标签: cuda



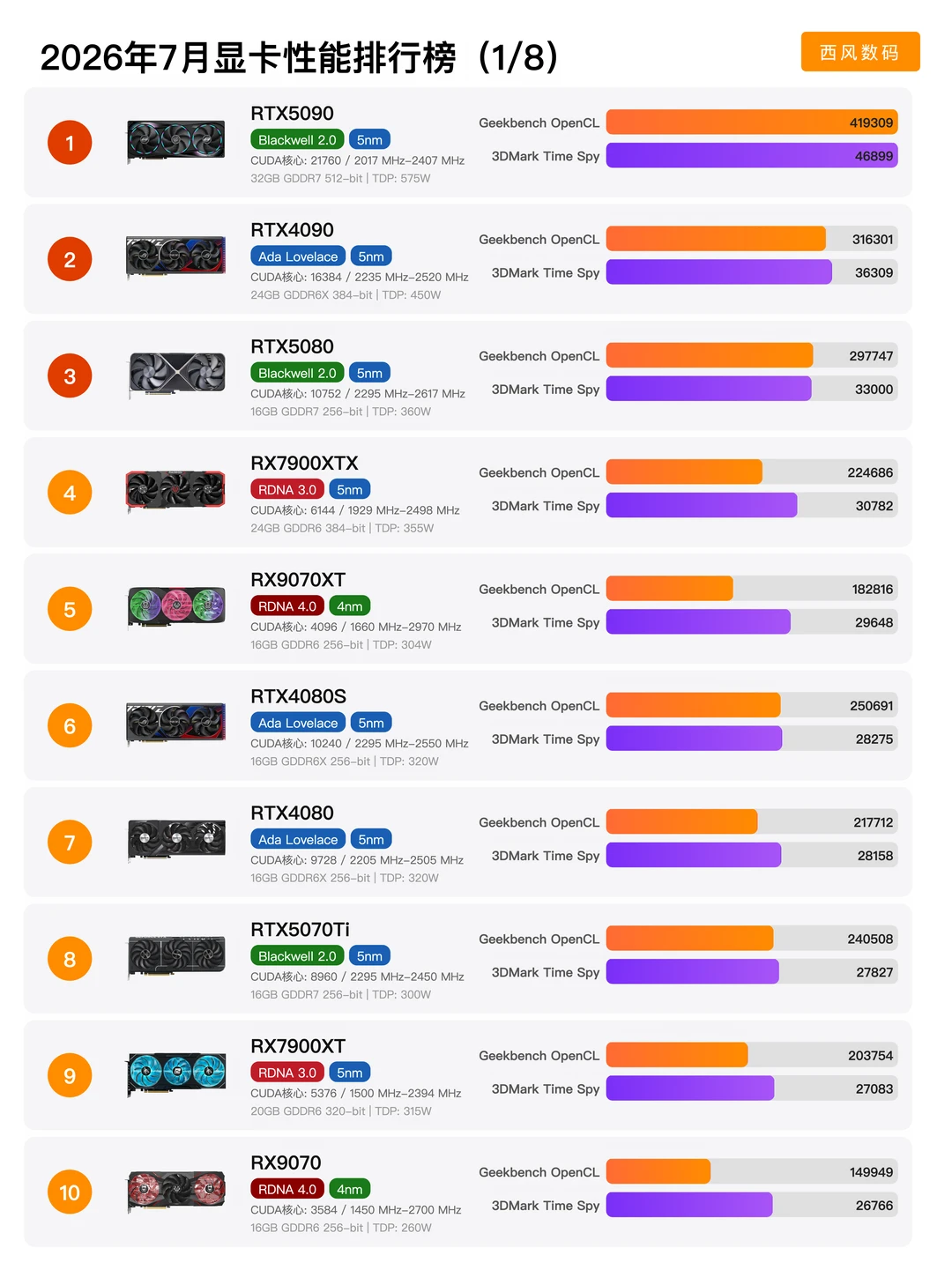



华为云全自研工业级AI开发专区上线:打破CUDA垄断,国产份额首破40%当英伟达
华为云全自研工业级AI开发专区上线:打破CUDA垄断,国产份额首破40%当英伟达CUDA框架长期主导全球AI开发工具链时,中国市场的结构性变化正在加速。2026年6月5日,华为云在上海发布新一代模型训推平台ModelArtsNext,并推出全自研工业级AI开发专区,首次实现了从芯片到应用模型的完整国产化技术栈。这背后是2025年国产AI芯片市场份额首次稳定突破40%的拐点,以及华为昇腾芯片性能对标国际巨头的实质性进展。

