaoAI派出公司具身智能领域的技术专家肖工,系统性实战训练具身智能领域的核心技术能力,以大模型为认知核心,以仿真环境为实验平台,构建从感知、理解到决策、控制的完整知识体系。实训采用“理论+仿真实验”双轮驱动模式,引导学员逐步掌握多模态感知、大模型微调与推理优化、强化学习控制、智能体系统构建等前沿技术,最终具备独立设计与开发具身智能应用系统的工程能力。
(保密单位相关照片或视频未授权外放)

具身智能导论:定义、发展历程、与大模型及通用人工智能的关系
多模态感知技术:视觉(ViT)、语音(Whisper)、触觉感知原理
多模态融合与对齐:特征层融合、跨模态注意力、对比学习
自然语言交互基础:NLU/NLG、意图识别、指令解析
上午仿真实验:多模态数据采集与处理实验环境配置:搭建仿真平台
语音识别实操:在仿真环境中采集语音指令,调用Whisper模型完成语音转文本
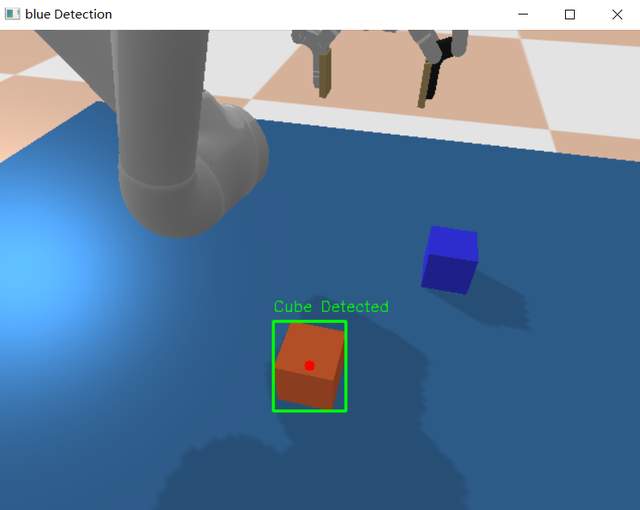
视觉感知实操:从仿真相机获取RGB图像与深度点云,使用ViT/YOLO进行物体识别与定位
数据对齐实践:将语音指令文本与视觉识别结果进行语义对齐
下午模块:大模型基础与多模态开发大模型架构解析:Transformer、MoE、GPT/LLaMA系列对比
多模态大模型:视觉-语言联合表征、VL架构与应用
检索增强生成(RAG):向量数据库、文档切分、检索与生成融合
模型微调基础:全参数微调、LoRA、指令微调技术
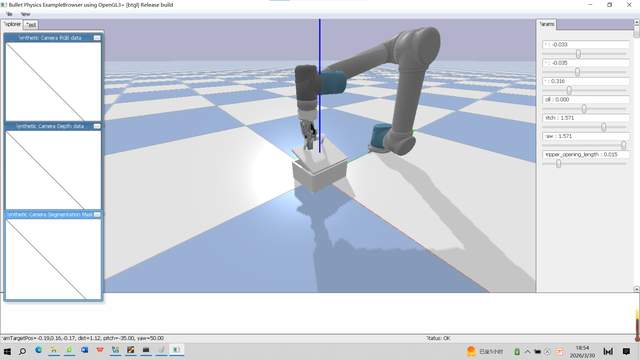
下午仿真实验:端到端语音控制机械臂仿真环境搭建:配置机械臂仿真模型(URDF)、3D相机、物理引擎
多模态交互实现:语音指令→Whisper识别→VL理解→目标定位
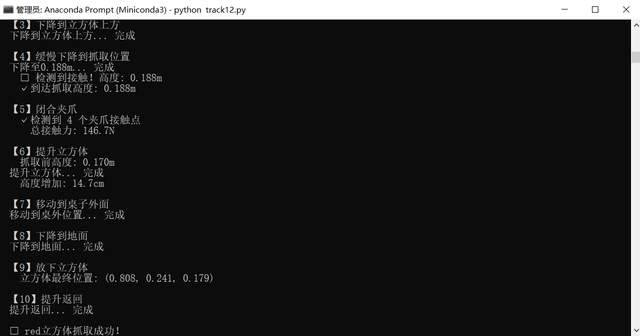
动作生成与执行:将目标坐标转换为机械臂关节角度,在仿真中执行抓取动作
任务闭环验证:视觉反馈确认抓取结果,完成“语音指令-物体抓取”端到端流程
第二天:3D视觉与智能体系统构建上午模块:3D视觉与视觉-语言-动作融合3D视觉技术:ToF/结构光/双目原理、点云处理(滤波/分割/配准)、场景重建
空间语义理解:结合大模型生成空间语义信息、场景理解模型
视觉-语言-动作(VLA)模型:端到端统一模型架构、代表模型(RT-1、Gato)、Agent框架
视觉引导机制:闭环控制、视觉伺服、动态调整
上午仿真实验:多任务语音调度与VLA模型实现实验3:复杂语音指令任务调度
设计多指令集,实现任务队列管理、优先级调度、资源冲突解决
在仿真环境中测试机械臂对复合指令(如“先抓A,再放到B”)的响应
实验4:视觉-语言-动作融合模型
实现视觉与语言特征匹配(指代表达定位)
端到端生成动作序列,在仿真中完成“看到物体-听懂指令-执行动作”全流程
下午模块:智能体Agent开发与控制技术智能体基础:Agent定义、ReAct框架(推理+行动循环)、记忆与规划组件
工具使用与自定义工具开发:感知工具、规划工具、控制工具的集成
协作机器人控制:位置/力/混合控制、阻抗控制、精度与稳定性调优
边缘部署:小参数模型优化(量化、剪枝、蒸馏)、TensorFlow Lite/PyTorch Mobile
下午仿真实验:智能体搭建与复杂任务执行实验5:完整机器人智能体系统构建
