An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation
Max Schäfer , Sarah Nadi , Member, IEEE, Aryaz Eghbali , and Frank Tip
引用
M. Schäfer, S. Nadi, A. Eghbali and F. Tip, "An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation," in IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85-105, Jan. 2024, doi: 10.1109/TSE.2023.3334955.
论文:https://ieeexplore.ieee.org/document/10329992
仓库:https://github.com/githubnext/testpilot
摘要
单元测试在确保软件正确性方面至关重要,但手动创建单元测试繁琐且耗时。为此,我们对没有额外训练或人工干预的LLMs在自动化单元测试生成方面的有效性进行了大规模的实证评估。我们的方法基于LLM提供的函数签名、实现以及文档中的使用示例。在测试生成过程中,若遇到失败,我们通过重新提示模型并提供错误消息来生成新的测试。我们将此方法实现为TESTPILOT,一款自适应LLM的JavaScript测试生成工具,并对25个npm包中的1,684个API函数进行评估。生成的测试覆盖率中位数分别达到了70.2%的语句覆盖率和52.8%的分支覆盖率,显著反馈驱动的JavaScript测试生成技术Nessie。同时,92.8%的生成测试与现有测试的相似度≤ 50%,且不存在完全相同的测试。最后,我们还运行了两个额外的LLMs,结果显示LLM的大小和训练集对方法的有效性有影响,但不取决于具体的模型。
1 引言
我们探索了使用不需要额外的训练和尽可能少的预处理的LLMs自动生成单元测试的可行性。也就是说,不需要提供模型输入输出示例或进行额外训练,仅通过仔细设计提示来实现自动生成单元测试。具体来说,除了测试框架代码外,我们的提示包含(1)待测试函数的签名;(2)如果有的话,它的文档注释;(3)从文档中挖掘的函数使用示例;(4)其源代码。最后,技术中还包括一个自适应组成部分:每生成一个测试就执行它,如果失败了,就再次使用包含(5)失败的测试和它产生的错误消息的特殊提示来提示LLM,这通常允许模型修正测试并使之通过。
为了实验,我们在一个名为TESTPILOT的系统中实现了这些技术,它是一个基于LLM的JavaScript测试生成器。我们选择了JavaScript作为示例语言,因为使用传统方法在此语言上生成测试具有挑战性,这归因于缺乏静态类型信息和其运行时语义的机制。我们在25个npm包上评估了我们的方法,这些包总共有1,684个API函数,我们尝试为它们生成测试。我们调查了生成测试所达到的覆盖率及其质量,包括成功率、失败原因,以及它们是否包含实际执行目标包功能的断言(非平凡断言)。我们还实证评估了我们的提示制作策略的各个组成部分的效果,以及TESTPILOT是否生成了LLM训练数据中已经记忆的测试。
我们使用OpenAI当前最强大且性价比最高的模型gpt3.5-turbo,TESTPILOT生成的测试达到了70.2%的中位数语句覆盖率和52.8%的分支覆盖率。我们发现,61.4%的生成测试包含非平凡断言,这些非平凡测试单独实现了61.6%的覆盖率,表明生成的测试包含了执行目标包功能的有意义的断言。进一步检查发现,生成测试失败的最常见原因是超出了我们强制执行的两秒超时,通常是因为未能向测试框架通报测试完成。我们发现,平均而言,自适应方法能够修正15.6%的失败测试。
我们的实证评估还显示,提示中包含的所有五个组件对于生成具有高覆盖率的有意义测试套件至关重要。排除这些组件中的任何一个都会导致更高比例的测试失败或覆盖率降低。另一方面,虽然从提示中排除使用示例会降低方法的效果,但并不会使其变得无效,这表明LLM能够从其训练集中类似测试代码的存在中学习。
