DC娱乐网
孤鸿泽的文章
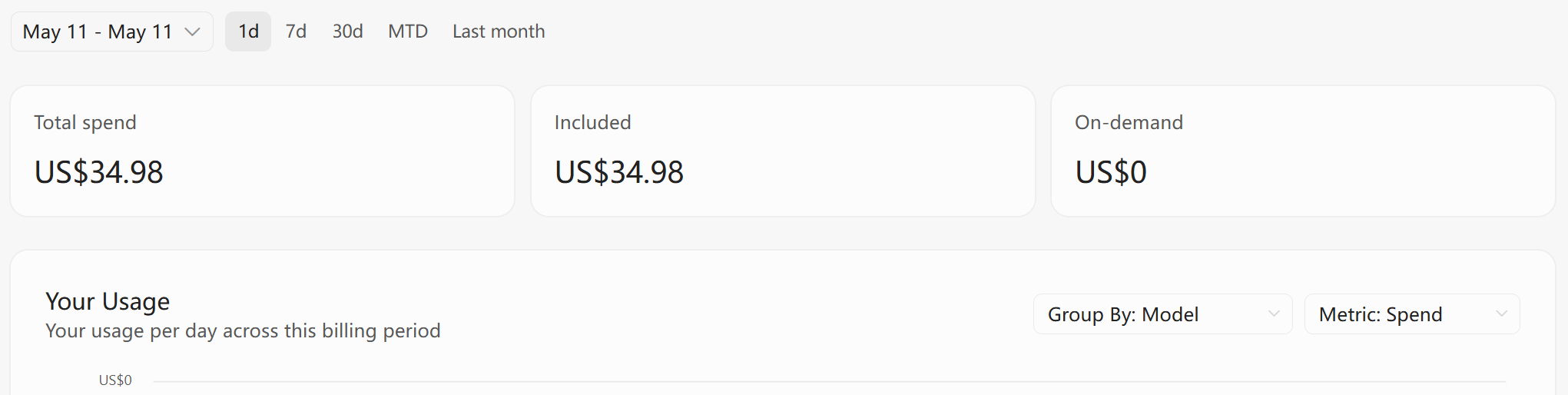
大型项目的规划和初始生成可以用claude4.7,效率与完成度确实高。现在cla
2026-05-12 12:35
大型项目的规划和初始生成可以用claude4.7,效率与完成度确实高。现在cla
anthropic的claude opus 4.7确实强到离谱。早上我用二十分钟
2026-05-11 15:36
anthropic的claude opus 4.7确实强到离谱。早上我用二十分钟
稍微加点光影效果,现在本地生图完全可以作定妆和分镜了,后期再一调色,难分真假。
2026-05-10 23:37
稍微加点光影效果,现在本地生图完全可以作定妆和分镜了,后期再一调色,难分真假。
我在本地生成的图片,感觉与在线大模型没有太大差别吧。
