GB10 是英伟达和联发科合作推出的产品,它将英伟达的 Blackwell 架构集成到 GPU 中。GB10 的 GPU 拥有 48 个 Blackwell SM 单元,核心数量与 RTX 5070 相同。CPU 部分则配备了 10 个 Cortex X925 核心和 10 个 Cortex A725 核心,因此性能相当强劲。如此强大的计算能力需要一个强大的内存子系统来支撑,这也导致了性能上的权衡取舍。
本文将重点分析 GB10 的内存子系统,从 CPU 端入手。
片上系统布局
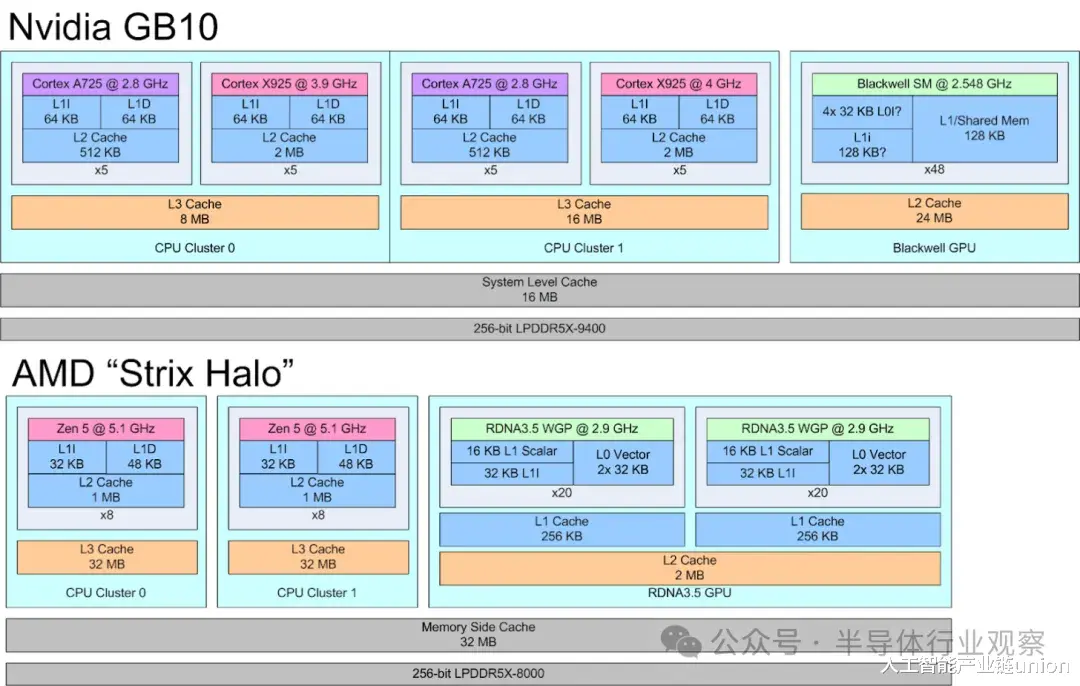
GB10的CPU核心分为两个集群。每个集群包含五个A725核心和五个X925核心。核心编号从每个集群内的A725核心开始,两个集群依次排列。所有A725核心的运行频率均为2.8 GHz。X925核心在第一个集群中的最高频率可达3.9 GHz,在第二个集群中最高频率可达4 GHz。
缓存和内存访问
Arm 的 A725 和 X925 处理器都具备可配置的缓存容量。GB10 在两个核心上都采用了 64 KB 的 L1 指令和数据缓存。所有 A725 核心都配备了 512 KB 的 L2 缓存,而所有 X925 核心都配备了 2 MB 的 L2 缓存。A725 的 L2 缓存采用 8 路组相联,延迟仅为 9 个时钟周期。实际延迟约为 3.2 纳秒,考虑到其 2.8 GHz 的低时钟频率,这个延迟表现相当不错。然而,其 L3 缓存的延迟却高达 21 纳秒以上,即超过 60 个时钟周期,表现不佳。
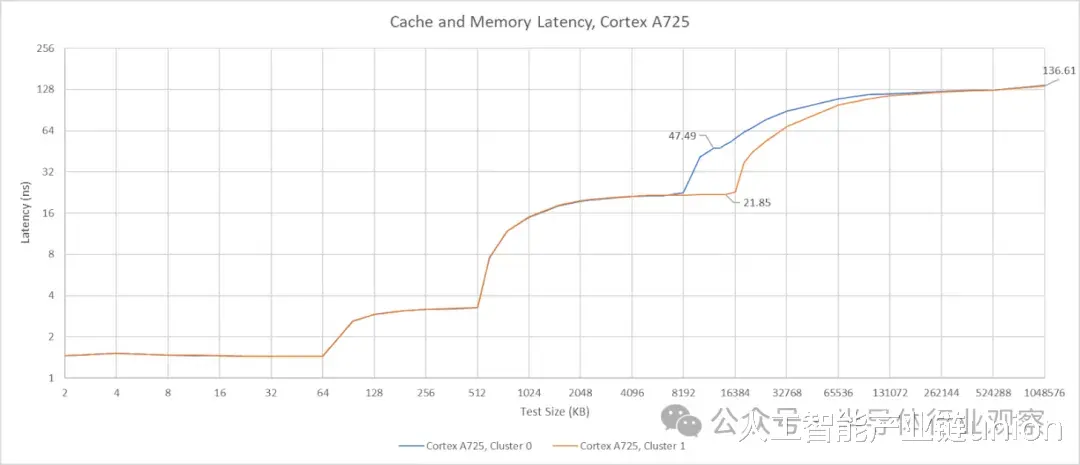
对两个集群的核心进行测试表明,第一个 CPU 集群拥有 8 MB 的 L3 缓存,而第二个集群拥有 16 MB 的 L3 缓存。我将它们分别称为集群 0 和集群 1。尽管容量不同,但两个集群使用 A725 核心时的 L3 延迟相同。当 L3 延迟如此之高时,512 KB 的 L2 缓存容量并不算大。选择 512 KB 的 L2 缓存选项可能减少了核心面积,从而使 GB10 能够实现更多核心。考虑到 A725 核心并非旨在提供高单线程性能,这样做是合理的。这项任务最好交给 X925 核心来完成。