基于Agent框架,集成感知、规划、控制模块
实现ReAct推理循环:大模型生成策略→调用视觉工具→执行控制动作
实验6:高精度抓取与动态避障
在仿真环境中设置动态障碍物,实现视觉伺服抓取与实时避障
结合力控制,完成通过狭小空间、抓取易碎物体等复杂任务
第三天:模型优化与工业级应用设计上午模块:大模型微调与推理优化微调技术深化:参数高效微调(LoRA/Adapter)、内存高效训练(梯度检查点/混合精度)、对齐技术(RLHF/DPO)
主流底座模型:LLaMA、ChatGLM、Qwen、DeepSeek系列对比与选择
推理优化技术:分布式推理(张量/流水线并行)、投机解码、FlashAttention、INT4/INT8量化
多模态推理引擎:跨模态联合推理、多模态推理挑战
上午仿真实验:强化学习机械臂抓取训练实验7:基于强化学习的抓取模型训练
仿真环境配置:PyBullet物理引擎 +强化学习环境封装
MDP设计:定义状态空间(RGB-D+关节状态)、动作空间(末端位移/抓取)、奖励函数(稀疏+稠密)
算法训练:使用Stable-Baselines3实现SAC/PPO算法,训练抓取策略
训练监控与优化:TensorBoard可视化学习曲线、超参数调优、稳定性分析
下午模块:综合应用设计实践工业分拣Agent设计:需求分析、场景定义、系统架构(感知-决策-规划-控制)
多模型融合感知:YOLOv6快速定位 + Vision精细分类
大模型决策集成:ReAct框架生成分拣策略、可解释性决策输出
扩散模型生成训练数据、LLM生成仿真场景、代码辅助生成
下午仿真实验:智能分拣系统应用实验8:工业分拣Agent开发(强化学习版)
系统设计:定义分拣任务(多类工件)、模块接口、数据流
模型集成:加载预训练视觉模型 + 强化学习抓取策略
决策实现:大模型根据视觉输入生成分拣顺序与策略
仿真测试:在复杂场景(遮挡、光照变化、新物体)中测试分拣成功率与鲁棒性
使用LLM生成新的工件模型描述(URDF)与场景配置
使用扩散模型合成特定工件的训练图像,解决数据稀缺问题
配置文档一、硬件环境机械臂
二、软件环境建议先看 【1.Ubuntu配置教程】和【2.ROS极简概念基础】
PyBullet和Gazebo仿真环境
Ubuntu20.04或Win10
Python3.8以上
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)
Anaconda3 5.3(64-bit)
OpenCV-python4.8
Pytorch2.2.1
Jupyter notebook7.0.7
智能体Agent大语言模型:Yi-Large、Claude 3 Opus、文心大模型4.0 Turbo
多模态视觉理解大模型:GPT4v、GPT4o、Yi-Vision、Claude 3 Opus、智谱CogVLM2-Grounding、通义千问Qwen-VL-Max
三、配置步骤1.Conda


pip install pyaudio -i
https://pypi.tuna.tsinghua.edu.cn/simple
pip install appbuilder-sdk==0.4.0 -i
https://pypi.doubanio.com/simple/