2026-05-10 21:30
我在本地生成的图片,感觉与在线大模型没有太大差别吧。
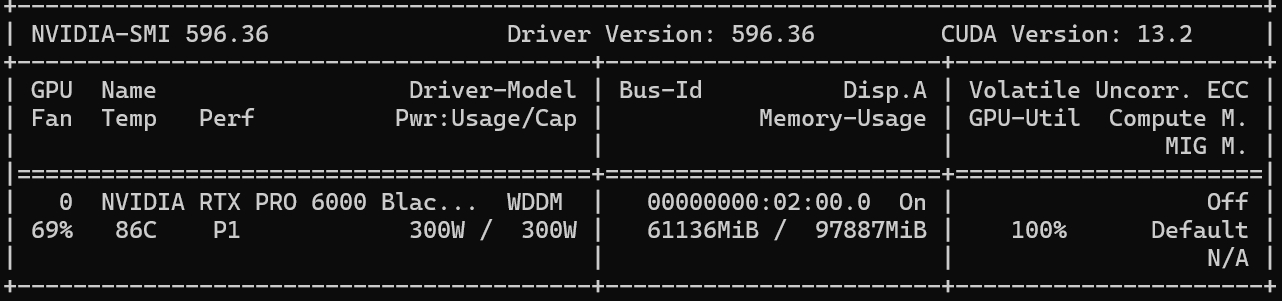
rtxpro6000有三个版本,服务器版没有散热,工作站版是双涡轮,Max-Q版
2026-05-10 15:37
rtxpro6000有三个版本,服务器版没有散热,工作站版是双涡轮,Max-Q版
随着AI智能化的加速,提示词的能力差异会导致社会分层。表达能力的强的人会获得指数
2026-05-10 14:35
随着AI智能化的加速,提示词的能力差异会导致社会分层。表达能力的强的人会获得指数
有很多技术不能做培训,不是几个东西不能教,而是很多不能教。你要是入门了,自己能过
2026-05-10 14:35
有很多技术不能做培训,不是几个东西不能教,而是很多不能教。你要是入门了,自己能过