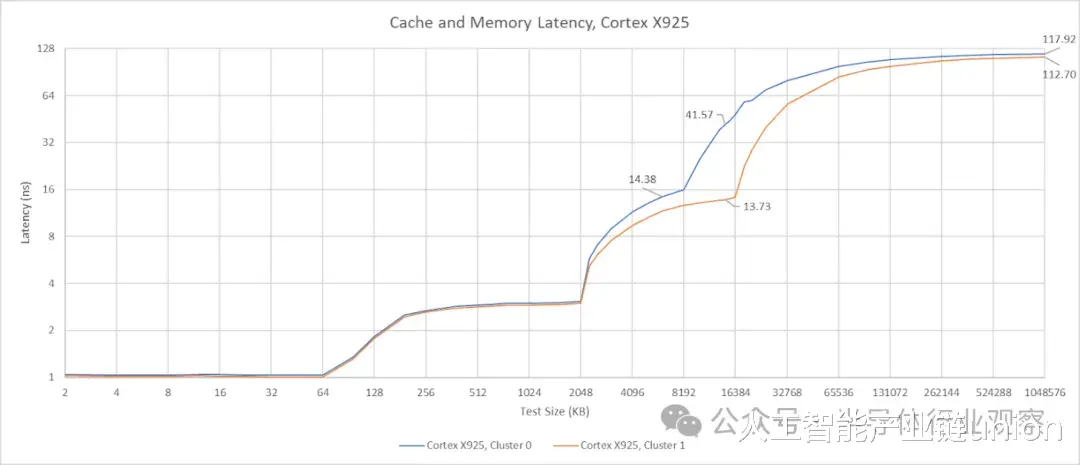
GB10 的 X925 核心配备 2MB、8 路组相联的 L2 缓存,延迟为 12 个时钟周期。令人惊讶的是,尽管 A725 和 X925 核心共享同一个 L3 缓存,但其 L3 延迟却低得多,仅为约 56 个时钟周期或约 14 纳秒。虽然这个 L3 延迟结果并不算惊艳,但至少在纳秒级上与英特尔 Arrow Lake 的 L3 缓存相当。更大的 L2 缓存与更大的 L2 缓存相结合,使得 GB10 的 X925 核心拥有更均衡的缓存配置,从而能够提供更高性能。
16 MB 的系统级缓存 (SLC) 位于 L3 缓存之后。由于其容量相对于 CPU L3 缓存而言较小,因此很难从延迟图中看出它的存在。来自集群 0 的延迟数据显示,SLC 的延迟约为 42 或 47 ns,具体取决于访问它的是 X925 核心还是 A725 核心。系统级缓存与任何计算模块的耦合度并不高,这通常意味着性能会降低,但可以服务于芯片上的多个模块。NVIDIA 表示,系统级缓存除了作为 CPU 的 L4 缓存外,还能“实现引擎之间高效的数据共享”。允许 CPU 和 GPU 之间进行数据交换而无需往返 DRAM,这很可能是 SLC 最重要的功能。
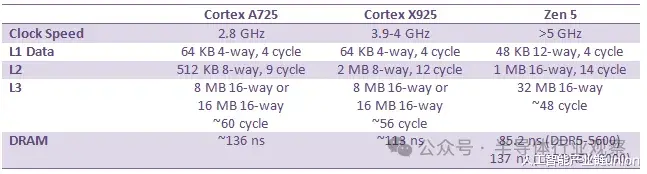
Strix Halo 主板上的 AMD Zen 5 架构拥有容量更小但速度更快的核心私有缓存。GB10 的 X925 和 A725 核心拥有不错的周期延迟,但 Zen 5 的时钟频率更高,因此其缓存速度最终更快,尽管 L2 缓存的优势并不明显。AMD 的 L3 缓存设计依然令人印象深刻,即使容量翻倍,延迟也更低。