中美之间的算力差距到底有多大?根据公开的行业统计,中国总算力规模稳居全球第二
中美之间的算力差距到底有多大?根据公开的行业统计,中国总算力规模稳居全球第二,占全球市场两到三成,和美国咬得很紧。但只要你把目光锁定在人工智能训练最烧钱的那种尖端算力,也就是用英伟达顶级显卡堆起来的智算集群上,差距立马就显现出来了。差距的源头非常简单,就是芯片。目前全球能大规模支撑前沿大模型训练的加速卡,几乎被英伟达一家给包圆了。从A100到H100,再到后来的H200、B200,这些卡不但性能吊打其他同类产品,还因为有一个叫CUDA的软件生态,让全球的人工智能开发者都主动或被动的绑在了英伟达的战车上。这些芯片的核心制造工艺仰仗台积电,设计工具用到美国技术,所以美国一纸出口管制,直接切断了高端GPU流入中国大陆的渠道。这个过程很多人都有印象,2022年先禁了A100和H100,英伟达就搞出A800和H800来绕开限制,主要阉割了卡与卡之间的高速互联带宽,H800的NVLink带宽被砍到了A100时代的水平,让大规模并行训练的效率打了折扣。结果到2023年10月,老美再次加码,连这些特供版也一并禁了。此后英伟达为了不丢掉中国市场这块肥肉,又鼓捣出了完全合规的H20、L20等芯片。H20的纸面算力只有H100的百分之十五左右,显存倒是给到了96GB,但总体上说,它更适合做大模型推理,不太适合从头预训练一个万亿参数级的巨型模型。你看这个管制一步步加码,就让国内公司能获得的顶级训练算力极度受限。没办法,国内大厂和初创企业只能走两条路,一是继续用之前囤下的高端存货精打细算,二是加速切换到国产芯片。华为的昇腾系列自然被推到最前线。昇腾910B自2023年下半年起逐步放量,它的半精度浮点算力与A100大致相当,随后在2024年推出的昇腾910C更进一步,性能与H100的单卡差距进一步缩小。华为云和合作伙伴基于数千张昇腾卡构建集群,成功支持了科大讯飞星火大模型、鹏城实验室的系列模型训练,官方披露的训练效率能接近A100方案的九成。可问题不在单卡性能,而在软件生态。全世界的深度学习框架和模型代码几乎都是围绕CUDA写的,突然要迁移到华为的昇思MindSpore框架或适配CANN算子库,相当于把房子换个地基,大量的底层代码需要重写,算子需要重新调试,显存管理逻辑也要改。开发者社区里普遍反映,迁移成本不低,训练过程中遇到的一些隐性bug,花的时间比预期多不少。这就意味着,即使国产卡的硬件算力上来了,由于软件适配和生态的成熟度差距,实际产出效率还是得打一个折扣,算下来有效算力进一步被拉低。不过事情也不是一边倒。国内有一个美国没有的优势,那就是庞大的内需市场和应用场景。中国的移动互联网、智能制造、自动驾驶、智慧城市,这些领域对算力的消耗巨大,其中绝大部分需求属于推理计算。而推理计算对芯片的要求比训练低不少,H20、L20这类特供芯片以及国产的寒武纪、海光、昇腾推理卡完全能够胜任,甚至因为显存大,部分场景比英伟达的高端卡还划算。所以你会发现,虽然训练前沿模型我们吃点亏,但在真正落地的应用端,中国人工智能服务的覆盖面和使用体验一点不差,甚至因为场景磨砺,在推荐算法、图像识别、语音交互上比美国还强。此外,过去两年国家主导的“东数西算”工程已经把算力当成像水电气一样的基础设施来建设。多个西部省份建起了超大型数据中心,里面开始成规模地部署国产智能计算芯片。2025年,一些城市的智算中心算力规模已经达到数千PFLOPS,能够同时支撑几百家企业的训练和推理任务。这种举国体制的力量,让算力的底座在慢慢夯实。与此同时,国内的服务器制造和液冷散热产业链已经做到全球领先,美国搭建十万卡集群,也得从中国采购大量的光模块和制冷设备。双方在产业链上是相互缠绕的,谁也没法完全甩开谁。所以回到最初的问题,中美之间的算力差距到底有多大。简单说,在最尖端的、支撑下一代通用人工智能训练的那部分算力上,差距是明显的,存在一个数量级的落后,核心卡点就在于能拿到什么级别的芯片以及有多少张。但在通用算力、超算和推理算力这些更宽泛的层面,差距要小得多,甚至互有胜负。这种结构性的差距意味着短期内没法在模型参数量的军备竞赛上直接硬拼,但可以凭借算法优化、数据质量提升和应用创新来打差异化。而且随着国内半导体产业链一点点补课,这种差距的绝对值正在逐步缩小,只不过还需要时间和耐心。




传统PC生态长期由英特尔x86架构锚定,但随着端侧AI算力需求深度下沉,这套成熟
传统PC生态长期由英特尔x86架构锚定,但随着端侧AI算力需求深度下沉,这套成熟体系的结构性短板彻底暴露。老旧架构的算力拆分、能效冗余以及原生AI算力的缺失,让其难以适配本地化大模型推理的核心诉求,行业原有壁垒正在持续消解。依托Arm架构重构终端算力底座,叠加自身CUDA生态的绝对垄断优势,英伟达完成了云端到终端的算力闭环打通。千万级开发者生态的无缝迁移,形成了旁人无法复刻的软性壁垒,彻底跳出了传统PC芯片的硬件内卷。
梁文峰称英伟达显卡没技术英伟达的护城河是CUDA,如果他是单拎出显卡这个硬件来说
梁文峰称英伟达显卡没技术英伟达的护城河是CUDA,如果他是单拎出显卡这个硬件来说,也可以理解。