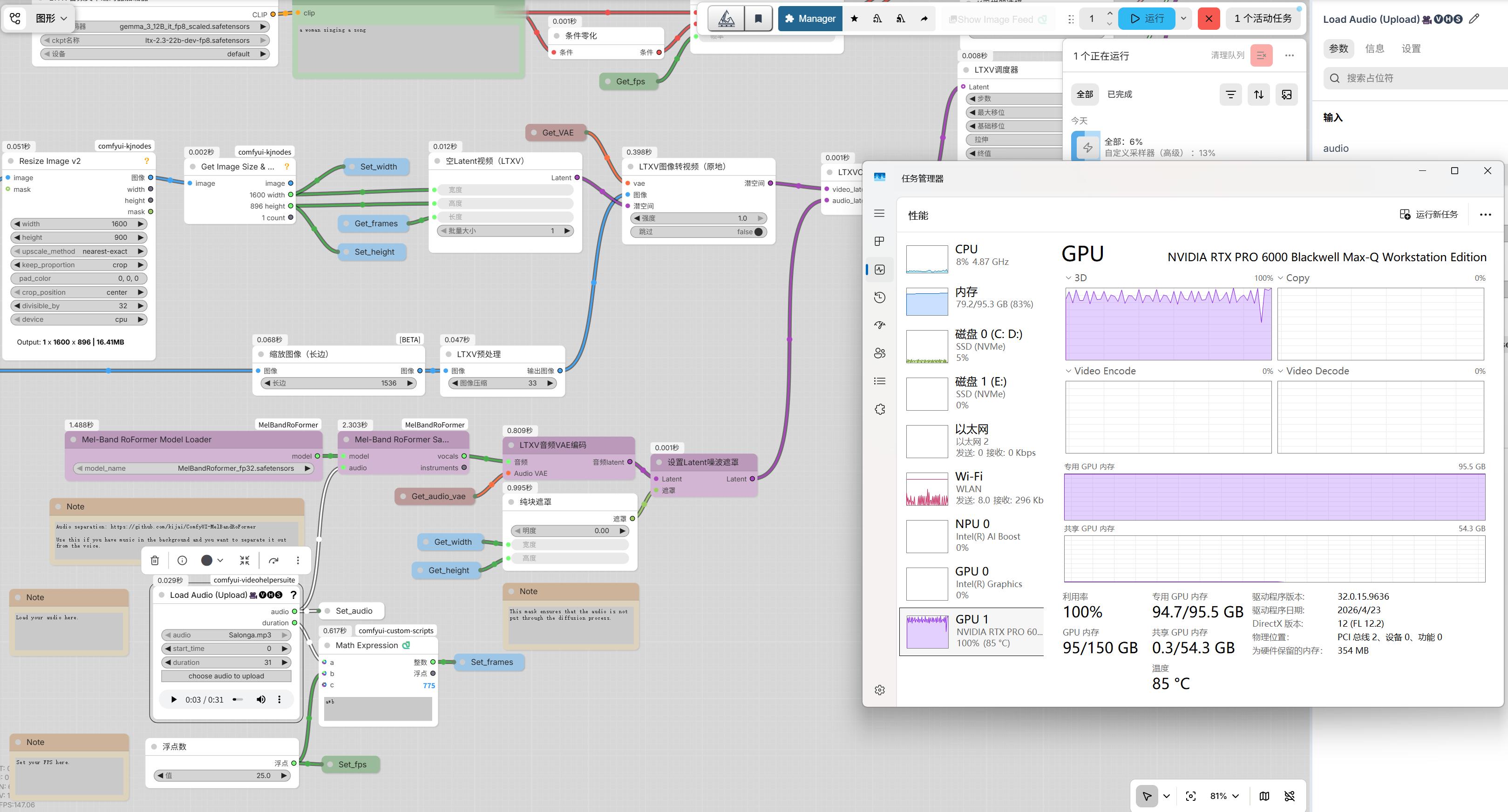
视频合成的时候所有资源全部拉满,一点余量都没了。
2026-05-09 20:36
视频合成的时候所有资源全部拉满,一点余量都没了。
我现在用qwen3.6 27b Q8 上下文256k KV不做量化的全资源模式做
2026-05-09 11:32
我现在用qwen3.6 27b Q8 上下文256k KV不做量化的全资源模式做
xAI每月烧钱约10亿美元,2025年全年亏损约130亿美元,直接把SpaceX
2026-05-09 11:30
xAI每月烧钱约10亿美元,2025年全年亏损约130亿美元,直接把SpaceX
qwen3.6 27b的出现是一个本地部署的拐点,就像openai推出chatg
2026-05-09 10:35