实训技术专家肖工,具身智能算法专家TsingtaoAI合伙人,拥有超过15年的算法研究与实践经验。曾在世界五百强企业英特尔公司担任算法高级架构师,担任中国电子系统技术有限公司的算法Leader,高性能计算技术专家,是一位经验丰富且技术精湛的资深AI基础设施操盘手。他拥有超过十年的高性能计算喝算法研究和实践经验,曾在英特尔公司担任高性能计算架构师,并在多家500强企业中担任高性能计算和系统架构负责人。头部机器人公司担任视觉算法总架构师,直接参与了移动复合机器人和协作机器人的开发工作,通过引入大模型技术,成功地赋予了机器人自主导航、环境感知和决策规划的能力。并在高性能计算、人工智能和深度学习领域有着丰富的项目经验和卓越的技术能力,特别擅长高性能计算、图像处理、计算机视觉以及大规模计算系统的设计与优化,获得多项专利和荣誉。 华中科技大学硕士,曾在多个国家重点实验室及顶尖企业从事高性能计算及算法研发工作,领导并参与了多个重大项目的开发和实施。
工作经历
2006年,英特尔上海国际实验室,高性能计算系统架构设计,大型并行图形系统的架构与设计开发;
2009年,头部安全公司,并发与安全架构和视频监控系统设计,公安安全系统的架构设计与开发;
2012年,大型通信集团,大型应急通信系统和视频安全监控设计,确保了系统的安全性和可靠性;
2016年,大数据公司,企业家数据的数据安全和系统安全设计,多家公司设计和实施了信息化安全管理方案,大规模数据的分析和优化;
2019年,大型央企,GPU、CUDA与算力平台:深入研究并应用了GPU和CUDA技术,开发了多种高效的深度学习模型,广泛应用于图像和视频分析、目标检测和分类等领域;应用调优与性能监测:在项目管理和研发过程中,带领团队完成了多个智能视频分析引擎和智能办公引擎的开发,擅长对复杂算法进行性能优化和实时监测,确保系统的高效运行;算力调度管理与网络调优:在多个大型项目中,成功实现了算力调度管理系统的设计与实施,具备出色的网络调优能力,能够优化高性能计算环境下的资源利用率和系统稳定性。
2022.10,头部机器人公司,移动复合机器人和协作机器人的开发,移动复合机器人的开发,在移动复合机器人的研发过程中,我主要负责了智能导航与控制系统的设计与实现。通过引入大模型技术,我们成功地赋予了机器人自主导航、环境感知和决策规划的能力。
环境感知与建模:利用大模型对传感器数据进行高效处理和分析,机器人能够实时构建周围环境的精确三维模型,为后续的路径规划和避障提供有力支持。
智能导航算法:结合大模型的强化学习算法,我们训练出了能够在复杂环境中灵活导航的机器人。这些机器人能够根据实时路况调整行进路线,确保任务的顺利完成。
人机交互体验:借助大模型在自然语言处理方面的优势,我们实现了机器人与操作人员之间的流畅对话,极大提升了用户体验和工作效率。
协作机器人的开发,协作机器人作为新一代工业机器人,强调与人类工人的安全协同作业。在这一领域,我主要聚焦于通过具身智能提升机器人的灵活性与适应性。
智能抓取与装配:利用大模型对物体形状、重量及材质等信息的快速识别与处理,协作机器人能够准确抓取并灵活装配各种工件,大幅提高了生产效率和质量。
自适应学习能力:通过引入深度学习技术,我们使协作机器人具备了自适应学习能力。它们能够在实际工作中不断积累经验,自动优化作业策略以应对复杂多变的生产环境。