2026年4月,一个名叫梁文锋的广东湛江80后,让硅谷大佬们集体睡不着觉了。
2026年4月,一个名叫梁文锋的广东湛江80后,让硅谷大佬们集体睡不着觉了。他带领的DeepSeek团队,干了一件近乎“疯狂”的事,花了五个月时间,把1.6万亿参数的大模型底层代码,硬生生从英伟达的CUDA迁移到了华为昇腾架构上。这不是小修小补,是全栈重写。一位参与迁移的工程师打了个比喻:“难度大概相当于在飞机飞行过程中,把发动机拆下来换掉。”整个工程重写了40万行算子,精度对齐误差控制在0.5%以内。这么多年,大家都觉得离了英伟达的芯片就玩不转AI。美国守着算力这张底牌,以为谁也翻不了天。梁文锋偏不信这个邪。他直接拉上华为和国内另外七家芯片厂商,模型和国产芯片同步研发、同步上线。从CUDA到CANN,从跟随到领跑,这一换,直接把美国守了十几年的算力底牌撕开了一道口子。黄仁勋是真的坐不住了。他在媒体访谈中罕见发飙,当众反驳“芯片是浓缩铀不该出口给中国”的说法,警告过度限制,只会逼中国建立完整的自主生态。这话翻译过来就是:你们再逼下去,他们真不用我们了。而事实确实如此。DeepSeekV4适配的华为昇腾950PR芯片,单卡算力是英伟达对华特供版H20的2.87倍,采购价格却只有H200的三分之一到四分之一。消息一出,阿里巴巴、字节跳动、腾讯等大厂立刻向华为追加了数十万颗昇腾芯片订单。最狠的是,梁文锋压根不给资本指手画脚的机会。他直接和间接持有公司约84.29%的股权,拥有几乎100%的表决权。别人融资是为钱低头,他是让资本陪跑。有人说他是“比任正非更危险的男人”,也有人说他冒着自己沦为二流大模型的风险,给中国AI趟路。但他只说了一句大实话:“别人的地基再稳,也不如自己的踏实。”从通信到AI,从任正非到梁文锋,中国人被卡脖子的地方,迟早要长出自己的力量。这条路,已经趟出来了。欢迎大家点赞、评论、转发,让更多人看到!














刘文峰说英伟达的显卡在技术上毫无秘密可言。是因为黄仁勋提前十几年押住了人工智能
刘文峰说英伟达的显卡在技术上毫无秘密可言。是因为黄仁勋提前十几年押住了人工智能。并且提前十几年构建了CUDA生态,所以才有了现在的英伟达。技术可以被模仿,但是战略远见和生态布局难以被模仿.你看了吗?现在就是很多人的专家逻辑,一方面说英伟达的成功是因为人家在十几年前提前布局,提前做了CUDA这个护城河,所以才有了英伟达现在的成功.然后又接着说现在的人工智能投入这么多钱没有用,因为现在看不到盈利的方向.没有任何一项核心技术在刚出来的时候都是赚钱的,互联网、智能手机、cuda生态,在研发早期都是投入大。回报率低,甚至很多人看不到以后会不会挣钱?当年马云找融资的时候,很多人根本不看好阿里巴巴,因为觉得投入这么大根本没有任何意义,不就是最好的例子吗?如果十几年前黄仁勋对投资者说,在未来十几年后,英伟达一年的收入可以达到几千亿美元,净利润可以突破1000亿美元,你觉得当时的投资者会信吗?肯定会认为黄仁勋是信口开河,因为在当时所有的人都不看好英伟达,未来有一天会在人工智能里,行业是领头羊,会挣这么多钱。一方面说英伟达现在的成功是十几年前提前布局,所以现在必须要有战略眼光提前布局,然后又说现在的人工智能看不到盈利模式,没有多大的商业价值等到人工智能在未来十几年后有了商业价值专家,然后又说人家人工智能之所以成功,是因为人家十几年前提前布局,并没有什么技术可言。但问题来了,现在你为什么不提前布局呢?为什么要等到事后诸葛亮呢?现在已经给了你很多机会了。原因很简单,因为我们对现在能挣钱的行业感兴趣,对未来5年甚至十几年能挣钱的行业不感兴趣,我们关心的不是未来能不能挣钱,我们关心的是现在能不能立刻马上能挣钱这也是为什么我们在生物医药操作系统,航空发动机高端机床等领域。还没有那么厉害的主要原因,因为这些领域都是投资大,技术含量高,短时间内根本看不到盈利,所以没有企业愿意花这么长时间,这么多资金去投入.现在美国之所以投入这么多钱去建人工智能,说白了,人家看中了未来十几年人工智能领域的发展,人家已经提前做好了布局。等你到时那时候你再说人工智能重要了,其实已经晚了.现在说人工智能没有用,就好比十几年前说互联网没有用,其实都是一样的.


