
英文题目:Integrated Task and Motion Planner Using Hierarchical Reinforcement Learning for Multi-Robot Collaboration
中文题目:基于分层强化学习的多机器人协作任务—运动一体化规划方法
作者:Junnan Zhang, Chaoxu Mu, Ke Wang, Lei Ren
作者单位:天津大学电气与信息工程学院;北京航空航天大学自动化科学与电气工程学院
期刊:IEEE Transactions on Automation Science and Engineering
发表时间:2025年12月5日
引文格式:Zhang J., Mu C., Wang K., and Ren L., Integrated Task and Motion Planner Using Hierarchical Reinforcement Learning for Multi-Robot Collaboration, IEEE Transactions on Automation Science and Engineering, vol. 23, pp. 743–754, 2026.
01 全文速览
这篇论文讨论的是一个非常典型、也非常工程化的问题:多机器人协作时,任务怎么分?路径怎么走?机器人之间如何避免互相干扰和碰撞?
传统方法往往把任务规划和运动规划拆开处理:先分配任务,再规划路径。这样做逻辑清楚,但问题也很明显——任务分配阶段很难提前充分考虑机器人真实运动中的碰撞风险、空间约束和动态干涉。一旦多个机械臂在同一工作空间内执行长时序、多步骤任务,前面看似合理的任务分配,到了执行层面可能就会变成拥堵、碰撞或重复规划。
本文提出的 ITMP,Integrated Task and Motion Planner,核心思想是:
不要把任务规划和运动规划割裂开,而是用分层强化学习把二者放进一个统一框架中协同优化。
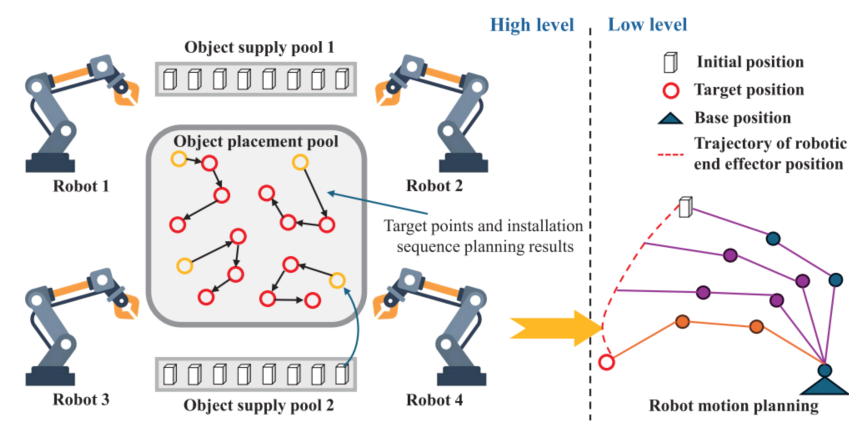
图1: ITMP整体任务—运动规划示意图。
✅ 亮点1:提出任务规划与运动规划一体化框架,缓解多机器人协作中的规划耦合问题。
✅ 亮点2:高层采用共享GAT与分布式策略网络,实现多机器人任务分配与执行顺序决策。
✅ 亮点3:低层采用去中心化运动规划策略,输出连续控制动作,实现末端位姿控制与动态避碰。
✅ 亮点4:通过专家数据稳定并行训练,并在真实物体摆放与发动机液压柱装配平台上完成验证。
02 研究内容
🎯 2.1 研究问题:为什么任务规划和运动规划不能简单分开?
