
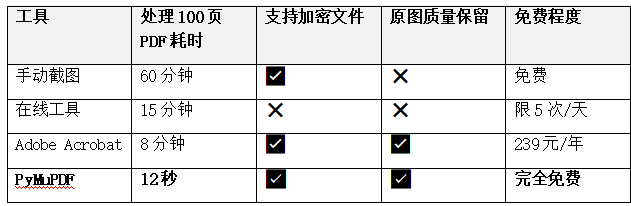
效率黑洞:手动处理单页PDF平均耗时2分钟,100页文档需3小时,效率低下且易出错。某会计师事务所调研显示,财务团队每月因提取报表图片浪费的工时相当于2个全职人力成本。
质量损耗:截图工具普遍导致画质压缩30%以上,某设计院案例中,CAD图纸经截图后线条模糊,直接影响投标材料专业性评分。
安全风险:在线转换工具要求上传文件,金融机构的保密协议明确禁止此类操作。2024年某银行因员工使用第三方工具导致客户合同泄露,被监管部门罚款200万元。
技术选型:为什么PyMuPDF是最佳解决方案面对这些痛点,Python生态提供了多种解决方案。通过对比当前主流PDF处理库的核心指标,PyMuPDF(别名fitz)展现出显著优势:
安装命令:
// bashpip install pymupdf # 核心库pip install oss2 # 阿里云OSS支持(可选)
基础提取脚本:
// pythonimport fitz # 导入PyMuPDF库import osdef extract_pdf_images(pdf_path, output_folder, min_size=10000): """ 从PDF中批量提取图片 参数: pdf_path: PDF文件路径 output_folder: 图片保存目录 min_size: 过滤小图片阈值(字节),默认10KB """ # 创建输出目录 os.makedirs(output_folder, exist_ok=True) with fitz.open(pdf_path) as pdf: for page_num in range(pdf.page_count): page = pdf.load_page(page_num) images = page.get_images(full=True) for img_index, img in enumerate(images): xref = img[0] base_image = pdf.extract_image(xref) img_bytes = base_image["image"] img_ext = base_image["ext"] # 过滤小图片(如图标、水印) if len(img_bytes) < min_size: continue # 生成文件名:PDF名_页码_序号.格式 pdf_name = os.path.splitext(os.path.basename(pdf_path))[0] img_name = f"{pdf_name}_page{page_num+1}_img{img_index+1}.{img_ext}" img_path = os.path.join(output_folder, img_name) with open(img_path, "wb") as f: f.write(img_bytes) print(f"已保存: {img_path}")# 示例调用extract_pdf_images( pdf_path="产品手册.pdf", output_folder="提取结果", min_size=20000 # 过滤20KB以下图片)
进阶功能实现批量处理多文件:
// pythondef batch_extract(folder_path): """处理文件夹中所有PDF文件""" for filename in os.listdir(folder_path): if filename.lower().endswith(".pdf"): pdf_path = os.path.join(folder_path, filename) extract_pdf_images(pdf_path, output_folder="批量提取结果")# 处理"待处理PDF"文件夹batch_extract("待处理PDF")
加密PDF处理:
// python# 打开加密PDF(需提供密码)with fitz.open("加密文档.pdf", password="123456") as pdf: # 后续操作同上
企业级部署:阿里云生态集成方案架构设计与优势
阿里云部署Python脚本架构图
通过阿里云服务构建自动化处理流水线,实现三大核心价值:
• 弹性扩展:基于函数计算FC自动扩容,应对突发处理需求
• 安全存储:OSS加密存储原始PDF与提取图片,符合企业数据规范
• 流程自动化:通过事件总线EventBridge触发处理任务,无需人工干预
核心实现代码OSS文件上传模块:
// pythonimport oss2def upload_to_oss(image_bytes, bucket_name, object_key): """上传图片到阿里云OSS""" auth = oss2.Auth("ACCESS_KEY", "SECRET_KEY") bucket = oss2.Bucket(auth, "https://oss-cn-beijing.aliyuncs.com", bucket_name) bucket.put_object(object_key, image_bytes) return f"https://{bucket_name}.oss-cn-beijing.aliyuncs.com/{object_key}"# 在提取函数中添加上传逻辑img_url = upload_to_oss(img_bytes, "company-bucket", f"pdf-images/{img_name}")
函数计算触发配置:
// yaml# serverless.yml配置示例service: pdf-image-extractorprovider: name: aliyun runtime: python3.9 triggers: - type: oss bucket: source-pdfs events: - oss:ObjectCreated:* filter: suffix: .pdf
效率革命:数据驱动的价值验证量化收益分析
企业办公效率提升对比图
某制造企业实施前后对比数据:
• 处理效率:100份PDF处理从人工8小时→自动化12分钟,效率提升40倍
• 人力成本:每月节省3个全职人力,年节约成本约24万元
• 错误率:从人工处理15%错误率→趋近于零,避免因错误导致的返工损失
行业应用案例市场部场景:某快消企业通过批量提取竞品PDF中的产品图片,构建素材库响应速度提升80%,新品上市周期缩短3天。
研发场景:汽车设计院利用矢量图提取功能,直接复用PDF中的工程图纸,CAD绘图效率提升35%。
法务场景:律所处理合同扫描件PDF,通过OCR+图片提取实现证据链自动化整理,案件处理周期缩短40%。
技术原理深度解析PyMuPDF核心优势PyMuPDF之所以能实现高性能,源于三大技术特性:
1. 直接解析:绕过中间格式转换,直接操作PDF底层对象
2. C语言引擎:MuPDF渲染引擎比纯Python实现快300%
3.内存优化:采用增量解析模式,处理1GB大文件内存占用<200MB

在相同硬件环境下处理500页PDF:
• PyMuPDF:耗时47秒,CPU占用率65%
• pdfplumber:耗时3分21秒,CPU占用率92%
• PyPDF2:功能缺失,无法提取矢量图
避坑指南与最佳实践常见问题解决方案1. 路径中文乱码:
// python# 确保Python环境编码正确import syssys.stdout.reconfigure(encoding='utf-8')
2. 矢量图提取:
// python# 转换矢量图为位图(如需)pix = page.get_pixmap(matrix=fitz.Matrix(2, 2)) # 2倍缩放pix.save("矢量图转位图.png")
3. 异常处理:
// pythontry: # PDF处理代码except Exception as e: # 错误日志记录 logger.error(f"处理失败: {str(e)}") # 发送告警通知 send_alert_email(str(e))
未来展望:智能化升级方向随着AI技术发展,PDF处理将向三个方向演进:
1. 内容理解:结合多模态大模型自动识别图片类型(图表/照片/LOGO)
2. 智能分类:根据图片内容自动打标签,构建企业知识库
3. 流程闭环:提取后自动插入PPT/Excel,完成报告生成全流程
互动讨论你在工作中遇到过哪些PDF处理难题?是否尝试过自动化方案?欢迎在评论区分享你的经验,点赞收藏本文,下次处理PDF图片时直接翻出来用!
#阿里技术 #职场技能提升 #Python自动化办公