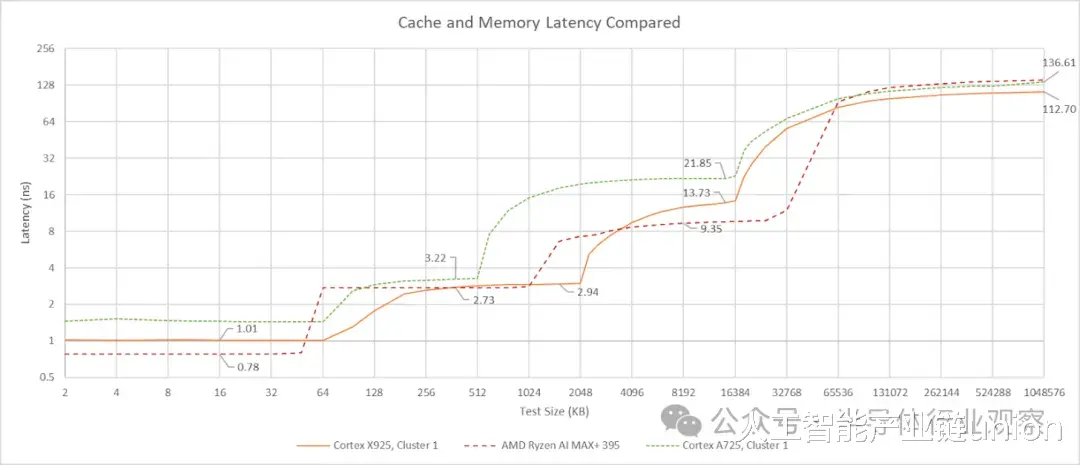
DRAM延迟是GB10的一大亮点。113纳秒的延迟对于一台典型的DDR5台式机来说可能略显缓慢,但对于LPDDR5X内存而言,这已经非常出色了。相比之下,华硕Strix Halo和英特尔Meteor Lake的DRAM延迟都超过了140纳秒。更快的LPDDR5X内存或许是GB10延迟表现不佳的原因之一。Hot Chips的幻灯片显示,GB10的内存总线速度最高可达9400 MT/s,而dmidecode的测试结果为8533 MT/s。将CPU核心与内存控制器集成在同一芯片上,也可能有助于降低延迟。
带宽
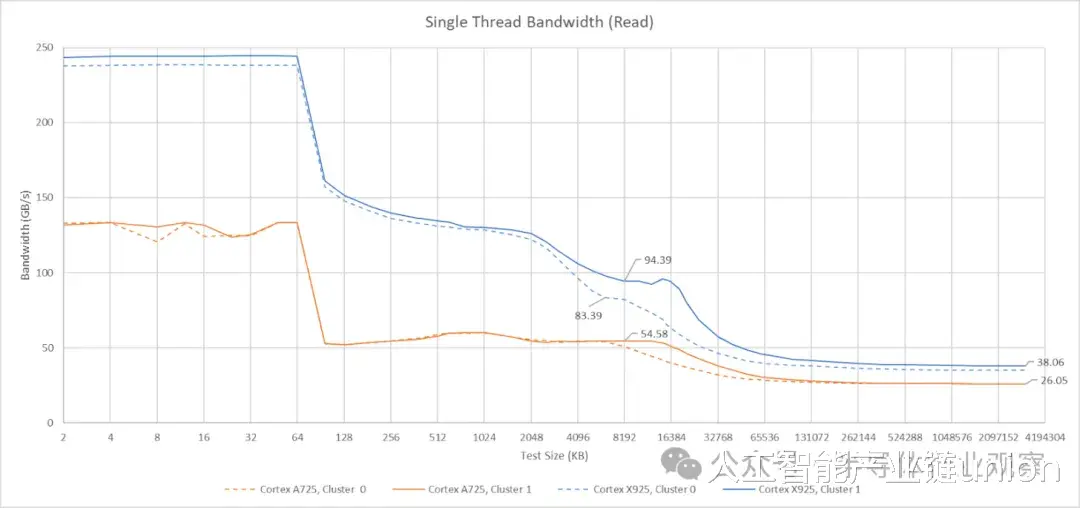
核心专用带宽数据比较直观。A725 核心可以从 L1 缓存读取 48 字节/周期的数据,并且似乎拥有 32 字节/周期的 L2 缓存数据通路。单个 A725 核心可以从 L3 缓存读取约 55 GB/s 的数据。X925 的带宽更出色。它可以从 L1D 缓存读取 64 字节/周期的数据,可能也拥有 64 字节/周期的 L2 缓存数据通路,并且可以维持近 90 GB/s 的 L3 缓存读取带宽。X925 核心的单核 DRAM 带宽也更高,达到 38 GB/s,而 A725 核心的单核 DRAM 带宽为 26 GB/s。
单个 AMD Zen 5 或 Zen 4 核心可以从 DRAM 读取超过 50 GB/s 的数据,从 L3 缓存读取超过 100 GB/s 的数据。这是一个有趣的差异,表明 AMD 允许单个核心排队处理更多的内存请求,但低线程工作负载很少需要如此高的带宽,我怀疑这不会造成太大的影响。
在多线程工作负载中,内存层次结构中的共享组件面临更大的压力,因为激活的核心越多,带宽需求往往也越大。通常,我会通过让每个线程遍历一个独立的数组来测试多线程带宽。这样可以避免访问合并,因为没有两个线程会请求相同的地址。此外,它还能显示缓存容量的总和,因为每个核心都可以将测试数据的不同部分保存在其私有缓存中。GB10 的每个集群核心共有 15 MB 的 L2 缓存,但 L3 缓存只有 8 或 16 MB。任何能放入 L3 缓存的数据,其很大一部分都会被缓存在 L2 缓存中。