在工业生产线中,多机器人常被用于装配、搬运、抓取和放置等任务。以多个机械臂协同摆放工件为例,高层需要决定哪个机器人拿哪个物体、先放哪个、放到哪里;低层则要决定机械臂关节怎么动、末端如何到达目标、如何避开其他机器人和障碍物。
如果采用传统串行方案:
先用任务规划器分配任务,再用运动规划器生成路径。问题是,高层分配任务时往往看不到低层运动执行中的真实约束。结果可能出现:任务分配看似最短,但机械臂运动时互相遮挡;路径规划单独可行,但多个机器人同时执行时发生冲突;一个机器人完成了局部最优任务,却拖慢整体协作效率。
本文正是针对这一痛点提出ITMP框架,使高层和低层策略可以在同一个强化学习框架中并行训练、相互耦合、协同优化。
🧠 2.2 整体框架:高层分任务,低层管运动
ITMP采用典型的分层强化学习结构,由两个层次组成:
第一层是 High-Level Policy,高层策略。它负责战略层面的任务规划,包括为每个机器人分配目标任务,并确定任务执行顺序。作者将机器人位置和任务点位置建模为图结构,利用共享图注意力网络 GAT 提取全局任务关系,再通过多个分布式策略网络分别输出各机器人对任务点的选择概率。
第二层是 Low-Level Policy,低层策略。它负责运动规划和连续控制,根据高层给定的目标任务,生成机械臂的连续动作,使机器人末端到达目标位姿,并尽量避免碰撞。

图2:分层强化学习训练框架。上半部分展示高层GAT任务规划,下半部分展示低层LSTM状态编码与运动规划,这是理解本文方法的核心图。
这套设计的价值在于,高层不再只是抽象地分任务,低层也不再只是被动地执行路径。二者在训练过程中产生耦合,使任务分配逐渐学习到运动可行性和碰撞风险。
🔗 2.3 高层策略:用GAT理解多机器人—多任务关系
高层任务规划采用 encoder-decoder 架构。编码器使用共享GAT,解码器由多个独立策略网络组成,每个机器人对应一个策略网络。
论文将机器人和任务点都视为图中的节点,节点特征主要由三维坐标构成。GAT的作用是学习节点之间的关联程度。例如,一个任务点距离某个机器人更近、与其他机器人干涉更小、执行顺序更合理,那么它在注意力机制中可能获得更高权重。
核心注意力系数可表示为:
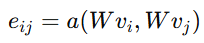
归一化后得到:
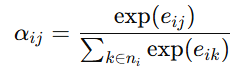
进一步通过多头注意力机制获得节点的新特征表示:
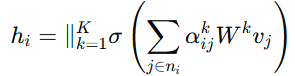
这里的关键不是公式本身,而是它背后的思想:任务分配不再只看距离,而是通过图结构显式建模机器人、任务点和协作关系。
⚙️ 2.4 低层策略:从任务目标到机械臂连续动作
低层运动规划面对的是更复杂的连续控制问题。机械臂下一步动作不仅取决于当前状态,还与历史运动过程有关。因此,作者在低层策略中引入 LSTM状态编码器,将当前状态和历史信息压缩成固定长度表示。
低层观测包括五类信息:
机器人基座位姿、关节角、末端位姿、连杆位置、目标末端位姿。加入当前与历史状态后,状态维度达到107维。随后通过全连接网络输出动作分布参数,并采样得到6维连续控制命令。
低层奖励函数综合考虑成功到达、碰撞惩罚、超时惩罚、距离引导和姿态对齐等因素。这个设计比较符合真实机械臂控制任务,因为工业操作不仅要求到达,还要求安全、准确、姿态合理。
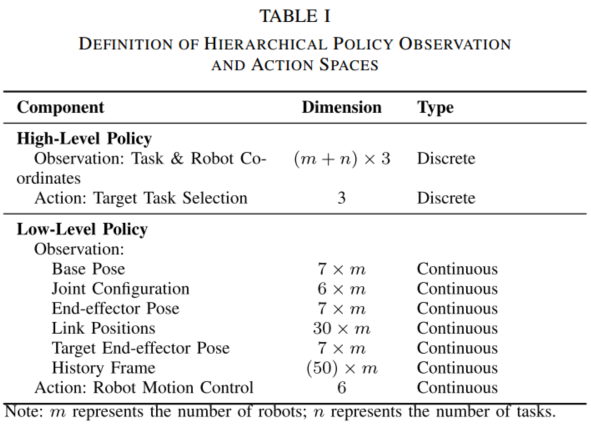
图3:高层与低层策略的观测空间和动作空间定义。
🚀 2.5 稳定训练:为什么需要专家数据?