AI写CUDA算子国产芯片不行?上交方法直线拉升,DeepSeek也适用
GPT-5.2 写 CUDA 算子,正确率 92%。同样的模型,给华为 Ascend NPU 写算子,正确率只有 4%。不是模型变笨了,是它压根没见过这类代码。公开数据几乎为零,专家寥寥无几,编译报错你还看不懂—这就是"新硬件冷启动"的真实处境...
中科院团队提出SparseRL,深度强化学习可自动生成高性能CUDA代码
近日,中科院计算所团队提出了一种名为 SparseRL 的新框架,首次将深度强化学习引入稀疏 CUDA 代码生成任务。简单来说,就是让 AI 学会根据稀疏矩阵的结构,自动生成最优的 CUDA 实现代码。实验显示,在经典的 SpMV 任务上,...
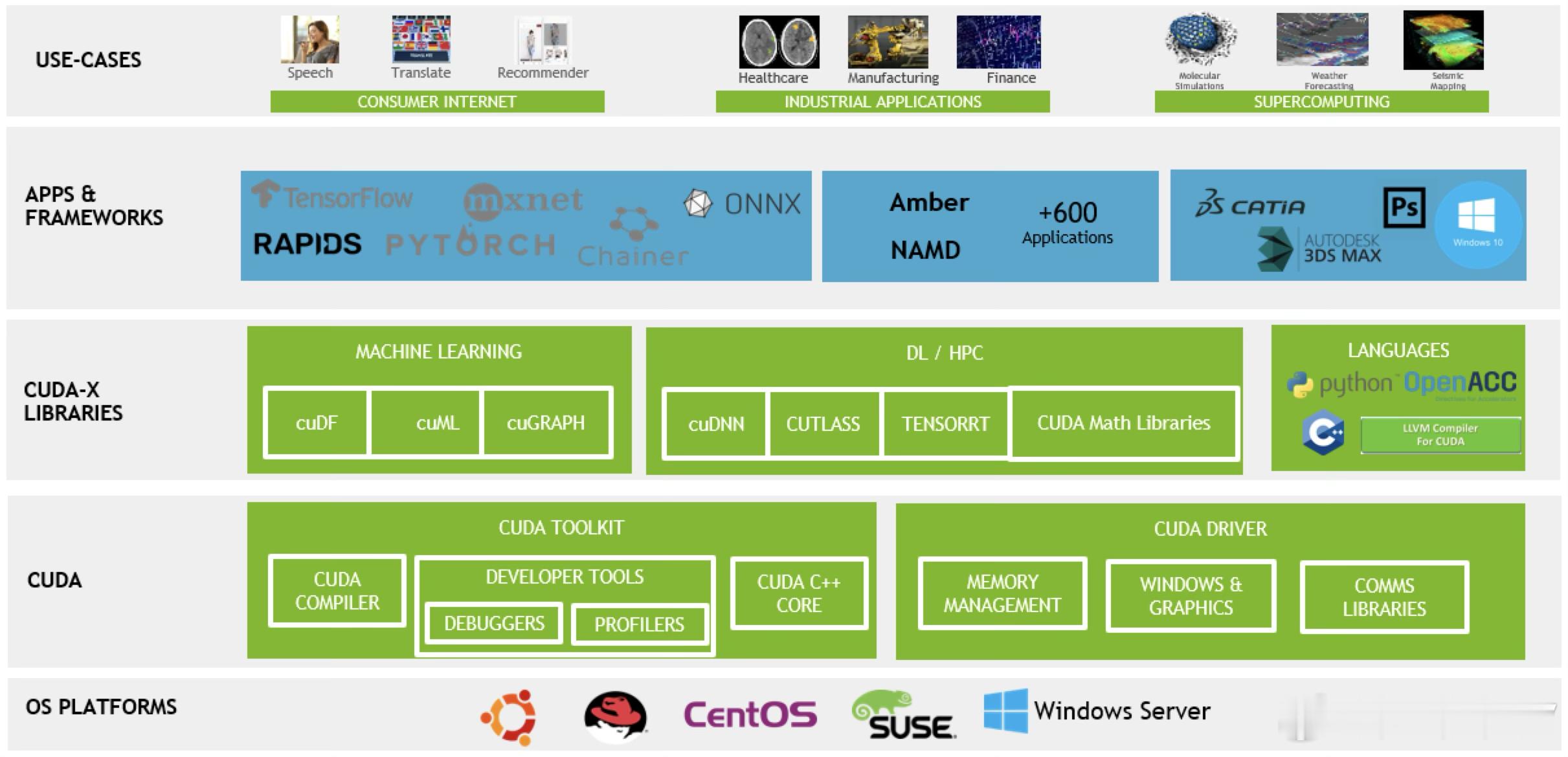
模型也是一种“CUDA”英伟达为何要260亿美金砸向开源模型?
通俗来说,CUDA 的库就是英伟达替开发者写好的现成工具包,开发者不需要从零开始,调用 CUDA 中对应的库就能完成特定任务。最主流的 AI 框架,底层都对 CUDA 做了深度优化。这意味着全球绝大多数 AI 模型的训练和推理,实际上...


