浏览器的主要功能总结起来就是一句话:将用户输入的URL转变成可视化的图像。
1.从URL到DOM 树;
2.从DOM树到可视化图像;
这两个过程之间的关系并没有那么明确,我们可以统称这两个过程为页面的渲染;
一、页面渲染过程从输入URL到页面渲染完整的过程可以分为以下几个步骤:

DNS解析:浏览器首先会解析输入的URL中的域名,将其转换为对应的IP地址。这个过程涉及到查询DNS服务器,以获取正确的IP地址。
建立TCP连接:浏览器使用HTTP或HTTPS协议与服务器建立TCP连接。这个过程涉及到三次握手,即客户端向服务器发送一个连接请求,服务器回复确认,最后客户端再次回复确认。
发送HTTP请求:浏览器向服务器发送一个HTTP请求,包括请求方法(GET、POST等)、请求头(User-Agent、Cookie等)和请求体(POST请求时携带的数据)。
服务器处理请求:服务器接收到请求后,会根据请求的内容进行处理。这可能涉及到动态生成页面、查询数据库、读取文件等操作。
接收响应:服务器处理完请求后,会生成一个HTTP响应,包括状态码、响应头和响应体。响应头中包含了很多关于响应的信息,如内容类型、缓存控制等。
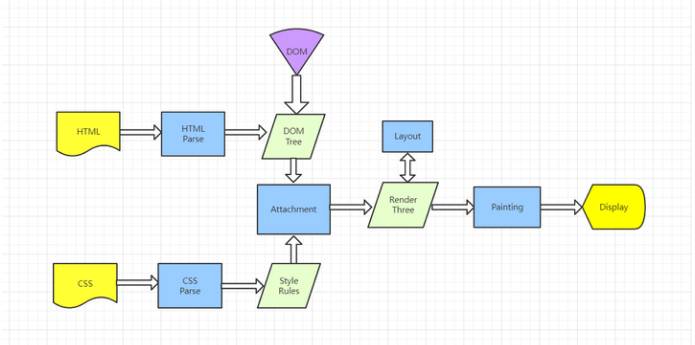
页面渲染:浏览器接收到响应后,会开始解析HTML文档,并构建DOM树。然后,浏览器会解析CSS样式表,计算出每个元素的样式。接下来,浏览器会根据DOM树和样式信息,构建渲染树。最后,浏览器使用渲染树将页面内容绘制到屏幕上。
下载资源:在页面渲染的过程中,浏览器会解析HTML文档中的链接,如CSS文件、JavaScript文件、图片等,并发送请求下载这些资源。
执行JavaScript:当浏览器下载并解析完所有的HTML、CSS和JavaScript文件后,会开始执行页面中的JavaScript代码。JavaScript代码可以修改DOM树、处理用户交互等。
页面加载完成:当所有资源都下载完成,并且JavaScript代码执行完毕后,页面加载完成。此时,用户可以与页面进行交互。

以上是从输入URL到页面渲染完整的过程,其中涉及到了DNS解析、建立TCP连接、发送HTTP请求、服务器处理请求、页面渲染、下载资源和执行JavaScript等步骤。这些步骤是浏览器和服务器之间进行通信和页面渲染的关键环节。
二、前后端分离与不分离的渲染区别在URL到网页渲染的过程中,前后端分离模式和前后端不分离模式有以下差异:

页面渲染方式:在前后端分离模式中,后端通常只负责提供数据接口,前端负责通过API请求数据并进行页面渲染。前端使用JavaScript框架(如React、Angular、Vue等)动态生成DOM树,并将数据填充到页面中。而在前后端不分离模式中,后端负责生成完整的HTML页面,包括页面结构、样式和数据。
数据获取方式:在前后端分离模式中,前端通过API请求数据,后端返回JSON或其他格式的数据。前端负责解析和展示数据。而在前后端不分离模式中,后端在生成HTML页面时,会将数据直接嵌入到页面中,前端无需再通过API请求数据。
页面加载速度:由于前后端分离模式中,前端需要通过API请求数据并进行页面渲染,因此页面加载速度可能会受到网络延迟和前端渲染的影响。而在前后端不分离模式中,后端直接生成完整的HTML页面,页面加载速度可能会更快。
总的来说,前后端分离模式相对于前后端不分离模式更加灵活,前端可以使用不同的技术栈进行开发,数据交互更加灵活,但也增加了前端开发的复杂性和页面加载速度的影响。而前后端不分离模式相对简单,但灵活性较低。选择哪种模式取决于具体的项目需求和团队技术栈。