分层强化学习看似自然,但训练并不容易。原因在于高层和低层是耦合的:高层输出目标任务,低层根据目标任务生成连续动作。如果低层策略一开始随机探索,高层看到的状态转移就会非常不稳定,训练容易发散。
论文用一个转移概率关系解释了这种不稳定性。高层状态转移不仅取决于高层动作,还依赖低层策略输出:
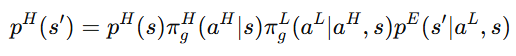
也就是说,低层策略越随机,高层学习到的环境反馈越不稳定。
为了解决这个问题,作者引入由 BiRRT 生成的运动专家轨迹,并通过交叉熵损失约束低层策略,使其早期探索更有方向。这一点很关键:论文并不是完全依赖专家示范来替代学习,而是用专家数据稳定低层运动策略,从而让高层任务策略获得更可靠的反馈。

图4:ITMP训练流程伪代码。
📊 2.6 实验结果:ITMP在成功率和碰撞率上优势明显
论文在两类仿真场景中进行验证:
一种是双机器人协作完成10个目标任务;另一种是四机器人协作完成20个目标任务。
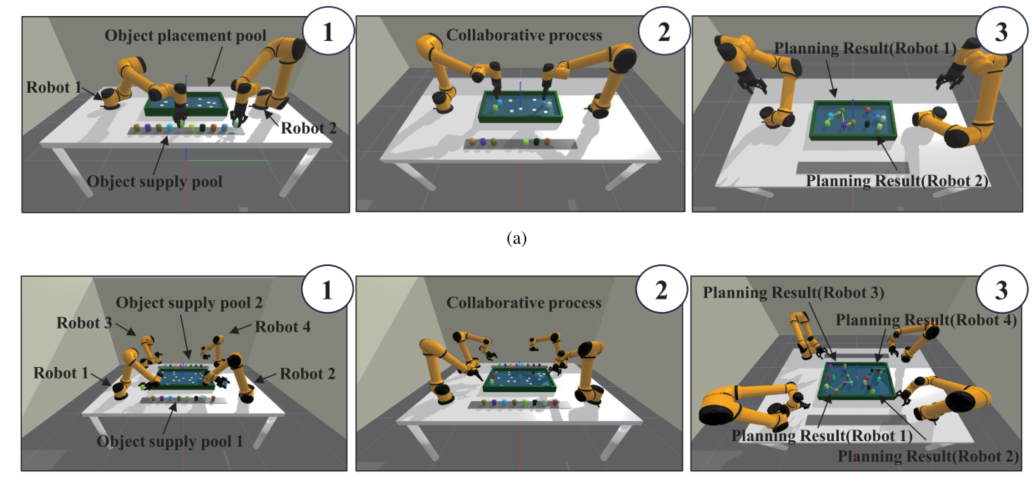
图5:双机器人与四机器人任务场景仿真平台。
在与多种强化学习方法对比时,ITMP表现出更高成功率。根据论文结果,ITMP在双机器人和四机器人测试场景中均取得接近或超过98%的测试成功率,并且训练时间较短。相比之下,MADDPG、MAPPO以及传统TMP分开训练方法的表现明显不稳定,尤其在四机器人场景中下降更明显。

图6:不同强化学习方法的训练时间、测试时间、成功率,以及双机器人和四机器人任务中的回报曲线、成功率曲线。
碰撞率对多机器人协作尤其重要。论文对比了ITMP、TMP-ST和TMP-UOF等方法,ITMP在双机器人和四机器人场景中均获得最低碰撞率。这说明它确实在一定程度上缓解了任务分配与运动避碰之间的耦合冲突。
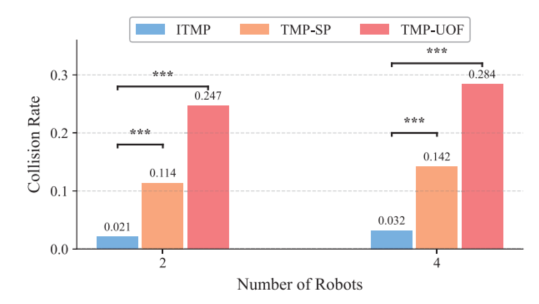
图7:学习型方法碰撞率对比。
🏭 2.7 与传统方法对比:不只是会学,还要算得快
为了进一步验证ITMP相对传统方法的优势,作者将其与OR-Tools和PRM等非学习方法进行组合对比。OR-Tools常用于组合优化任务规划,PRM是典型采样式运动规划方法。
