DC娱乐网
爱生活爱珂珂的文章
傅里叶级数和笛卡尔坐标系有什么共同点?其实它们几乎是同一个概念的两种表现形式。核
2025-10-03 08:58
傅里叶级数和笛卡尔坐标系有什么共同点?其实它们几乎是同一个概念的两种表现形式。核
[人人能懂] 从并行思考、结构化学习到认知解密想知道AI如何像开“诸葛亮会”一样
2025-10-03 08:58
[人人能懂] 从并行思考、结构化学习到认知解密想知道AI如何像开“诸葛亮会”一样
[LG]《Per-example gradients: a new fronti
2025-10-03 06:58
[LG]《Per-example gradients: a new fronti
[CL]《Verbalized Sampling: How to Mitigat
2025-10-03 06:58
[CL]《Verbalized Sampling: How to Mitigat
[LG]《Why Can't Transformers Learn Multip
2025-10-03 06:58
[LG]《Why Can't Transformers Learn Multip
[LG]《Thoughtbubbles: an Unsupervised Met
2025-10-03 06:58
[LG]《Thoughtbubbles: an Unsupervised Met
[LG]《Rethinking Thinking Tokens: LLMs as
2025-10-03 05:58
[LG]《Rethinking Thinking Tokens: LLMs as
早![太阳] 早安
2025-10-03 05:58
早![太阳] 早安
《“The G in GPU is for Graphics damnit!”:
2025-10-02 09:58
《“The G in GPU is for Graphics damnit!”:
Thinking Machines 推出 Tinker——灵活强大的语言模型微调
2025-10-02 08:59
Thinking Machines 推出 Tinker——灵活强大的语言模型微调
[人人能懂] 从本质创造、跨界通感到无知之智本期节目,我们将潜入AI的“思想厨房
2025-10-02 08:59
[人人能懂] 从本质创造、跨界通感到无知之智本期节目,我们将潜入AI的“思想厨房
[CL]《TruthRL: Incentivizing Truthful LLM
2025-10-02 06:58
[CL]《TruthRL: Incentivizing Truthful LLM
[LG]《Towards Verified Code Reasoning by
2025-10-02 06:59
[LG]《Towards Verified Code Reasoning by