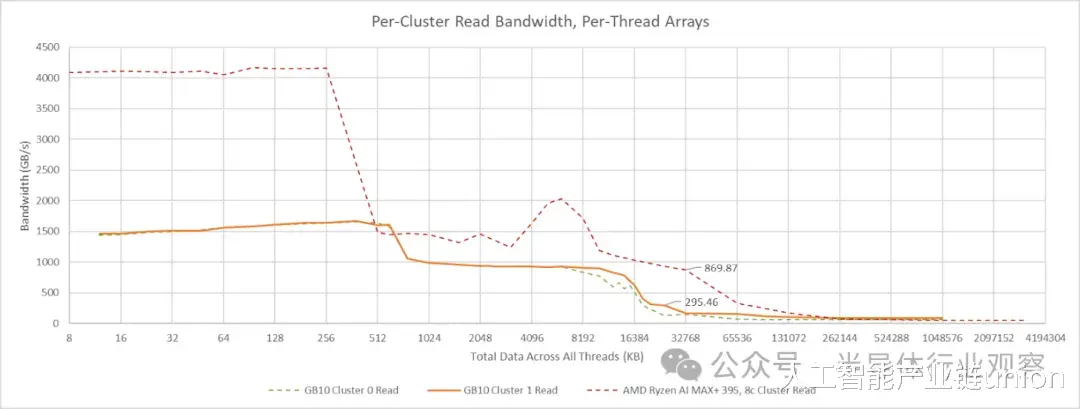
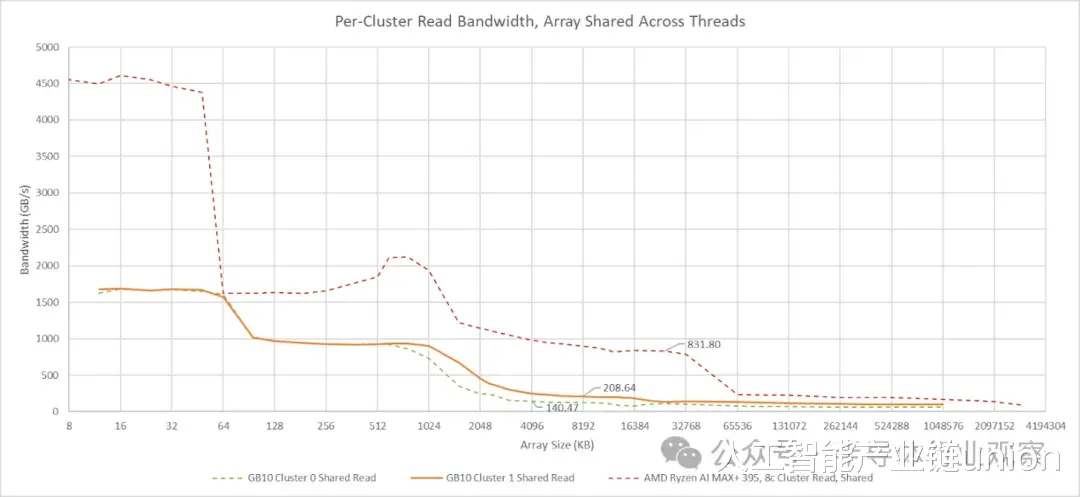
将所有线程指向同一个阵列可能会导致访问合并时高估带宽,但这似乎只会在共享缓存之后才会发生。我最初在 Zen 2 和 Skylake 架构上验证了带宽测试方法。在这些架构上,共享阵列的测试结果与 L3 性能计数器数据基本一致。在 GB10 上使用共享阵列的测试结果提供了另一个评估 L3 性能的数据点。结合使用线程私有阵列的测试结果,这些结果表明 GB10 的 L3 带宽远低于 AMD 的 Strix Halo。然而,其 L3 带宽仍然可观,超过 200 GB/s,并且可能足够使用。
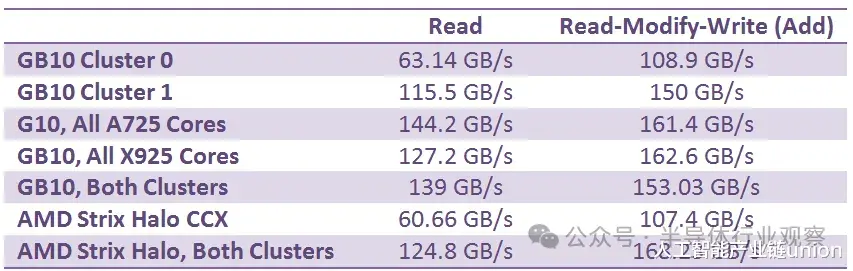
GB10 的两个 CPU 集群除了 L3 缓存容量外,还具有不对称的外部带宽。集群 0 有点像 Strix Halo CCX(核心复合体)。集群 1 则让人联想到 AMD GMI-Wide,读取带宽超过 100 GB/s。将读写比例调整为 1:1 后,测得的带宽显著提升,这表明两个集群拥有独立的读写路径,且带宽相近。GB10 的 CPU 集群采用Arm 的 DynamIQ 共享单元 120 (DSU-120) 构建,该单元最多可配置四个 256 位 CHI 接口,因此两个集群的接口数量可能不同。
与 Strix Halo 类似,GB10 的 CPU 端带宽比典型的客户端配置更高,但无法充分利用 256 位 LPDDR5X 总线。CPU 工作负载通常对延迟更敏感,对带宽的需求则相对较低。两款大型集成显卡芯片中的内存子系统都体现了这一点,并着重利用缓存来提升 CPU 性能。
异构集群配置?