专业能力
并行计算和高性能计算;
深度学习模型设计和优化;
多模态大模型应用设计;
GPU与CUDA编程;
城市大脑与智能交通;
工业机器人和复合机器人大模型;
数据挖掘与运行优化;
国产信创环境适配优化;
专利
基于生成式深度学习模型的文本识别模型的生成方法以及装置 (CN202110447608.9) ;
大型语义分析方法及装置 (CN202110499308.5) ;
奖项: 荣获2021年度集团优秀解决方案奖 ;
授课经历
重庆大学:深度学习模型在大型物流场景的应用;
头部能源上市公司:大型时序数据预测模型的应用;
头部音视频公司:图形和视频大模型的应用;
百度合作:分拣实训和智能眼实训;
985高校:机器学习与数据挖掘分析;
主讲课程
《高性能图形图像计算与算法》
《计算机视觉中的图像处理技术》
《视觉和多模态大模型应用》
《具身智能与多模态大模型应用》
《机器学习中的知识自学习与数据优化挖掘》
《大规模分布式系统设计与实现》
《GPU、CUDA与算力模型应用实战》
《华为昇腾芯片下的大模型迁移和训练课程》
李工 机器人与自动驾驶算法专家TsingtaoAI合伙人,国内头部自驾企业研发工程师,出版书籍《c++设计模式》,工作之余一直坚持在公众号和B站 <码出名企路>分享经验和技术,做机器人、自驾和编程相关项目,全网累积粉丝10万+,付费学员500多人,帮助300+同学找到满意工作,爱交流,乐分享,期待与你一起进步。
目前主导开发基于3D高斯智能三维生成与实时渲染平台,突破数据瓶颈,实现海量多样化物体生成与强化学习(RL)训练。
硕士毕业后,一直在机器人和自动驾驶行业深耕,主要负责车端系统架构方案设计与开发,独自负责过多款车型软件架构的落地,深度主导百度Apollo系统架构、软件设计与调试优化设计,熟悉车路云交互链路,在自动驾驶方案落地上做过重大贡献。
优势:主导自驾方案落地,负责百度Apollo解决方案软件设计,工作之余一直坚持做培训,有丰富的授课经验、乐于学习,擅长与人交流,合作与共赢。
【核心项目1】自动驾驶感知架构升级与异构推理引擎适配
技术架构:基于Apollo Cyber RT框架的模块化感知系统重构;
创新价值:实现毫秒级多源异构数据吞吐,推理时延降低42%
核心贡献与实现路径
感知流水线解耦设计
基于Apollo Component机制重构视觉感知拓扑,将原有单体架构拆分为Detector(检测)/Tracker(跟踪)/Fuser(融合)独立组件
采用Cyber RT DAG配置文件动态编排组件连接方式,通过共享内存+双缓冲队列实现零拷贝数据传输,解决1080P@30FPS视频流处理丢帧问题
设计跨线程池的任务调度策略,在Apollo默认Executor基础上扩展Priority-based调度器,确保关键路径(障碍物检测)优先抢占计算资源
异构推理引擎适配框架
研发Apollo插件式推理引擎接口层,兼容TensorRT/LibTorch/ONNXRuntime三种后端,支持YOLOv5/YOLOv7/FCOS等模型无缝迁移
基于CUDA Stream异步流水线技术优化预处理-推理-后处理流程,实现多Batch输入动态合并(最大支持Batch=16),GPU利用率从58%提升至91%