最后,我们发现使用gpt3.5-turbo LLM生成的测试中有60.0%的测试与现有测试的相似度≤40%,92.8%的测试相似度≤50%,没有任何测试是精确复制的。这表明生成的测试并非直接从LLM的训练集中复制而来。
总之,本文做出了以下贡献:
一个简单的测试生成技术,通过迭代查询LLM,使用包含待测试API函数签名的提示生成单元测试,并可选地包含这些函数的主体、文档和使用示例。该技术还具有一个自适应组成部分,它在提示中包含在执行先前生成的测试时观察到的错误消息。该技术在 JavaScript 工具 TESTPILOT 中的实现,作为开源软件可在 https://github.com/githubnext/testpilot 上获取。在 25 个 npm 软件包上对 TESTPILOT 进行了广泛的实证评估,证明了它在生成高覆盖率测试套件方面的有效性。我们的评估探讨了以下几个方面:生成测试的质量,包括它们包含的断言,以及包含非平凡断言的测试的覆盖率。排除各种提示组件的效果。生成测试与现有测试的相似性。与JavaScript的最新反馈导向随机测试生成技术Nessie的比较。比较底层LLM对TESTPILOT生成测试的影响。所有实验的原始数据和分析可以在https://doi.org/10.6084/m9.figshare.23653371找到。

图1:TESTPILOT整体工作流程
2 方法
2.1 整体架构
图1展示了TESTPILOT的高级架构,它由五个主要组成部分构成:给定PUT作为输入,API探索器识别要测试的函数;文档挖掘器提取关于它们的元数据;提示生成器、测试验证器和提示精炼器合作构建测试生成的提示,从LLM的响应中组装完整测试,运行它们以确定是否通过,并构建更多提示以生成更多测试。现在我们更详细地讨论这些组件。
API资源管理器:此组件分析PUT以确定其API,即包公开给客户端的函数、方法、常量等集合。在JavaScript中,由于语言的高度动态性,静态确定API非常困难。因此,类似于其他JavaScript测试生成工作,我们采用基于动态分析的方法。特别是,我们加载应用程序的主包并应用内省来遍历生成的对象图,并识别绑定到函数的属性。对于每个函数,我们记录其访问路径(即必须从主模块到达它的属性序列)、其签名(在缺乏静态类型信息的情况下,这只是一个参数名称列表)和其定义(即其源代码)。API资源管理器的输出是一个由访问路径、签名和定义描述的函数列表;其他API元素被忽略。
文档挖掘器:此组件从PUT随附的文档中提取代码片段和评论,并将它们与相关的API函数关联。目的是为每个API函数收集评论和示例,描述其目的和预期用途。在JavaScript代码库中,文档通常以Markdown(.md)文件的形式提供,其中代码片段嵌入为围栏代码块(即,由三个反引号包围的块)。我们在代码库中的所有Markdown文件中找到所有这样的块,并将每个函数与文本包含函数名称的所有代码片段的集合关联。我们还将每个API函数与紧接在它之前的doc注释(/**...*/)关联,如果有的话。
其余的三个组件是提示生成器、测试验证器和提示优化器,它们一起为API资源管理器识别的所有API函数生成和验证测试,使用文档挖掘器提供的信息。函数逐个处理,对于每个函数,一次只生成一个测试(而不是一次性生成整个测试套件)。这是为了使我们能够独立验证每个测试,而不受其他测试的干扰。
提示生成器:这个组件构建初始提示,用于发送给LLM生成给定函数f的测试。如上所述,我们最初最多只有四个关于f的信息可供使用:其签名、定义、文档注释和从文档中提取的用法片段。虽然构建包含所有这些信息的提示可能看起来很自然,但实际上,更复杂的提示有时会导致LLM受到额外信息的困扰而产生更差的结果。因此,我们采用了不同的策略:我们从一个非常简单的初始提示开始,该提示除了函数签名外不包含任何元数据,然后让提示优化器逐步添加额外的信息。
测试验证器:接下来,我们将生成的提示发送给LLM,并等待完成。我们只使用所需数量的标记来形成一个语法有效的测试。由于无法保证模型建议的完成是语法有效的,测试验证器尝试修复简单的语法错误,比如缺少括号,然后解析生成的代码以检查其是否语法有效。如果不是,则立即将测试标记为失败。否则,使用Mocha测试运行器运行它,以确定测试是否通过或失败(可能由于断言错误或其他运行时错误)。
