大家好,我是墨林!
现在大型语言模型那叫一个厉害,文本生成、翻译、问答啥的都不在话下。但部署这些大模型可不是一件容易的事,尤其是对于那些没有GPU的普通用户来说,简直就是难上加难。
今天给大家介绍一个超火的开源项目 - Ollama,可以让本地部署大模型变得简单又轻松,简直就是“平民化”的大模型部署工具。
 项目简介
项目简介Ollama是一个开源的大型语言模型(LLM)服务工具,它的目标就是简化在本地运行大语言模型的过程。不管你有没有GPU,只要你的电脑满足基本配置,就能用Ollama轻松部署像Llama3、Phi4、Gemma2、DeepSeek等超火的大模型。它不仅开源免费,还提供了一个超简单的命令行界面和服务器,让你能够轻松下载、运行和管理各种开源LLM。

目前在Github上收获了119K star!
 性能特色模型丰富:涵盖了Llama3、Phi4、Gemma2、DeepSeek等众多热门开源LLM,可以一键下载并切换。本地化运行:不用依赖网络,随时随地就能用模型,再也不用担心网络不好模型罢工啦。隐私保护:模型在自己设备上跑,隐私妥妥的安全。成本节省:不用给云端服务交钱,省钱小能手就是它。灵活性高:可以根据自己需求调整优化模型,想怎么玩就怎么玩。量化技术:减少模型大小和计算需求,让资源有限的设备也能流畅运行。模型并行和数据并行:提高训练速度和推理效率,干活更麻利。快速安装使用
性能特色模型丰富:涵盖了Llama3、Phi4、Gemma2、DeepSeek等众多热门开源LLM,可以一键下载并切换。本地化运行:不用依赖网络,随时随地就能用模型,再也不用担心网络不好模型罢工啦。隐私保护:模型在自己设备上跑,隐私妥妥的安全。成本节省:不用给云端服务交钱,省钱小能手就是它。灵活性高:可以根据自己需求调整优化模型,想怎么玩就怎么玩。量化技术:减少模型大小和计算需求,让资源有限的设备也能流畅运行。模型并行和数据并行:提高训练速度和推理效率,干活更麻利。快速安装使用使用Ollama简直不要太简单!只需要几步,就能轻松上手。
1、安装:
Linux/macOS:在终端输入curl -fsSL https://ollama.com/install.sh | sh,一键安装超简单。
Windows:去下载 Ollama Windows 版安装包,然后双击运行安装程序就行。

2、基础命令:
启动 Ollama 服务:ollama serve(默认端口 11434 )。
下载模型:ollama pull <模型名> ,比如想下载 Deepseek,就输入ollama pull Deepseek 。
运行模型:ollama run <模型名> ,开启愉快的对话模式。
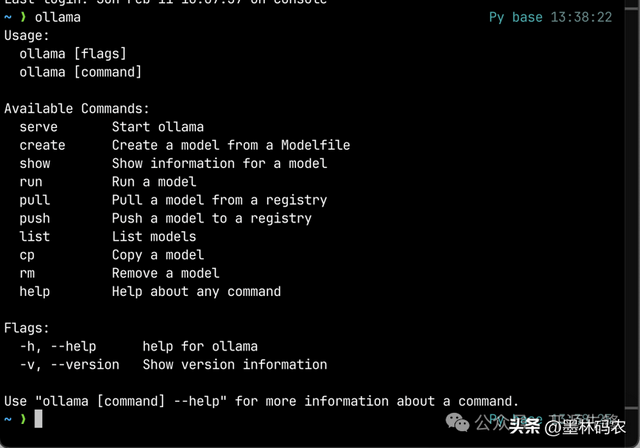
管理模型:ollama list查看已下载模型;ollama rm <模型名>删除模型;ollama help查看所有命令。
3、通过 API 调用模型:用 cURL 生成文本示例:
curl http://localhost:11434/api/generate -d '{ "model": "Deepseek", "prompt":"蛇年有趣的祝福"}'Python 调用示例:
import requestsresponse = requests.post( "http://localhost:11434/api/generate", json={"model": "Deepseek", "prompt": "蛇年有趣的祝福"})print(response.json()["response"])项目体验展示试了试最近超火的DeepSeek R-1,简直不要太爽!
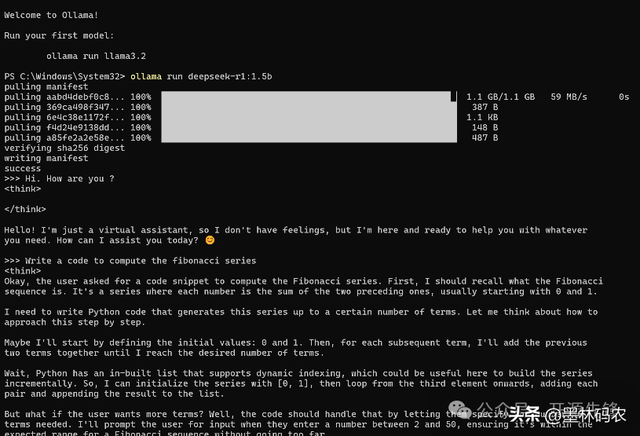
按照官网的指示安装了Ollama,然后在模型库中找到了DeepSeek R-1。选择了1.5B的模型,直接用ollama run deepseek-r1:1.5b命令启动。运行起来很流畅,回答得又快又好,简直就像有个智能助手在身边。而且,Ollama的社区超级活跃,遇到问题随时能找人帮忙,这种感觉太棒了!
Ollama是一个非常实用且易用的开源项目。它让我们这些“小白”也能轻松地在本地部署和管理大语言模型。无论你是开发者、研究人员还是爱好者,只要你对AI感兴趣,Ollama都是一个值得尝试的工具。特别是最近超火的Deepseek模型,更是让Ollama的魅力倍增!
项目地址:https://github.com/ollama/ollama