以上观察表明,集群 1 侧重于性能优化,而集群 0 则侧重于密度。缓存是现代芯片中最大的面积占用部件之一,因此将 L3 缓存容量削减至 8 MB 几乎可以肯定是为了节省面积。集群 0 的外部接口可能也更窄,因为减少集群外部的布线也能节省面积。但英伟达和联发科并没有完全针对每个集群进行专门设计。
集群 0 和集群 1 的核心配置相同,均为五个 X925 核心和五个 A725 核心。X925 核心注重最高性能,而 A725 核心则注重密度。因此,A725 核心在高性能集群中显得格格不入,尤其是在 L3 缓存延迟超过 20 纳秒的情况下,其 L2 缓存容量仅为 512 KB。

我琢磨着,如果把十个 A725 核心集中到集群 0 以提高密度,把十个 X925 核心集中到集群 1 以提高性能,全面采用集群专用化方案会不会更好?从两个异构集群简化为两个同构集群也能简化操作系统调度器。例如,操作系统调度器可以更轻松地将工作负载限制在单个集群内,从而让硬件控制第二个集群的时钟频率或使其断电。
带宽负载下的延迟
延迟和带宽往往密切相关。高带宽需求会导致请求在内存子系统的各个队列中积压,从而推高平均请求延迟。理想情况下,内存子系统既能提供高带宽,又能防止带宽密集型线程影响对延迟敏感的线程。在这里,我测试了同一集群中,使用 X925 核心与其他核心的不同组合来产生带宽负载时的延迟情况。
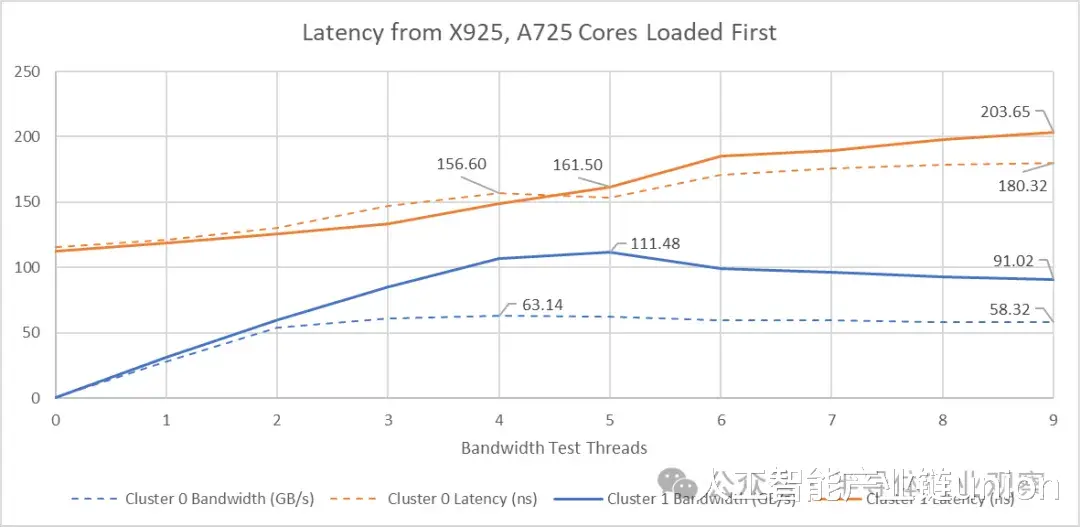