每个返回的完成可以与提示连接,生成一个候选测试。然而,为了让我们能够消除从不同提示生成的重复测试,我们如下后处理候选测试:我们去除包含提示中函数元数据的注释,并分别将描述替换为描述中的通用字符串'test suite'和'test case'。
提示优化器:提示优化器采用一些策略生成额外的提示用于向模型查询。总体而言,我们采用了四个提示优化器,如下所示:其中“p”是指生成测试时所使用的初始提示(prompt),它包含了关于待测试函数的基本信息,如函数签名等,“f”则是指待测试的函数本身。
1.FnBodyIncluder:如果p中不包含f的定义,则创建一个包含它的提示。
2.DocCommentIncluder:如果f有文档注释但p没有包含它,则创建一个包含文档注释的提示。
3.SnippetIncluder:如果f的用法片段可用,但p没有包含它们,则创建一个带有片段的提示。
4.RetryWithError:如果测试函数t以错误消息e失败,则构建一个由以下内容组成的提示:失败测试t的文本,后跟注释//上面的测试失败,错误为e,后跟注释// 修正测试。该策略仅在每次提示生成中应用一次,因此如果p本身已通过此策略生成,则不会尝试。
然后使用优化的提示以与原始提示相同的方式构建测试。所有策略都独立应用,并以所有可能的组合应用,但请注意,前三个策略最多只应用一次,第四个策略永远不会连续应用两次,从而确保终止。
2.2 算法细节

算法1:API探索的伪代码
现在我们提供我们方法的两个关键步骤的更多细节:API探索和测试生成。
API探索:算法1展示了伪代码,说明了如何识别一个包的API组成函数集合。该算法接受一个待测试的包pkgName,并生成一个由⟨a,sig⟩对表示的API列表。这里,a是一个访问路径,唯一表示一个API方法,sig是一个函数的签名。我们的访问路径概念与Mezzetti等人提出的原始概念相比略有简化,它由一个包名后跟一系列属性名组成。
我们依靠动态方法来探索包pkgName的API,方法是创建一个导入该包的小程序(第2行),并依靠JavaScript的内省能力来确定哪些属性存在于导入pkgName后创建的包根对象modObj中,以及这些属性的类型。 modObj的属性的探索由一个递归函数explore处理,该函数从表示包根的访问路径开始,递归地遍历该对象,并在遍历进入对象结构时调用另一个辅助函数extend来扩展访问路径。
在探索过程中,如果遇到一个对象,在访问路径a处,其类型是具有签名sig的函数,则记录一对⟨a,sig⟩(第10行)。如果p的类型是对象,则递归探索其属性引用的对象(第15- 15行),如果p的类型是数组,则也递归探索p的属性(第17-19行)。
测试生成:算法2展示了测试生成步骤的伪代码。该算法通过将生成的提示集合初始化为prompts,将生成的通过测试集合初始化为tests,将包含所有生成测试的集合初始化为seen,并使用算法1获取构成包API的(访问路径,签名)对的集合apis(第2-5行)。然后,在第6-7行,对于每个这样的对,使用在图1中说明的模板构造基本提示并将其添加到prompts中,仅包含访问路径和签名。接下来,在第9-27行,通过向先前生成的提示添加从代码中提取的函数主体、示例用法片段和文档注释,创建额外的提示。在这里,refine函数通过添加函数主体、示例片段或文档注释来扩展先前生成的提示。如果包含,每种类型信息在提示中出现的顺序如下固定:示例片段、先前生成测试的错误消息、文档注释、函数主体、签名。
第29-44行的while循环描述了一个迭代生成测试的过程,只要仍有未处理的提示存在,就会继续。在每次迭代中,选择并从prompts中移除一个提示,并向LLM查询完成(第31行)。对于接收到的每个完成,通过连接提示和完成构造一个测试(第33行),并修复一些次要的语法问题,例如在测试末尾添加缺少的'}'字符(第34行)。此外,我们从测试中移除注释,以便对仅在注释中不同的测试进行去重(第35行)。