一聊到芯片就躲不开英伟达,一个CUDA就把底层架构定死了。不过到了芯片2.0时代
一聊到芯片就躲不开英伟达,一个CUDA就把底层架构定死了。不过到了芯片2.0时代,中国在终端芯片上反而迎来换道超车的机会。以前AI在云端、在数据中心,“吞吐量多大”“算力多高”是核心竞争力。但现在芯片正走进手机、车、...

英伟达护城河被AI攻破,字节清华CUDA Agent,让人人能搓CUDA内核
近日,来自字节跳动 Seed 团队和清华大学 AIR 的新研究 CUDA Agent,在 AI 领域引发了不小的轰动。研究人员训练了一个能够编写快速 CUDA 内核的模型:不只是正确的内核,而是真正经过优化的内核。在简单/中等内核上,它的性能...

肌肉车黄金时代绝唱!1971款普利茅斯Hemi 'Cuda敞篷330万美元落槌
在Mopar肌肉车的收藏版图中,“稀有”二字有着无数种诠释,但1971款普利茅斯Hemi 'Cuda敞篷版,将这份稀有推到了极致—全年仅量产12台,搭载传奇426 Hemi引擎,既是普利茅斯E-body系列末代敞篷车型,也是426 Hemi引擎的末代...
英伟达的GPU是AI算力最优解吗?能打破英伟达CUDA的垄断地位吗?
当然一云多芯的调度,英伟达也是有优势的,它基于CUDA打造基于英伟达的GPU算力调动中心,而且还提供了AI算子库以及许多开发者,对于很多中小型企业非常有利!但对于大型企业和政企可能需要打造专属的体系,可能需要摆脱对于英...
CUDA护城河正在失效,英伟达试图建立新的壁垒
导读:CUDA护城河正在失效,英伟达自己比任何人都清楚这一点。收购 Groq 以及推出一系列专用芯片,并非简单的产品线扩张,而是黄仁勋在 CUDA 的旧城墙之外,被迫构建的一套全新的壁垒。算力战争的终局,将不再是单一软件生态的...



天下苦CUDA久矣,又一国产方案上桌了
终于,那个让开发者喊了无数次“天下苦CUDA久矣”的僵局,现在迎来了一个不一样的国产答案。KernelCAT:计算加速专家级别的Agent 这几年,AI领域的热闹几乎是肉眼可见的。模型在密集发布,应用数据持续走高,看上去一切都在...