两个集群在所有 A725 核心都产生带宽负载的情况下都达到了最大带宽。X925 核心的加入导致总带宽下降,同时延迟上升。反转核心负载顺序表明,X925 核心会专门造成内存子系统资源争用。当四个 X925 核心请求尽可能多的带宽时,延迟达到最大值。这似乎表明 X925 核心不知道何时应该降低速度以避免独占内存子系统资源。当 A725 核心加入后,GB10 似乎意识到了问题所在,并开始更好地平衡带宽需求。带宽得到改善,令人惊讶的是,延迟也随之降低。
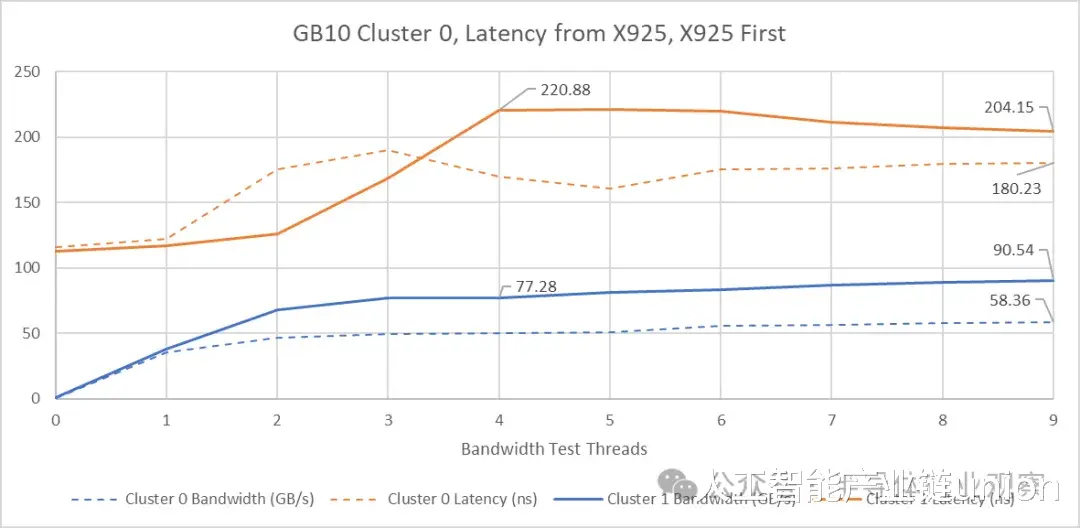
尽管集群 1 拥有更高的可用带宽,但其延迟控制能力却更差。这与我们对 AMD GMI-Wide 架构的测试结果不符,在 GMI-Wide 架构中,更高的集群外带宽在高带宽负载下能够带来更好的延迟控制。
在两个集群上对核心进行负载测试表明,在所达到的带宽范围内,GB10 的延迟低于 Strix Halo。GB10 较低的基线延迟和来自集群 1 的高外部带宽使其遥遥领先。

将GB10的集成显卡(iGPU)考虑在内,会带来额外的挑战。与Strix Halo类似,iGPU对带宽的需求增加会导致CPU端延迟上升。GB10的DRAM基础延迟优于Strix Halo,并且在GPU带宽需求适中的情况下也能保持较低的延迟。
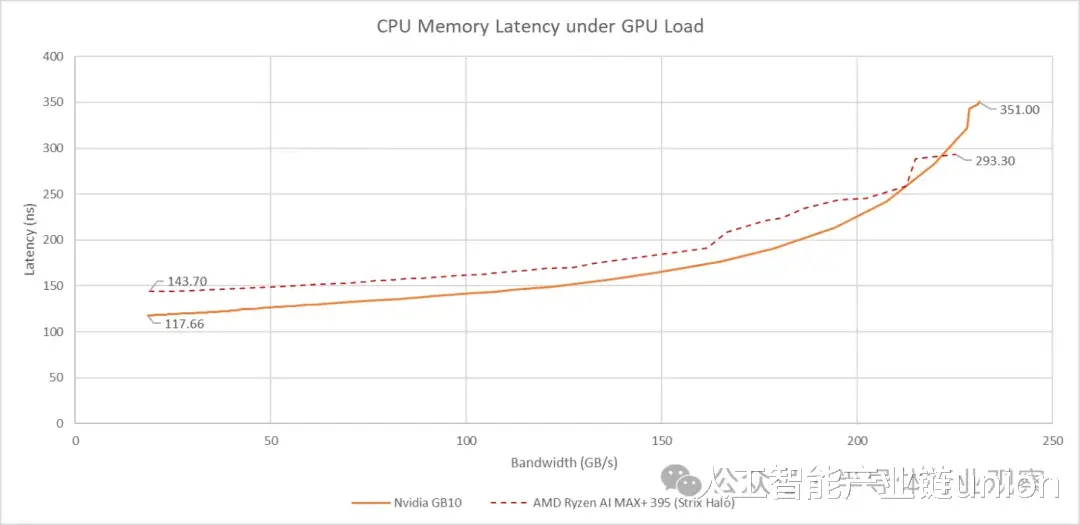
然而,GB10架构对GPU高带宽的需求会挤压CPU的带宽。当GPU带宽达到231GB/s时,CPU端的延迟会超过351纳秒。
上述测试中,我只使用了GPU来产生带宽负载,并运行了一个CPU延迟测试线程。如果同时使用高CPU和GPU带宽需求,情况会变得更加复杂。
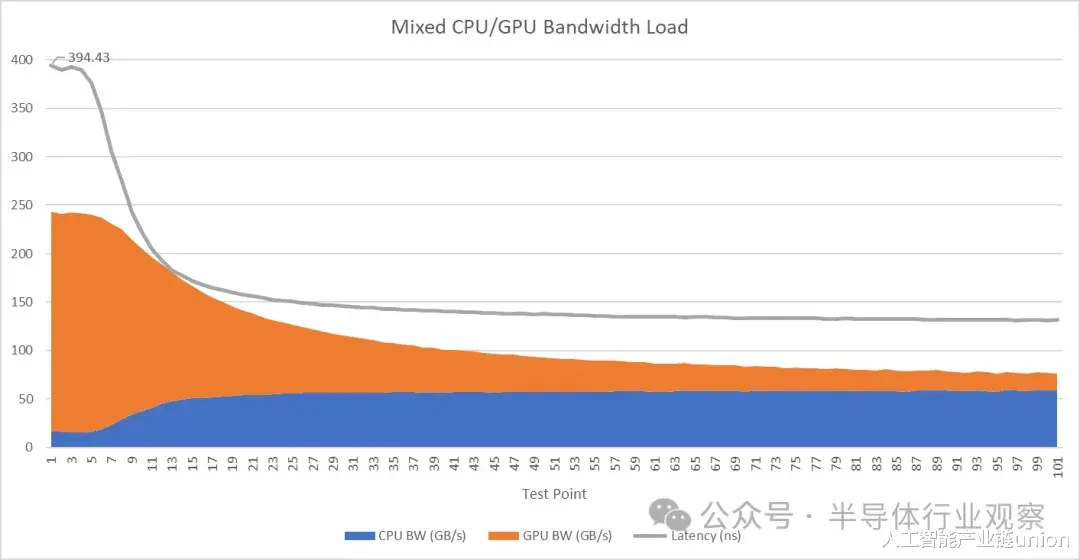