实验结果显示,随着任务数量增加,传统组合方法成功率明显下降,求解时间增加。而ITMP由于通过离线训练获得策略网络,在线求解时间约为 0.15 s,能够满足实际应用中的快速响应需求。


图8:ITMP与非学习方法在不同任务规模下的成功率、求解时间和碰撞率对比。
🤖 2.8 真实平台验证:从仿真到工业装配
论文最后进行了Sim-to-Real实验验证。作者搭建了两个真实任务平台:
一个是通用物体摆放平台;另一个是发动机液压柱装配平台。
真实系统包括两台AUBO i5机械臂、两个电动夹爪、Kinect 2.0全局相机、两台D435i末端相机以及ROS通信框架。Kinect负责全局工作空间监测和初始目标定位,D435i负责末端局部视觉、抓取验证和避障辅助。
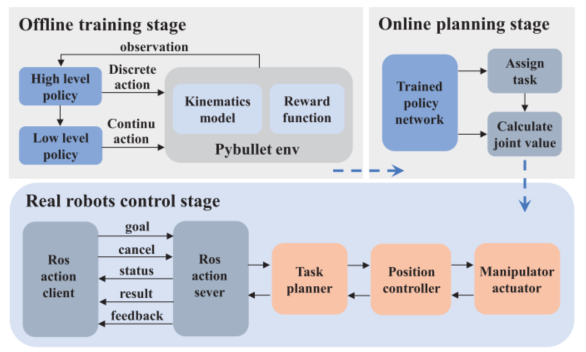
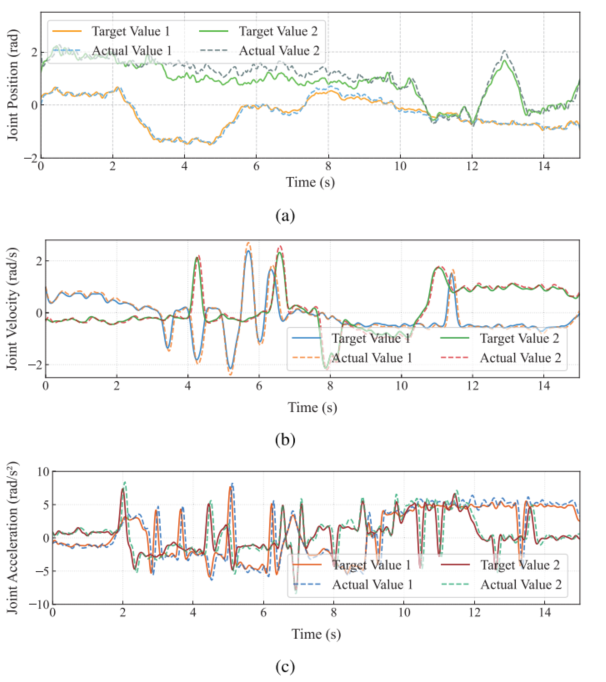
图9:Sim-to-Real流程与真实机器人关节位置、速度、加速度跟踪效果。
该图适合说明作者并非只做算法仿真,而是考虑了真实机器人控制误差。
真实实验中,ITMP在物体摆放任务中成功率达到 96.0%,在发动机液压柱装配任务中成功率达到 94.0%。液压柱装配任务虽然目标排列相对规则,但空间结构狭窄,对避碰精度要求更高,因此94%的成功率仍具有较强工程意义。
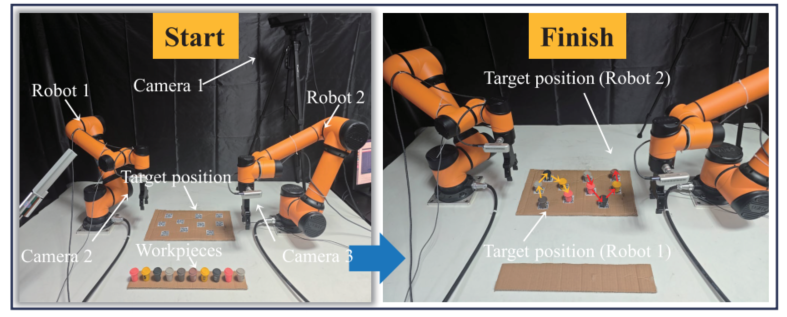
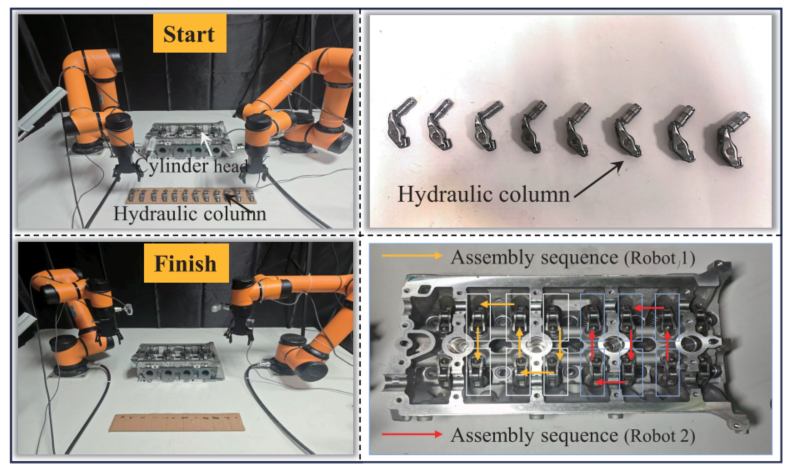
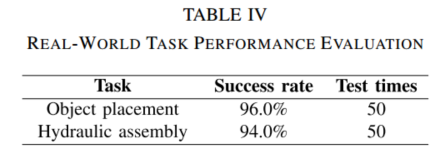
图10:真实物体摆放任务、发动机液压柱装配任务快照与成功率统计。
03 创新点
🧩 3.1 将任务规划与运动规划放入统一学习框架
本文最重要的创新不在于单独提出一个任务分配算法,也不在于单独提出一个运动规划器,而是将二者统一到分层强化学习框架中。高层策略负责做什么、谁来做、按什么顺序做,低层策略负责怎么动、如何避碰、如何到达目标。这种结构更符合多机器人长时序协作任务的真实需求。
🧠 3.2 利用GAT建模多机器人任务分配关系