“什么?中国不买了?!”听说消息的特朗普差点把桌上的汉堡惊掉,“我顶着一屋子人
“什么?中国不买了?!”听说消息的特朗普差点把桌上的汉堡惊掉,“我顶着一屋子人的反对特意开的绿灯——那些家伙吵得比推特评论区还热闹!结果他们居然…不买了?!”特朗普这回是真的被整不会了。美国本以为自己掌握了主动权,却被中国这一出“说不买就不买”的反转打了个措手不及。美国政府这回的操作堪称戏剧。前脚还对中国芯片企业严防死守,后脚却又突然宣布“有限开放”:英伟达可以给中国客户卖H20芯片,但条件是每卖一块都得把四分之一的收入交到美国口袋里。在特朗普看来,这是笔稳赚不赔的买卖——既能用“阉割版”芯片赚得盆满钵满,又能靠技术生态绑定中国企业,顺带还能堵上国会山那群鹰派的嘴。可他万万没料到,中国企业压根不接这茬,让这场精心设计的“交易”落了空。这款芯片本就是英伟达为了规避美国出口禁令,专门给中国市场定制的“特供版”,性能只有其旗舰产品H100的15%-30%,仅能满足部分AI推理场景,完全达不到万亿级大模型训练的核心需求。说白了,这就是一款被刻意削弱性能、用来清库存的产品,美国所谓的“开放”,本质上是想用残次货换真金白银。更关键的是,美国的政策反复早已消耗了中国企业的信任。去年4月,特朗普政府刚以“国家安全”为由,禁止英伟达对华销售H20芯片,导致英伟达取消大量订单、损失超55亿美元,股价直接暴跌6%。短短三个月后,又突然松口放行,还附加了25%的收入分成条件,这种朝令夕改的操作,让中国企业不得不警惕“合规陷阱”——今天能放行H20,明天说不定就会再次禁售,谁也不愿把产业链安全绑在反复无常的美国政策上。特朗普之所以敢拍板这项政策,无非是笃定中国离不开英伟达的芯片和其背后的CUDA生态。可他忽略了一个关键变化:在持续的技术封锁下,中国国产芯片已经实现了从“可用”到“可采”的突破,不再需要靠“残次货”将就。中国信通院的数据显示,2024年国产AI芯片在数据中心的份额已从12%跃升至25%,华为昇腾910B、寒武纪思元系列等产品订单激增,其中昇腾910B在推理算力领域已能自给自足,其CANN生态还能兼容80%的CUDAAPI,支持85%的CUDA算子自动转换,虽然存在15%-20%的性能损耗,但完全能满足主流场景需求。美国的策略逻辑其实很清晰:中国能生产什么,就放开什么,试图用成熟生态和价格优势冲击国产替代节奏。就像中关村信息消费联盟理事长项立刚分析的,对于中国急需的高端芯片,美国会全力压制;等中国快要实现突破、占据一定市场份额时,就放开低端产品进行市场倾销。可这次H20的放行,显然找错了时机——中国不仅有了替代选择,更看清了美国维持技术霸权的真实目的:用“低性能+强生态”的组合,延续对中国AI产业的上游掌控,让中国始终无法摆脱其技术闭环。这场博弈的背后,还有美国内部的激烈分歧。特朗普顶着国会山的一片反对声开绿灯,众议院外交事务委员会直接召开听证会炮轰,前副国家安全顾问马特·波廷格直言,这一决定会“极大助推中国军事现代化进程”,损害美国在AI竞赛中的优势。而白宫方面则极力辩护,称H20并非最先进芯片,且出口总量被限制在美国客户采购量的50%以内,试图在商业利益与国家安全之间找平衡。可特朗普自己的一句话道破了真相:“中国想要它们,我们将从这些芯片销售中获得25%的收入,事儿就是这么回事儿。”中国企业的拒绝,本质上是对这种不平等博弈的主动破局。一方面,头部科技企业早已通过多种渠道获得了比H20更先进的芯片,没必要花高价买性能缩水的产品。另一方面,中小企也更倾向于选择国产芯片,规避供货不稳定和数据安全风险。就连英伟达CEO黄仁勋也坦言,不确定中国是否会接受这类芯片,而白宫人工智能负责人戴维·萨克斯更是直接透露,中方拒绝H20的核心原因,是想要实现半导体独立。如今的芯片战场,早已不是美国单方面掌控话语权。H20的遇冷,印证了一个道理:技术封锁倒逼出来的自主创新,远比任何“有限开放”都更有力量。中国企业正在加速补全生态短板,寒武纪已募资近40亿元用于高端芯片研发,华为也在持续优化昇腾生态,力求降低对CUDA的依赖。美国想靠“残次货+分成”的套路维持霸权,显然已经行不通了。这场博弈远未结束,英伟达已在为中国市场开发新型B30芯片,试图用更低的价格和“合规”优势卷土重来。但可以肯定的是,中国走自主可控之路的决心不会动摇。特朗普的汉堡或许只是惊掉一时,而美国赖以维持科技霸权的固有认知,恐怕要被彻底颠覆了——当中国不再需要“施舍式”的技术开放,这场博弈的规则,就该由我们来定了。
华人团队实现AI自动寻优,矩阵乘法核心首超CUDA闭源库
“矩阵乘法是英伟达 CUDA 生态最核心的护城河之一。而我们打造的 CUDA-L2 在大规模、系统性的评测中,超越英伟达针对该核心算子的闭源优化方案。我们不仅实现了超越,而且将方法开源,这对于打破技术壁垒具有标志性意义。...
DeepReinforce突破:AI生成超越英伟达官方性能的CUDA核心代码
研究团队开发了一个名为CUDA-L2的系统,这个系统结合了大型语言模型和强化学习技术。可以把它理解为一个会编程的AI厨师,它不仅懂得基本的"烹饪技巧"(编程知识),还能通过不断尝试和改进来发现更好的"菜谱"(优化策略)。...

Anthropic打响「去CUDA」第一枪!210亿美元豪购谷歌100万块TPU
这意味着,Anthropic自有超算将不再依赖CUDA生态,不再被云厂商「算力税」抽成,将算力主权握在手中。有网友表示,这显然是一件大事。谷歌现在大力推行商用芯片战略,这将在未来催生一个基于TPU构建的生态系统。毕竟,谷歌已经...
算力之战白热化:谷歌开源策略+Meta生态倒戈,欲打破英伟达CUDA生态垄断
据报道,谷歌(GOOGL.US)正设法削弱英伟达(NVDA.US)凭借CUDA软件平台建立起来的优势,并获得了Meta(META.US)的一定支持。有知情人士称,这家搜索巨头正努力让其自己的AI芯片TPU更顺滑地运行人工智能框架PyTorch。值得注意的是,...



NVIDIA发布CUDA Tile:20年来最大平台升级,让AI开发更轻松
NVIDIA正式发布CUDA13.1,并推出过去二十年来幅度最大的一次更新—CUDATile编程模型。这项新功能被视为CUDA平台的重大里程碑,旨在让AI开发过程变得更简单、更高效,尤其是面向最新的Blackwell架构GPU。与传统CUDA需要程序员...