如果生成的测试在语法上有效且之前未遇到相同的测试,则执行它(第38行)。否则,我们不会重新执行它,但仍然将提示与先前看到的测试相关联。如果测试执行成功,则将其添加到tests中(第40行)。如果测试失败(由于断言失败、非终止或因未捕获的异常而失败),并且如果测试不是从之前构造的失败测试的提示中派生的(第42行),则创建一个包含失败测试和错误消息的新提示,并将其添加到prompts中。当迭代过程结束时,返回tests集合(第45行)。

算法2:测试生成的伪代码
3 实验评估
RQ的选择与实验设置
RQ1 TESTPILOT生成的测试能达到多少语句覆盖率和分支覆盖率?理想情况下,生成的测试应该达到较高的覆盖率,以确保对API的大部分功能进行测试。考虑到我们的目标是生成完整的单元测试套件(而不是用于发现错误),我们仅对通过测试进行语句覆盖率进行测量。我们报告了包级别和函数级别的覆盖率。
RQ2 TESTPILOT的覆盖率与Nessie 相比如何?我们将TESTPILOT的覆盖率与最先进的JavaScript测试生成器Nessie进行比较,后者采用反馈导向方法。
RQ3 TESTPILO生成的测试中有多少包含非平凡断言?一个没有断言或只包含像assert.equal(true, true)这样的平凡断言的测试可能仍然达到较高的覆盖率。然而,这种测试并不提供有用的测试预期。我们检查生成的测试,并测量非平凡断言的普遍程度。
RQ4 TESTPILOT的失败测试的特征是什么?我们调查任何失败的生成测试背后的原因。
RQ5 提示中包含的每种类型信息对于TESTPILOT生成的测试的有效性有何贡献?为了调查通过提示的优化器包含的所有信息是否对生成有效的测试是必要的,我们禁用每个优化器,并报告它如何影响结果。
RQ6 TESTPILOT生成的测试是否是从现有测试中复制而来?由于gpt3.5-turbo是在GitHub代码上进行训练的,LLM很可能已经在我们评估包的测试中见过这些测试,并可能只是生成了它“记忆”的测试的副本。我们调查生成的测试与我们评估包中任何现有测试之间的相似性。
RQ7 TESTPILOT生成的测试的覆盖率在多大程度上依赖于底层的LLM?为了理解基于LLM的测试生成方法的普适性以及TESTPILOT所依赖的底层LLM的影响,我们使用gpt3.5-turbo与另外两个LLM进行比较:(1)OpenAI的code-cushman-002模型,是gpt3.5-turbo的前身之一,是Codex系列LLM之一,也是GitHub Copilot首次发布背后的主要模型之一;(2)StarCoder,是一个完全文档化其训练过程的公开可用的LLM。
为了回答上述研究问题,我们使用了25个npm包的基准测试。为了回答RQ1-RQ6,我们使用gpt3.5-turbo LLM(版本gpt-3.5-turbo-0301)运行TESTPILOT,以零temperature 采样最多100个token的五个结果,所有其他选项保持默认值。在RQ7中,我们对code-cushman-002和StarCoder使用相同的设置,除了后者的采样temperature 为0.01,因为它不支持零temperature 。请注意,基于LLM的测试生成本身并没有测试生成预算,因为这不是一个无限的过程。相反,我们最多要求LLM为每个提示提供五个结果(但模型可能返回较少)。我们对返回的测试进行去重,以避免夸大生成测试的数量。例如,如果两个提示返回相同的测试(仅注释不同),我们只记录这个测试一次,但跟踪哪个提示导致了它的生成。虽然我们将采样temperature 设置得尽可能低,接收到的响应仍有一些不确定性。因此,我们进行了10次实验运行。第IV节报告的所有每个包的数据点都是这10次运行的中位数值,对于整数类型的数据,如测试数量,我们使用中位数的上限。对于RQ6,我们仅基于第一次运行呈现相似性数字。我们使用Istanbul/nyc来测量语句和分支覆盖率,并使用Mocha的默认时间限制为每个测试2秒。
RQ1 TESTPILOT生成的测试能达到多少语句覆盖率和分支覆盖率?