集群 1 上的两个 X925 核心竭尽所能地占用带宽,GPU 也同样如此,导致性能最高的 X925 核心的延迟接近 400 纳秒。进一步分析 CPU 和 GPU 的带宽使用情况,可以发现 GPU 在带宽测试线程中占据了主导地位。
核心间延迟
内存访问通常以垂直方式遍历缓存层次结构,即某一级缓存未命中会向下一级缓存传递。然而,为了保持缓存一致性,内存子系统可能需要在同一级缓存之间执行数据传输。这样做可能相当复杂。内存子系统必须确定是否存在对等缓存,以及哪个对等缓存可能拥有更新的缓存行副本。Arm 的 DSU-120 具有一个 Snoop 控制单元,它使用 Snoop 过滤器来协调核心复合体内的对等缓存传输。Nvidia/Mediatek 的高性能一致性架构 (HPCF) 负责维护集群间的缓存一致性。
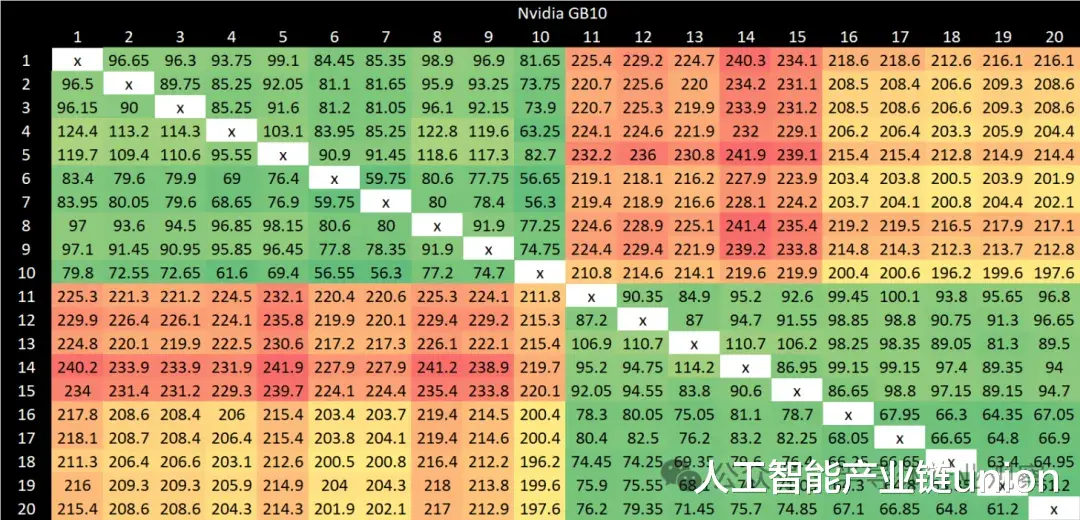
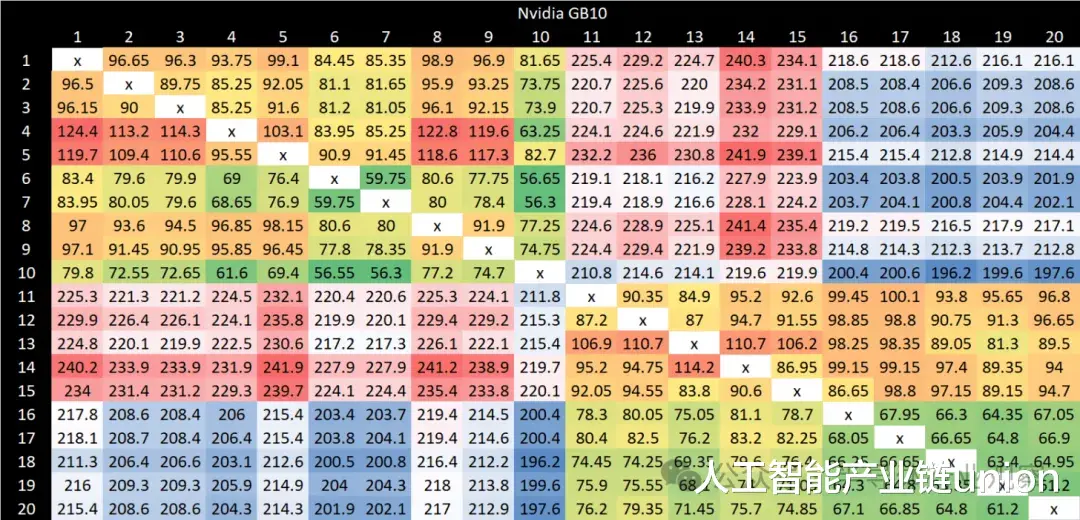
通过对所有结果点应用着色方案,可以清晰地看到 GB10 的集群边界。每个集群内部的结果也远非均匀。为集群内和集群间点设置不同的着色方案可以更突出这一点。X925 核心通常能提供更好的集群内延迟结果。最佳延迟情况是指同一集群内 X925 核心之间的传输。最差延迟情况出现在不同集群的 A725 核心之间,最高可达 240 纳秒。
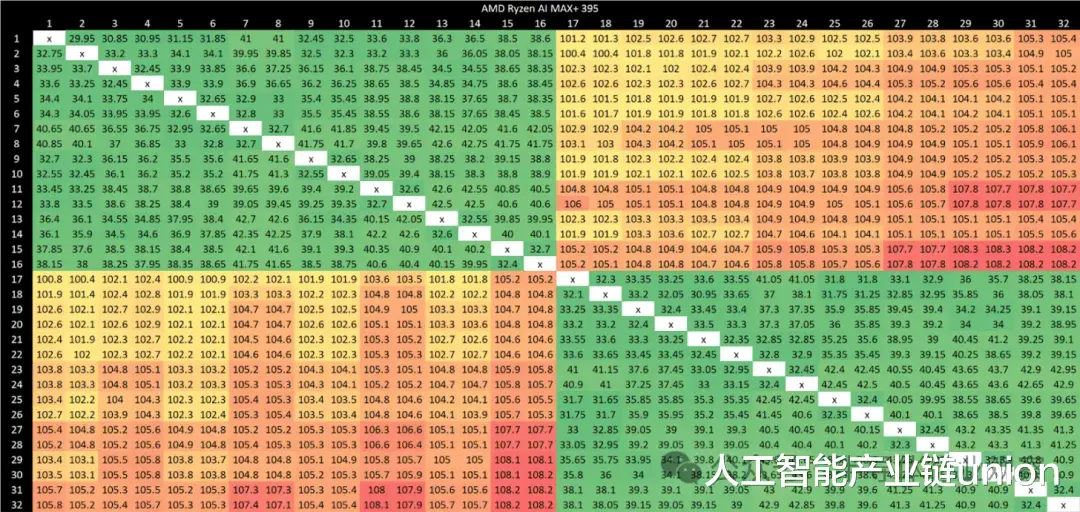