开发模型热加载机制,通过Apollo监控服务动态调整推理实例数,响应时间满足ISO 21434功能安全要求
感知质量增强体系
集成Apollo Sensor Bridge模块,实现激光雷达与视觉时序对齐误差<3ms
开发基于场景特性的模型切换策略(城市道路/高速公路/停车场模式),通过Apollo HMI动态更新检测阈值参数2
构建多维度评估系统(误检率/漏检率/时延分布),关键指标通过Apollo Dreamview可视化看板实时监控
【核心项目2】自动驾驶数据系统研发与云原生部署体系构建 技术载体:基于Apollo Cyber RT的分布式服务网格 ;创新价值:实现百节点级配置秒级同步,数据采集效率提升60%
核心突破与实现路径
云边协同配置管理系统
基于Apollo Cyber Component规范重构服务节点,将配置下发系统拆分为ConfigMaster(中心)/ConfigAgent(边缘)双模组
研发Apollo扩展协议适配层,兼容Protobuf/JSON/YAML多格式配置模板,通过Cyber RT Service实现动态参数热加载(响应时延<200ms)
设计配置版本化回滚机制,与Apollo KV存储服务深度集成,支持10万级节点配置状态秒级同步
智能数据采集引擎
改造Apollo Recorder模块,开发多级缓存录制架构:
前置环形缓冲区(基于共享内存实现30秒数据预缓存)
后置持久化存储层(对接Apollo Data Pipeline实现自动分段上传)
创新研发场景触发式采集模式,通过Apollo Monitor模块动态捕获corner case事件,实现"事件前后±15秒"自动切片存储
构建数据质量评估子系统,集成Apollo数据校验规则引擎,自动过滤无效/重复/异常数据包
一键式编排部署体系
基于Apollo Bootstrap机制扩展集群管理功能,实现:
节点拓扑可视化编排(集成Apollo Dreamview拓扑编辑器)
资源需求预测调度(结合Prometheus监控数据动态分配计算节点)
开发Apollo Container Kit工具集,支持Docker/Kubernetes混合部署模式,启动耗时从分钟级压缩至秒级
关于TsingtaoAITsingtaoAI是一家专注工业具身智能领域的国家高新技术企业,旗下北京、宁波等地设有研发及运营团队。核心团队主要来自韩国首尔大学、中国农业大学、北京科技大学、蔚来汽车、美团、京东、硅基流动等产研组织,拥有深厚的AI Infra与机器人算法积淀。公司通过自研的通用PoC实验底座与多模态Agent编排引擎,为工业制造、高校实训等场景提供从数据生成、算法训练到即时部署的全栈解决方案。
TsingtaoAI解决具身智能落地最后一公里工程难题。构建一个高效、低成本、可复制的具身智能技能任务开发平台,将平台与具身大模型和异构端侧计算单元组成面向工业企业的物理AI软硬一体化解决方案。获24项AI领域知识产权,包括多模态大模型具身智能实验实训系统等。关键算法基于RISC-V芯片和昇腾NPU优化适配,实现突出性能。项目获长三角算力算法创新大赛冠军,山东省人社厅数字工程师大赛二等奖,宁波AI大赛二等奖、北京东城AI科创大赛技术创新组前三名,WAIC CICC大赛具身智能赛道前三名,入选河北垂直大模型应用场景名单。通过华为昇腾兼容性认证,在一汽集团、保时捷和福建奔驰等企业落地。