表1显示了TESTPILOT为每个包生成的测试数量、通过测试的数量及比例、以及相应的覆盖率。前两列还显示了仅加载包时获得的覆盖率(加载覆盖率),作为结果解释的参考点。总体而言,TESTPILOT生成的测试中有9.9%–80.0%通过,所有包的中位数为48.0%。
语句覆盖率方面,通过测试实现的每个包的语句覆盖率在33.9%到93.1%之间,中位数为70.2%。实现的语句覆盖率明显高于加载覆盖率,在所有包中的差异范围在19.1%–88.2%之间,中位数差异为53.7%。
最低的语句覆盖率出现在js-sdsl上,为33.9%。进一步调查发现,从外部存储库提取的示例片段包含在内后,覆盖率提高到了43.6%,突显了使用示例在提高覆盖率方面的重要性。
对于GitLab项目,TESTPILOT覆盖率在51.4%到78.3%之间,显示了对未见过的包生成高覆盖率的单元测试的能力。
分支覆盖率方面,通过测试实现的分支覆盖率在16.5%到71.3%之间,中位数为52.8%。与语句覆盖率类似,实现的分支覆盖率也远高于加载覆盖率,中位数差异为50.0%。
在函数级别,每个函数的中位数语句覆盖率范围从0.0%到100.0%,中位数为77.1%。Pearson相关性检验表明,覆盖率与函数大小之间没有统计学上显著的相关性。
TESTPILOT生成的测试中有一部分是唯一贡献的,覆盖了其他测试未覆盖的至少一个语句。通过测试的中位数中有10.5%属于这种类型,显示了TESTPILOT生成了多样性的测试,但也存在一定的冗余。探索测试套件最小化技术以减小测试套件的大小是未来工作的一个有趣方向。

表1:使用 gpt3.5-turbo 生成的 testpilot 通过测试的语句和分支覆盖率。
RQ2 TESTPILOT的覆盖率与Nessie 相比如何?
我们将TESTPILOT与JavaScript测试生成器Nessie进行比较,后者采用传统的反馈导向方法。对于每个包,我们使用Nessie生成了1000个测试,并以与TESTPILOT相同的方式测量语句和分支覆盖率,重复这些测量10次,并取10次运行中的中位数覆盖率。使用Wilcoxon配对秩和检验确定两种工具实现的覆盖率是否存在统计学上显著的差异。
Nessie的语句和分支覆盖率显示在表1的最后两列中。Nessie无法在uneval上运行,因为该模块的唯一导出是一个函数,而Nessie不支持这种情况。对于其余的24个包,Nessie实现了4.7%–96.0%的语句覆盖率,中位数为51.3%。相比之下,TESTPILOT的中位语句覆盖率为70.2%,分支覆盖率为52.8%,远高于Nessie的25.6%。这些差异都是显著的(p值分别为0.002和0.027)。
深入研究每个包的结果显示,TESTPILOT在17个包中的覆盖率优于Nessie,覆盖率提高了3.6%–74.5%,中位数为30.0%。而对于剩余的7个包,TESTPILOT的覆盖率低于Nessie,降低了0.5%–53.2%,中位数降低了3.6%。Nessie无法在3个项目上实现任何分支覆盖,而这些项目的语句覆盖率不为零。
除了Nessie和TESTPILOT实现的覆盖率之间的差异外,Nessie生成的测试与TESTPILOT生成的测试看起来相差很大,这源于Nessie对测试生成的随机方法。为了说明这一点,图2显示了Nessie生成的一个测试的示例,测试getCountry函数。如图所示,测试使用了长变量名,如ret_val_manuelmhtr_countries_and_timezones_1,这会降低可读性。此外,测试在调用getCountry时使用对象文字将随机值绑定到一些随机命名的属性,这不符合API的预期使用。此外,Nessie生成的测试不包含任何断言。相比之下,TESTPILOT为相同的包生成的测试通常使用与程序员选择的变量名相似的变量名,使用合理的值调用API,并且通常包含断言。
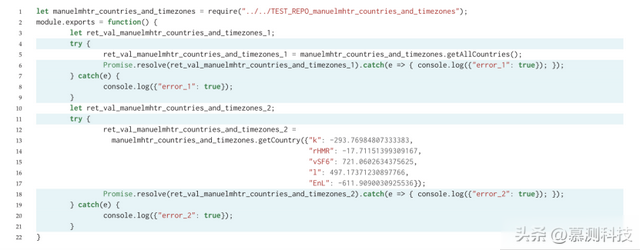
图2 Nessie生成的测试示例
RQ3 TESTPILO生成的测试中有多少包含非平凡断言?