[LG]《Learning to See Before Seeing: Demy
2025-10-02 06:58
[LG]《Learning to See Before Seeing: Demy
[CL]《Regression Language Models for Code
2025-10-02 05:58
[CL]《Regression Language Models for Code
[CL]《Limited Preference Data? Learning B
2025-10-02 05:58
[CL]《Limited Preference Data? Learning B
早![太阳] 早安
2025-10-02 05:58
早![太阳] 早安
晚安~ [月亮] 晚安
2025-10-02 00:58
晚安~ [月亮] 晚安
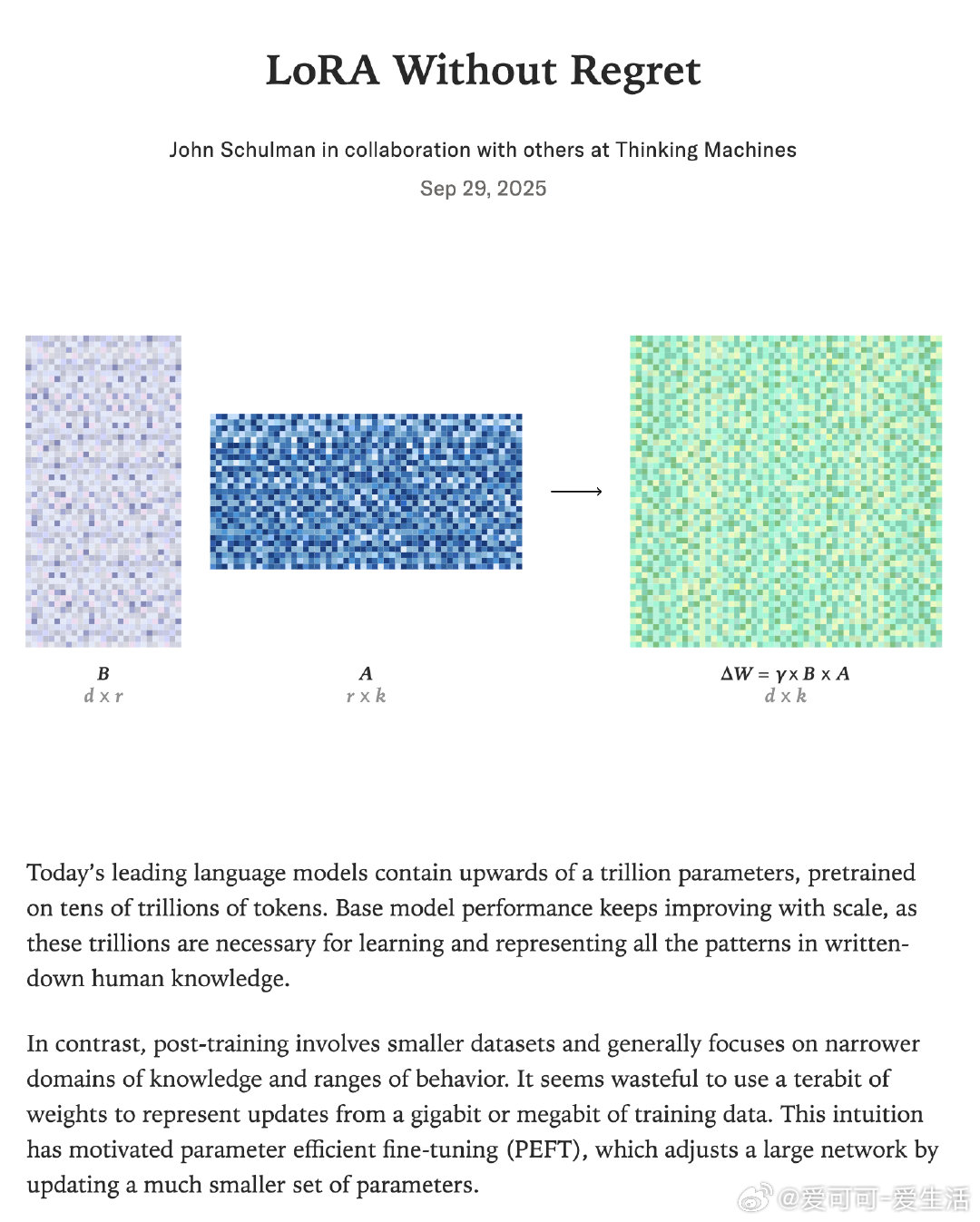
LoRA Without Regret:高效微调大模型的新时代当今顶尖语言模型拥
2025-10-01 10:58
LoRA Without Regret:高效微调大模型的新时代当今顶尖语言模型拥
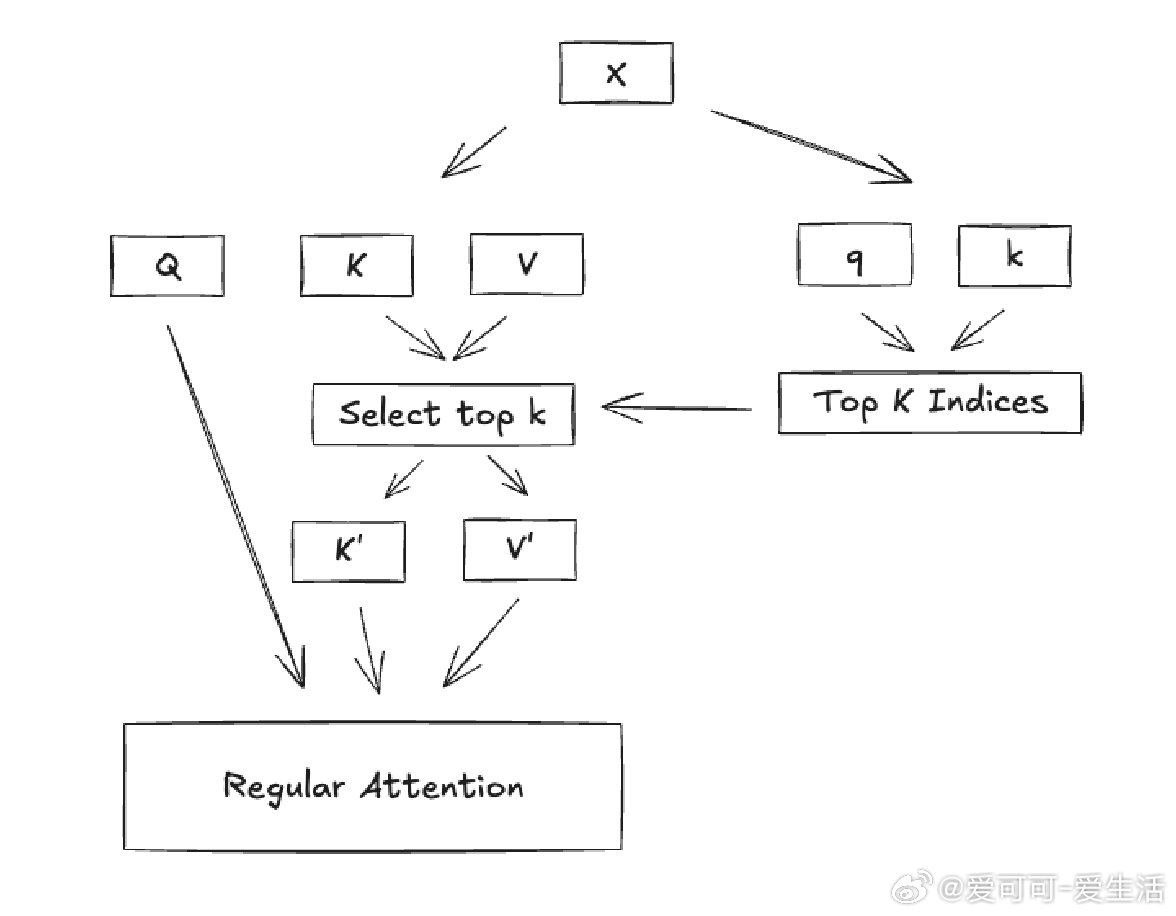
Awni Hannun分享了DeepSeek v3.2中稀疏注意力机制的简洁设计
2025-10-01 10:58
Awni Hannun分享了DeepSeek v3.2中稀疏注意力机制的简洁设计
第一页
下一页
作者信息
爱生活爱珂珂
感谢大家的关注
分类: 科技
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量

![[人人能懂] 从并行思考、结构化学习到认知解密想知道AI如何像开“诸葛亮会”一样](http://dayu-img.uc.cn/columbus/img/oc/1002/149ab563f8e118bbae9a584b8e409ad6.jpg)
![[LG]《Per-example gradients: a new fronti](http://dayu-img.uc.cn/columbus/img/oc/1002/0811d9c4c71f9a8384aa523d861eb406.jpg)
![[CL]《Verbalized Sampling: How to Mitigat](http://dayu-img.uc.cn/columbus/img/oc/1002/d9325a95edfd5569ad988ca1c4af02e1.jpg)
![[LG]《Why Can't Transformers Learn Multip](http://dayu-img.uc.cn/columbus/img/oc/1002/020899494750b49b26c3242e13b82f28.jpg)