qwen3.6 27b的出现是一个本地部署的拐点,就像openai推出chatg
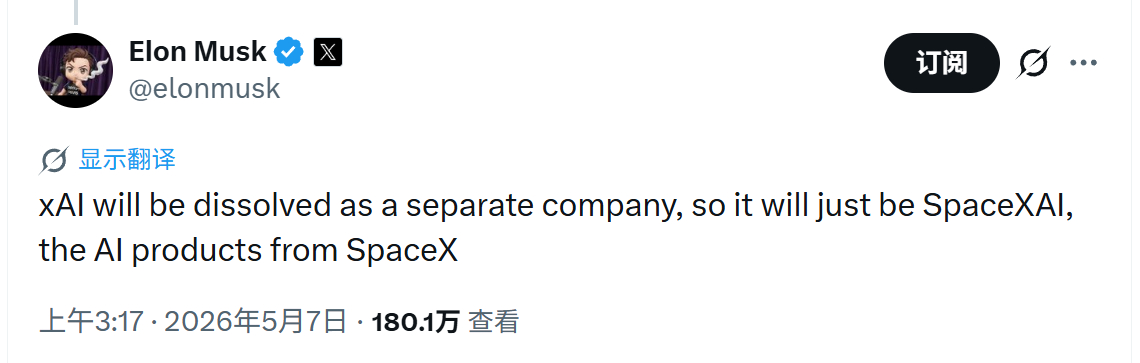
马斯克宣布xai解散了,这应该是美国AI巨头第一个承认通用AI失败进行并构转型的
2026-05-09 10:33
马斯克宣布xai解散了,这应该是美国AI巨头第一个承认通用AI失败进行并构转型的
晚上做的酱大骨和肉汤白菜粉条,我这一天可忙了…
2026-05-08 20:30
晚上做的酱大骨和肉汤白菜粉条,我这一天可忙了…
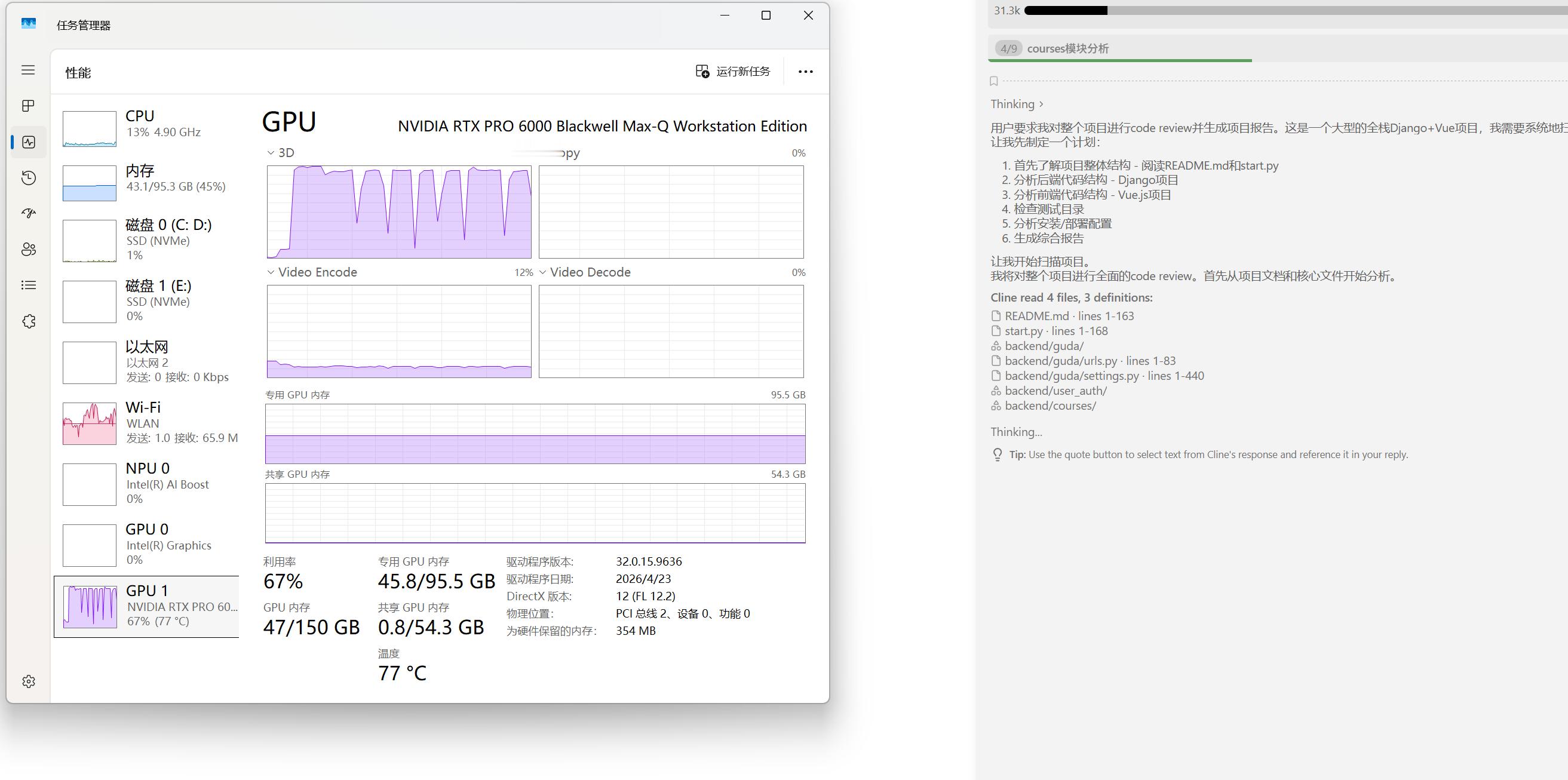
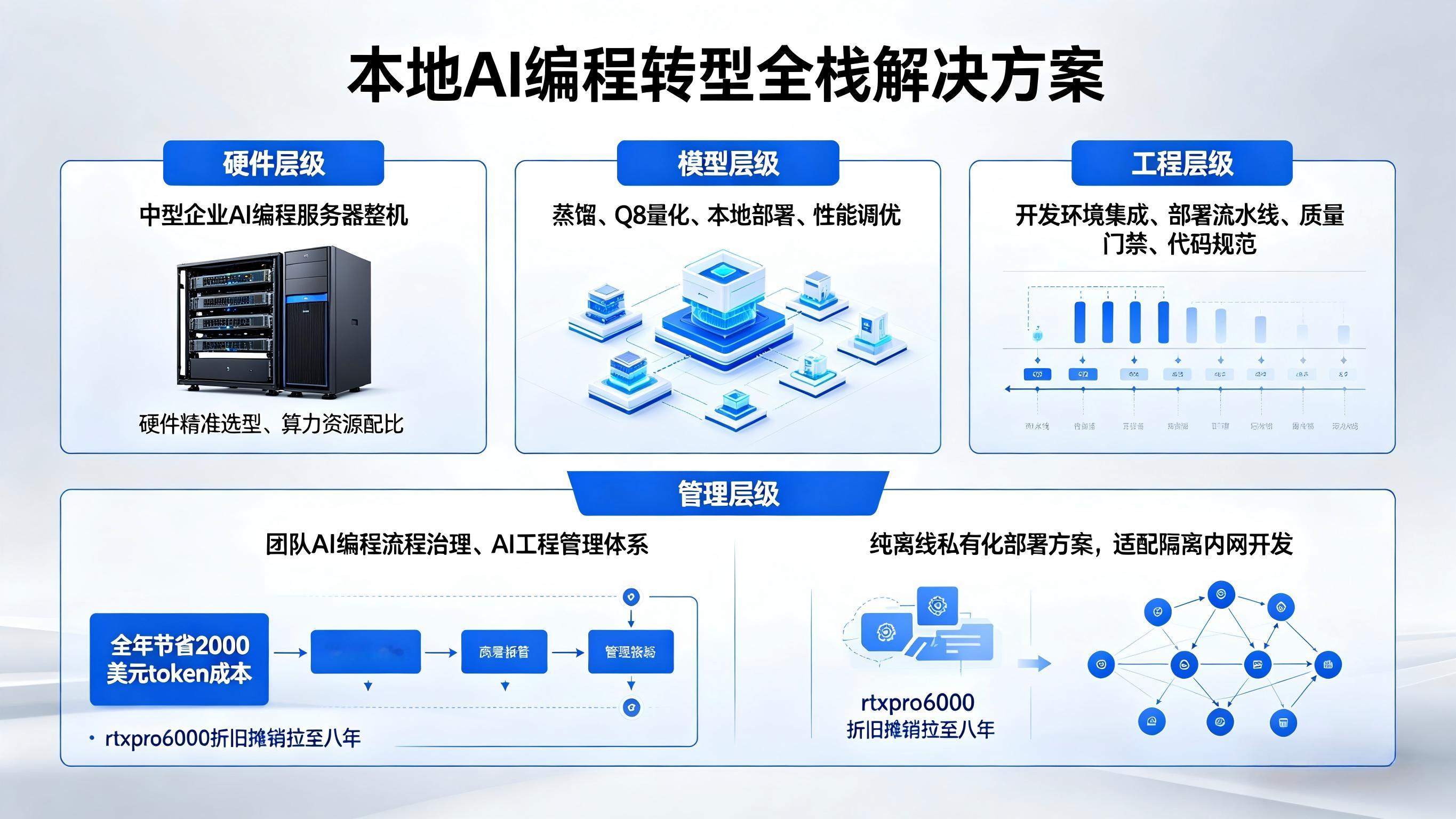
我为什么一反常态地买了rtxpro6000,一是业务场景非常清晰,特别是qwen
2026-05-08 17:34