表2 使用 gpt3.5-turbo 生成的非平凡测试的次数(%),以及通过非平凡测试后的语句覆盖率
我们将非平凡断言定义为依赖于被测试包中至少一个函数的断言。为了识别非平凡断言,我们首先使用CodeQL从生成的测试中的每个断言计算一个反向程序切片。如果断言的反向切片包含对被测试包的导入,则将该断言视为非平凡断言。然后,我们报告包含至少一个非平凡断言的生成测试。Table 2显示了具有非平凡断言的测试数(简称为非平凡测试)及其与表1中所有生成测试的比例。该表还显示了这些测试中通过的数量和比例,以及它们实现的语句覆盖率。
我们注意到只有一个包,即image-downloader,其中TESTPILOT仅生成了平凡测试。尽管为image-downloader生成的测试包括对其API的调用,但它们都缺少assert语句。在其余的包中,每个包的TESTPILOT生成的测试中,非平凡测试占9.1%–94.6%的中位数。对于给定包,生成的测试中有61.4%的中位数是非平凡的。与所有生成的测试相比,我们还可以看到仅略低于非平凡测试通过的比例(表1中的整体通过测试的中位数为48.0%,表2中的非平凡通过测试的中位数为43.7%)。这两个结果都表明,TESTPILOT通常生成具有断言的测试,这些断言测试了目标包的功能。
非平凡测试实现的覆盖率也支持这一发现。具体而言,当将表1中所有生成测试的语句覆盖率与表2中非平凡测试的语句覆盖率进行比较时,我们发现差异范围为0.0%–84.0%,中位数差异仅为7.5%。这意味着大多数包的覆盖率主要来自于测试生成的测试用例所测试的API功能。然而,我们注意到有4个包(jsonfile, node-dir, zip-a-folder, image-downloader),非平凡测试实现了0%的语句覆盖率,导致较大的差异。除了上面讨论的image-downloader之外,其余三个包没有通过的非平凡测试。由于我们仅对通过的测试计算覆盖率,因此非平凡测试的语句覆盖率为0%。
RQ4 失败的测试有什么特征?

图3 失败测试的错误类型
图3显示了每个包的失败测试数量,以及失败原因的细分。断言错误发生在断言中的预期值与执行代码的实际值不匹配时。文件系统错误包括文件或目录不存在等错误,我们通过检查错误堆栈跟踪中的文件系统相关错误代码来识别这些错误。正确性错误包括所有类型错误、语法错误、引用错误、done 的不正确调用以及无限递归/调用栈错误。超时错误发生在测试超过我们允许的最大运行时间(2秒/测试)时。最后,我们将观察到的所有其他特定于应用程序的错误归为其他。
我们发现最常见的失败原因是超时,中位数为失败测试的 22.7%,其次是正确性错误(特别是类型错误),中位数为失败测试的 20.0%。大多数超时是由于没有调用 done 导致的,使得 Mocha 一直等待调用。我们注意到,平均而言,RetryWithError 修复器能够修复 15.4% 的这类超时错误,模型通常只是简单地添加了一个调用 done。
我们发现,中位数为 19.2% 的失败是断言错误,这表明在某些情况下,gpt3.5-turbo 无法找出测试 Oracle 的正确预期值。当被测试的包不被广泛使用,并且我们提供给模型的信息都不能帮助它找出正确的值时,这一点尤为真实。例如,在 geo-point 的一个测试中,TESTPILOT 能够使用提供的示例片段中的坐标正确构造两个地理坐标作为 calculateDistance 函数的输入,该函数计算两个坐标之间的距离。然而,TESTPILOT 错误地生成了 131.4158102876726 作为这两点之间距离的预期值,而正确的预期值是 130584.05017990958;这导致测试失败,出现断言错误。我们注意到,在这种具体情况下,当 TESTPILOT 使用失败测试和错误消息重新提示模型时,它随后能够生成一个带有更正的 Oracle 的通过测试。平均而言,我们发现 RetryWithError 修复器能够修复 11.1% 的断言错误。
最后,我们注意到文件系统错误是特定于领域的。文件系统领域的包生成的测试具有较高比例的失败测试,原因是此类错误。这并不奇怪,因为这些测试可能依赖于可能不存在或需要包含特定内容的文件。其他领域的包不会面临这个问题。
总的来说,我们发现重新提示模型使用失败测试的错误消息(无论失败原因是什么)允许 TESTPILOT 在 15.6% 的情况下生成连续的通过测试。
RQ5 提示优化器的影响?