成本0.3美元,耗时26分钟!CudaForge:颠覆性低成本CUDA优化框架
CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。这推动人们去探索如何利用 LLM 来编写优化 CUDA kernel。...


CUDA真是NVIDIA绝对牢不可破的生态吗?
CUDA真是NVIDIA绝对牢不可破的生态吗?未来不会再有对手了吗?所有的科学计算都只能使用n卡?CUDA 作为 NVIDIA 打造的计算生态核心,凭借十余年的积累构建了难以撼动的行业优势,成为科学计算、AI 训练等高性能场景的主流选择...
黄仁勋游说失败!特朗普禁售+中国禁令,曙光超节点接盘CUDA生态黄仁勋忙活
黄仁勋游说失败!特朗普禁售+中国禁令,曙光超节点接盘CUDA生态黄仁勋忙活半天,反复游说特朗普政府,想让自家芯片对华出口,结果被美国国务卿鲁比奥这些高官集体反对,特朗普最终拍板,最先进的芯片绝不给中国。本以为低配版还有机会,没想到中国直接釜底抽薪。中国新规明确,国资数据中心必须用国产AI芯片,这一下就粉碎了英伟达重夺中国市场的希望。作为AI新基建项目,曙光640超节点做出回应,较384完成新一轮跃迁。生态层面主打兼容ai主流,包括CUDA,把英伟达多年积累的开发者生态直接接过来了。性能层面,单机柜64卡超高速互联,双scaleX640超节点组成千卡级卡计算单元,全球首个。这波操作太妙了,特朗普这边骚操作,中国这边就用政策铺路,用产品硬刚。曙光作为国家队的代表,出手恰逢其时!
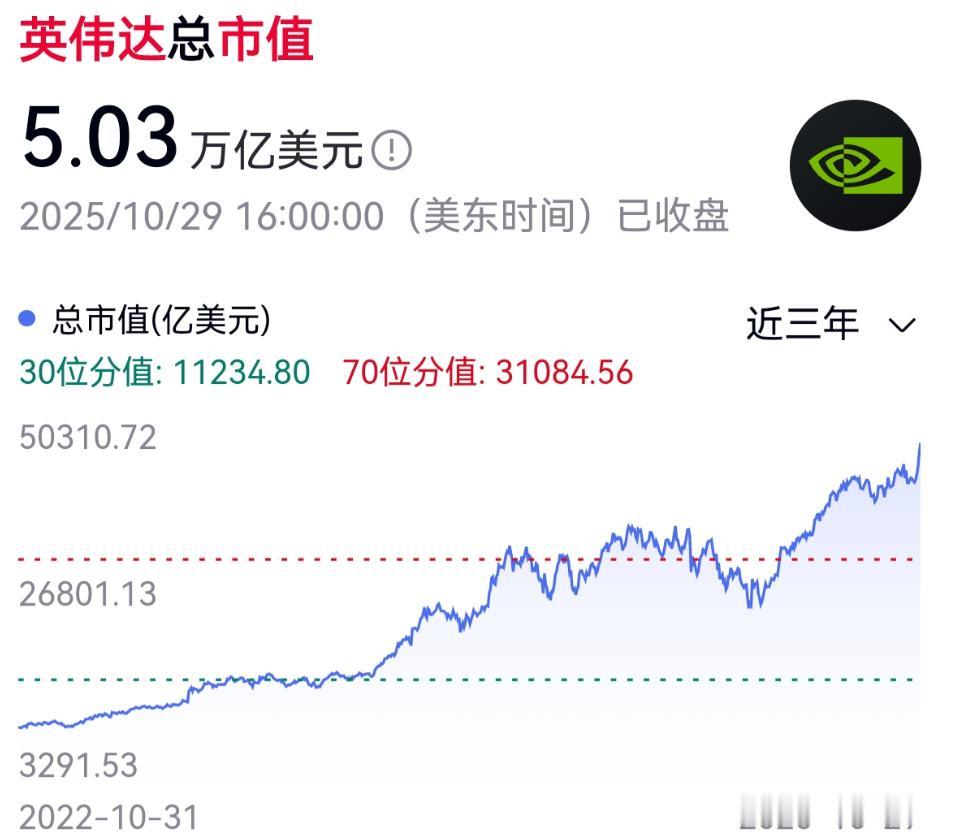
英伟达的市值已经超过50,000亿美元,这是什么概念呢?如果折算成人
英伟达的市值已经超过50,000亿美元,这是什么概念呢?如果折算成人民币,它市值超过35万亿人民币,这个市值差不多相当于整个A股的1/3了,这个确实有点太夸张。另外如果把它当做一个经济体来看待,它将是仅次于美国和中国的第三大经济体,比日本、德国的经济体量还要大。面对这样一个近乎神话的数字,一个无法回避的问题浮现在每个人心头:这到底是价值的真实体现,还是一场史上最华丽的泡沫?要理解英伟达的疯狂,我们得先搞清楚它在当下这个时代扮演的角色。现在全球最火的是什么?是人工智能。而人工智能,尤其是大模型的训练和推理,需要什么?需要算力,海量的算力。这就好比一场席卷全球的数字淘金热,所有人都想挖到属于自己的金矿,而英伟达,就是那个在淘金热中唯一能稳定提供高质量铲子和牛仔裤的“卖铲人”。它的GPU,特别是H100、H200这些顶级芯片,成了各大科技巨头、初创公司甚至国家实验室争抢的硬通货。微软、谷歌、Meta、亚马逊这些云服务巨头,每年都要花费数百亿美元来采购英伟达的芯片,建设自己的AI算力中心。这种需求不是零星的,而是结构性的、饥渴的,它直接构成了英伟达营收和利润暴增的坚实基础。但仅仅把英伟达的成功归功于“卖铲”,未免有些小看了它的护城河。真正让竞争对手望尘莫及的,是它十几年前就埋下的一个“王炸”——CUDA生态系统。说白了,CUDA就是一个软件平台,它让开发者能够轻松地调用英伟达GPU的强大算力。