相比简单基于距离或启发式规则的任务分配,GAT可以在图结构上建模机器人与任务点之间的关系。对于多机器人、多任务、多目标位置不断变化的场景,这种图结构表达更具有适应性,也更容易扩展到不同数量的任务实例。
⚙️ 3.3 通过动作解耦处理混合动作空间
多机器人协作任务同时包含离散决策和连续控制:任务分配是离散动作,机械臂运动是连续动作。本文通过高低层解耦,将混合动作空间拆分为高层离散动作和低层连续动作,使强化学习问题更容易训练,也更符合决策—控制的层级结构。
🛡️ 3.4 专家数据不是替代学习,而是稳定训练
本文引入BiRRT专家轨迹,并不是简单模仿专家动作,而是减少低层策略早期的无效探索,缓解高低层并行训练时的非平稳性。这种处理比较务实,也更接近工程中学习算法 + 传统规划经验融合的路线。
04 总结与展望
这篇论文的核心价值在于,它抓住了多机器人协作中的一个真实瓶颈:任务分配不能脱离运动可行性,运动规划也不能脱离全局任务目标。
从机器人控制角度看,ITMP提供了一种比较清晰的分层控制思路:高层完成协作决策,低层完成连续运动控制,中间通过目标任务进行连接。它不是完全抛弃传统规划,而是在强化学习训练中吸收专家数据,使学习策略具备更好的稳定性和执行效率。
当然,本文仍有进一步拓展空间。比如,当前真实实验中的液压柱装配任务目标位置较规则,动态环境复杂度仍有限;多机器人数量进一步增加时,GAT和低层控制策略的泛化能力还需要更大规模验证;在真实工业现场中,夹持失败、工件姿态误差、人员进入工作区等因素也会使任务更加复杂。
🔭 未来研究将聚焦于以下几个方向:
1. 动态任务环境下的在线自适应能力,使机器人能够根据任务变化实时调整分配与运动策略;
2. 更大规模多机器人系统扩展,验证ITMP在更多机器人、更密集工作空间中的稳定性;
3. 复杂工业装配任务推广,从规则摆放扩展到不规则装配、柔性工件操作和物流分拣;
4. 安全约束强化学习融合,进一步降低真实系统中的碰撞、夹持失败和异常动作风险;
5. 任务规划、运动规划与视觉感知闭环融合,让机器人从按目标执行走向感知—决策—控制一体化。
在多机器人协作系统中,未来的主流路线会是传统优化规划 + 学习策略辅助,还是端到端分层智能决策?
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。