图4 禁用提示优化器的影响
我们研究了优化器对生成测试质量的影响。通过逐个禁用优化器进行消融研究,我们比较了每个优化器对测试质量的影响。图4展示了我们的结果。x 轴显示了我们在图例中显示的不同配置之间比较的指标。y 轴显示了每个指标的值(均以百分比表示)。箱线图中的每个数据点代表了给定包的特定指标的结果,使用相应的优化器配置。每个箱子中间的黑线表示所有包中该指标的中位数值。完整配置是我们迄今为止展示的配置(即所有优化器都启用)。其他配置显示了排除一个精炼器后的结果。结果显示完整配置在所有指标上优于其他配置,表明所有优化器提供的信息都有助于生成更有效的测试。禁用任何一个优化器都导致至少一个指标的值降低,除了少数例外。特别是,禁用 FnBodyIncluder 或 SnippetIncluder 显著降低了通过测试的百分比。
Wilcoxon匹配对比秩和检验显示,完整配置与禁用任何优化器或基本配置之间存在显著差异。禁用FnBodyIncluder或DocCommentIncluder对通过测试的影响最大。此外,除了禁用FnBodyIncluder和禁用RetryWithError之间存在统计学显著差异外,其他配置之间几乎没有统计学意义的差异。尽管样本容量较小,但在禁用SnippetIncluder和其他任何优化器之间没有统计学上显著的差异。虽然精炼器总体上改进了覆盖率和通过测试的百分比,但并不总是改进每个API函数的结果。有时,向不包含实现的提示添加信息可能导致生成失败的测试。
在所有包中,优化提示生成了5367个提示,其中只有394个案例(7.3%)中,精炼提示比原始提示效果差,即原始提示生成了通过测试,而优化提示没有。
RQ6 记忆效应?

图5 使用 gpt3.5-turbo 生成的 TESTPILOT 测试用例的累计百分比
由于 GPT3.5-Turbo 是在 GitHub 代码上进行训练的,我们基准测试中的一些现有测试可能已经是其训练集的一部分,这引发了一个担忧,即 TESTPILOT 可能会记住现有的测试,而不是生成新的测试,从而限制了其在未经训练的软件包上的实用性。为了调查记忆的潜在影响,我们测量了每个生成的测试与基准测试中现有测试之间的相似度。最近,Lemieux 等人报告称,代码剽窃或克隆检测技术无法有效识别 LLM 代码的记忆。相反,他们发现通过编辑距离来测量相似性会产生更有意义的结果。他们定义了最大相似度作为一种指标,该指标测量了给定生成的测试与所有现有测试之间的归一化最高相似度。其中 TP 是软件包中现有测试函数的集合,t 是给定的生成测试,dist 是生成测试和现有测试之间的编辑距离。我们使用相同的方法计算每个生成测试的最大相似度,使用 npm Levenstein 包计算 dist。
图5显示了对于每个项目,生成测试案例的累积百分比,其中最大相似度小于 x 轴上的值。我们还展示了所有项目中所有生成测试案例的累积百分比。我们发现,TESTPILOT 生成的测试案例中有 6.2% 的案例最大相似度 ≤ 0.3%,60.0% 的案例 ≤ 0.4 相似度,92.8% 的案例 ≤ 0.5 相似度,99.6% 的案例 ≤ 0.6 相似度,而 100.0% 的案例 ≤ 0.7。这意味着 TESTPILOT 从不生成现有测试的精确副本。相比之下,Lemieux 等人生成的 Python 测试中,有 90% 的测试案例 ≤ 0.4 相似度,但有 2% 的测试案例是精确副本。尽管如此,由于 Python 和 JavaScript 中测试框架的差异,相似性数字不能直接在这两种语言之间进行比较。