经过十多年的发展,数百万开发者在这个平台上构建了各种各样的AI模型和应用,形成了一个庞大且难以迁移的生态。这就好比所有人都习惯了用iOS系统,你让他换到安卓,不仅需要重新学习,所有买的APP、存的数据都得转移,成本极高。对于AI公司来说,更换GPU供应商,意味着要重写大量代码,重新调试模型,这个时间和金钱成本是难以估量的。所以,即便AMD、英特尔也在奋力追赶,推出了自己的AI芯片,但在CUDA这座高墙面前,它们想要撼动英伟达的地位,难度不亚于重建一个移动互联网生态。然而,任何事物都有两面性。当我们为英伟达的“无敌”而惊叹时,一些危险的信号也在悄然浮现。最直接的质疑,就是它那高到令人咋舌的估值。按照市盈率等传统指标来衡量,英伟达的股价已经透支了未来很多年的增长预期。市场对它的定价,已经不是基于它现在赚了多少钱,而是基于它未来能赚多少钱,这个未来,被描绘得无比光明。这种预期驱动的上涨,本身就是泡沫的温床。一旦未来的增长不及预期,哪怕只是稍微放缓,股价都可能面临剧烈的回调。这就好像一辆时速300公里的跑车,动力强劲,但路面上一颗小石子,都可能引发严重的后果。更深层次的担忧,来自于对AI热潮本身的质疑。现在,全世界都在为AI疯狂投入,但一个根本性的问题还没有完全解决:这么巨大的投入,究竟能否带来相匹配的回报?除了少数几个成功的应用,大部分AI项目仍处于“烧钱”阶段。如果未来一两年,各大公司发现AI的变现能力远不如预期,开始削减相关预算,那么对算力的需求也必然会降温。到那时,英伟达这位“卖铲人”的生意,恐怕就没那么好做了。这种对单一技术浪潮的极度依赖,让英伟达的根基看起来虽然庞大,却也有些脆弱。这让人不禁想起了2000年的互联网泡沫。当时,无数带着“.com”的公司股价一飞冲天,人们相信互联网将改变一切。事后来看,互联网确实改变了一切,但当时绝大多数公司都成了炮灰。那么,英伟达会是那个活下来的亚马逊、谷歌,还是那个被时代遗忘的Pets.com呢?一个关键的区别在于,英伟达拥有真实且巨额的利润,这是当年那些泡沫公司所不具备的。它不是在画饼充饥,而是在真实地享受着技术革命带来的红利。但反过来看,当年的思科,也是靠卖路由器赚得盆满钵满,同样拥有强大的护城河,不也在泡沫破裂后股价跌去了九成以上,十几年都没能重回巅峰吗?历史的镜子,总是能照出当下的影子。所以,英伟达的市值究竟是实是虚,这个问题可能没有一个简单的非黑即白的答案。它更像一个复杂的函数,变量包含了技术的迭代速度、商业模式的变现能力、竞争对手的追赶步伐,甚至全球地缘政治的走向。它既反映了人工智能革命带来的巨大机遇,也浓缩了资本市场在狂热情绪下的非理性预期。它是一家伟大的公司,这一点毋庸置疑,但它的股价,承载的或许已经不仅仅是公司本身的价值,更是整个世界对未来的所有想象和赌注。那么,你认为,我们是处在一个伟大时代的开端,还是又一次站在了历史性泡沫的顶点呢?



CUDA内核之神、全球最强GPU程序员?OpenAI的这位幕后大神是谁
起因是 X 上的一则热门帖子,其中提到 OpenAI 仅凭一位工程师编写的关键 CUDA Kernel,就支撑起每日数万亿次的庞大计算量。评论区纷纷猜测,这位大神便是 OpenAI 的资深工程师 Scott Gray。在 OpenAI 的官方介绍中也明确提到,...