与 Strix Halo 相比,GB10 的核心间延迟总体偏高。Strix Halo 的跨集群延迟则控制在 100 纳秒左右。虽然这比 AMD 桌面级处理器的表现略逊一筹,但远胜于 GB10 的 200 纳秒。在集群内部,AMD 的延迟均低于 50 纳秒,而 GB10 即使在最佳情况下也只能达到 50-60 纳秒。
结语
与Strix Halo相比,GB10的CPU架构在密度方面进行了优化。GB10拥有20个CPU核心,而Strix Halo只有16个,GB10是通过高度异构的CPU配置实现的,并且缓存占用较少。我最初的想法是,在其他条件相同的情况下,我更倾向于32MB的单级高速缓存,而不是16MB的L3缓存和16MB的低速系统级缓存。话虽如此,性能是一个复杂的问题,我仍在对Strix Halo和GB10进行基准测试。GB10的内存子系统也有亮点。对于LPDDR5X来说,它的DRAM延迟非常出色。联发科还为一个集群提供了超过100GB/s的外部读取带宽,这是AMD迄今为止在任何客户端设计中都没有做到的。
CPU端带宽是另一个值得关注的细节,两款芯片有很多共同之处。无论是GB10还是Strix Halo,CPU核心都无法充分利用LPDDR5X的带宽。256位内存总线主要面向GPU,而非CPU。GPU的高带宽需求可能会在两个内存子系统中都对CPU造成压力。或许Nvidia/Meditek和AMD都针对那些对CPU和GPU性能要求不高的工作负载进行了优化。
我希望看到英伟达和AMD继续改进大型集成显卡的设计。像GB10和Strix Halo这样的产品可以实现更小的尺寸,并规避目前独立显卡普遍存在的显存容量问题。从发烧友的角度来看,它们非常吸引人。希望这两家公司未来能够改进设计,并降低产品价格。