图6 bluebird 中的一个测试案例
图6展示了 bluebird 中的一个测试案例,与现有测试案例的相似度为 0.62。虽然这里的编辑距离很低,导致相似度很高,但我们可以看到测试之间存在语义差异。例如,生成的测试只是检查抛出的异常是否是类型错误,而现有的测试则检查跟踪中的某些值。因此,我们生成的具有 > 0.5 相似度的 7.2% 测试案例并不构成 TESTPILOT 生成记忆测试案例的问题。最后,我们预期 GitLab 托管项目的生成测试与现有测试的相似性较低,因为据我们所知,OpenAI 模型的训练集仅包含来自 GitHub 的项目,因此模型在训练期间不太可能看到现有的测试。我们的结果确实显示,五个项目中有三个的最大相似度 ≤ 0.4,另外两个项目的最大相似度为 0.5。这使我们相信我们使用的相似性度量提供了有意义的结果。
RQ7 不同LLMs的影响?

表3使用三种 llms 比较 testpilot 生成的测试的语句覆盖率
表3显示了使用三种不同的LLM时,TESTPILOT生成的测试的数量、通过的测试的百分比,以及语句和分支覆盖率。虽然每个软件包的个别覆盖率有所不同,但使用 code-cushman-002 模型生成的测试的覆盖率与使用 gpt3.5-turbo 生成的测试相当,后者在所有软件包中的中位数语句和分支覆盖率略高。Wilcoxon配对符号秩检验显示,对于任何一种覆盖率,gpt3.5-turbo 和 code-cushman-002 之间没有统计学显著差异。另一方面,我们发现 StarCoder 和 OpenAI 模型之间在两种覆盖率类型上存在统计学显著差异(p值<0.05)。如表 IV 所示,StarCoder 的中位数语句(54.0%)和分支(37.5%)覆盖率均低于其他两种模型。Cliff's delta [55] 表明,gpt3.5-turbo 和 StarCoder 之间的语句和分支覆盖率的效应尺寸分别为大和中,code-cushman-002 和 StarCoder 之间的语句和分支覆盖率的效应尺寸分别为中和小。
然而,我们注意到 StarCoder 的中位数语句覆盖率和分支覆盖率都高于 Nessie(语句:54.0% vs. 51.3%,分支:37.5% vs. 25.6%)。虽然这种更高的覆盖率并不具有统计学意义,但结果表明,即使是使用可能比 OpenAI 模型规模更小和/或不同训练过程的LLM,也能达到与传统的最先进测试生成技术(如 Nessie [11])相当甚至更高的水平。此外,在 RQ2 中,我们展示了使用 gpt3.5-turbo 与 TESTPILOT 结果为更高覆盖率的测试套件,具有统计学显著差异,与 Nessie 相比。总的来说,这些结果强调了LLM-based测试生成技术在生成高覆盖率测试套件方面的潜力。
最后,我们注意到,使用 gpt3.5-turbo 为给定函数生成测试的中位时间为15秒,为给定软件包生成完整测试套件的中位时间为6分钟55秒。其中大部分时间用于查询模型,因此LLM的选择至关重要。例如,使用 StarCoder 和 code-cushman-002 为给定函数生成测试的中位时间分别为24秒和11秒,为完整测试套件生成测试的中位时间分别为10分钟48秒和4分钟53秒。所有这些性能数据表明,在在线设置(例如在IDE中)生成个别函数的测试,或者在离线设置(例如在代码审查期间)生成API的完整测试套件是可行的。
转述:何晨曦