![[LG]《Thoughtbubbles: an Unsupervised Met](http://dayu-img.uc.cn/columbus/img/oc/1002/096f203729424466074867b3dbbc608a.jpg)
![[LG]《Rethinking Thinking Tokens: LLMs as](http://dayu-img.uc.cn/columbus/img/oc/1002/3753f5ce012fc8b481fb2b7f4890117b.jpg)
![早![太阳] 早安 ](http://dayu-img.uc.cn/columbus/img/oc/1002/1cad1694dc8852461feb9be0342e25c3.jpg)

![[人人能懂] 从本质创造、跨界通感到无知之智本期节目,我们将潜入AI的“思想厨房](http://dayu-img.uc.cn/columbus/img/oc/1002/221cf6b5541c1e2baac02b2ec91e5769.jpg)
![[CL]《TruthRL: Incentivizing Truthful LLM](http://dayu-img.uc.cn/columbus/img/oc/1002/9466c088960ce51d76eb69aa392106ae.jpg)
![[LG]《Towards Verified Code Reasoning by](http://dayu-img.uc.cn/columbus/img/oc/1002/e9fff643408717015ef7cec8a11c3950.jpg)
![[LG]《Learning to See Before Seeing: Demy](http://dayu-img.uc.cn/columbus/img/oc/1002/d21e346a42e0ad847a0f026c7f1c22be.jpg)
![[CL]《Regression Language Models for Code](http://dayu-img.uc.cn/columbus/img/oc/1002/5ff8f601e14dabd6619985edbe537107.jpg)
![[CL]《Limited Preference Data? Learning B](http://dayu-img.uc.cn/columbus/img/oc/1002/f2d3287ccce917501ac0484ea4ade6b7.jpg)
![早![太阳] 早安 ](http://dayu-img.uc.cn/columbus/img/oc/1002/70d7e46425d6dad3fb262902a34c0f03.jpg)
![晚安~ [月亮] 晚安 ](http://dayu-img.uc.cn/columbus/img/oc/1002/ced948e5a7e30de149fab9b3151b28ff.jpg)