我为什么一反常态地买了rtxpro6000,一是业务场景非常清晰,特别是qwen
云端的上下文理解力和存储确实强,但这是基于你的支出成正比的,你再想想这划算吗?除
2026-05-08 17:33
云端的上下文理解力和存储确实强,但这是基于你的支出成正比的,你再想想这划算吗?除
我在去年 token最便宜的时候使用cursor完成了对guda.cn的底层架构
2026-05-08 17:34
我在去年 token最便宜的时候使用cursor完成了对guda.cn的底层架构
换个思路,将来大模型公司可以把一部分算力下放到本地,根据本地硬件所能自我消化的能
2026-05-08 15:38
换个思路,将来大模型公司可以把一部分算力下放到本地,根据本地硬件所能自我消化的能
免费的AI都在“带答不理”化,因为算力是昂贵且有限的,不可能满足免费用户正常长下
2026-05-08 13:33
免费的AI都在“带答不理”化,因为算力是昂贵且有限的,不可能满足免费用户正常长下
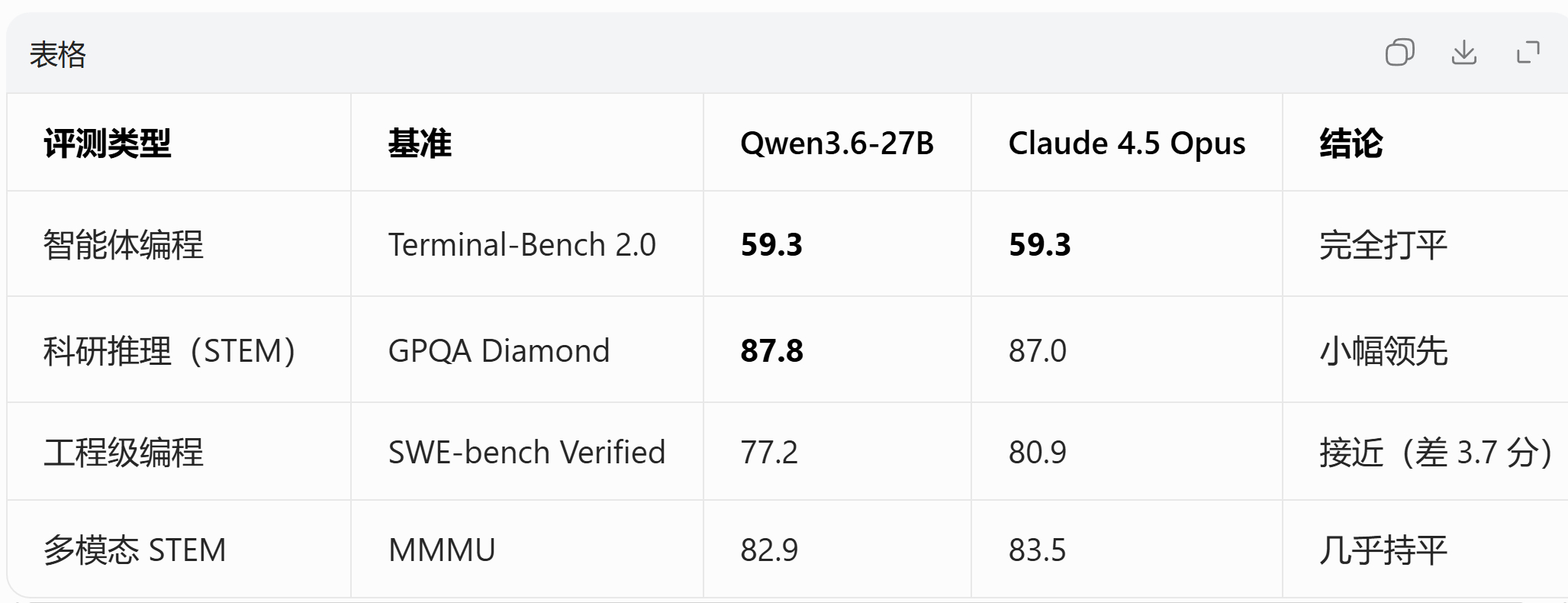
qwen3.6 确实强,已经达到上一代claude 4.5的水平,我又使用了一个
2026-05-08 12:32
qwen3.6 确实强,已经达到上一代claude 4.5的水平,我又使用了一个
闲鱼的问题解决了,经过我一天的折腾把内存点亮了。原因是二手内存因为插拔等原因以及
2026-05-08 00:16
闲鱼的问题解决了,经过我一天的折腾把内存点亮了。原因是二手内存因为插拔等原因以及
第一页
下一页
作者信息
孤鸿泽
感谢大家的关注
分类: 财经
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量