作者:Socket链接:https://zhuanlan.zhihu.com/p/677347530
TLDR:本文提供了一个使用大模型来构建端到端大规模对话推荐系统的路线图。具体的,其提出了用户偏好理解、对话管理和可解释推荐的新实现,并将其作为LLM驱动的集成架构的一部分。为提高个性化,本文描述了大模型如何使用可解释的自然语言配置文件,并使用它们来调整会话级上下文。

论文:https://arxiv.org/abs/2305.07961
在传统的推荐系统模式中,用户只能被动的在推荐列表中消费物料,缺乏深入参与推荐机制的机会。由此当用户面对推荐系统可能带来的不佳体验时,比如流行度偏差、低效的兴趣试探、信息茧房等,常常感到束手无策。对话式推荐系统(CRS)对此带来了创新转变,它通过对话交流的方式向用户做推荐,不再单一的依赖于用户行为,而是能随着用户提供的反馈语句逐渐优化所推荐的内容。在对话式推荐系统中,用户对推荐系统拥有更强的影响力。论文中给出 YouTube 场景下的对话式推荐系统如下,图片中左边为系统与用户的对话页面,右边为系统给出的推荐结果。淘宝的服务助手中也存在类似的对话推荐系统,但推荐内容会在对话中直接给出。

大规模语言模型集成了海量知识内容且具备强大的逻辑推理能力,能够以自然语言的形式与用户进行互动交流,与对话式推荐系统相当契合。在此背景下 Google 在 YouTube 场景中基于大语言模型 LaMDA 实现了对话式推荐系统 RecLLM,开启了对话式推荐系统的新模式。
RecLLM
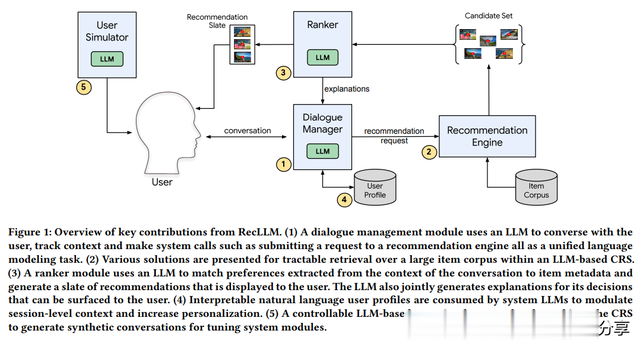
如下图所示,RecLLM 的整体框架包含以下几个部分:(1)对话管理模块,负责与用户交流并适时向推荐系统发起请求;(2)召回模块,负责在大规模语料库中检索出适合的推荐候选集;(3)排序模块,对推荐候选集合评分并提供推荐理由;(4)用户画像模块,负责形成可解释性的用户兴趣并参与推荐流程;(5)用户模拟器,模拟用户以生成对话示例,在系统冷启时作为样本对各个模块中的 LLM 做微调。
对话管理
对话管理模块的核心功能包括两部分,其一是实现与用户的互动交流,其二是适时向推荐系统发起请求,以刷新推荐列表。为实现推荐职能,要求对话管理模块能够在与用户的交流中,有效的将对话引导至推荐相关话题,但引导的过程不能太生硬,即要注意对话的自然流畅、掌握恰当的时机和交流方法来启发用户以抽取其兴趣喜好。对话管理模块通过 LLM 驱动,上述话题引导的功能需特定数据对模型做微调来强化。
输入到大模型中的数据可分为三个部分,如下图所示。首先是 Dialogue,它涵盖了会话的上下文信息;其次是 User Profile 用户画像,其生成逻辑在下文讲解;最后是 Item Summary,为当前推荐内容的概述。模型的输出同样分为三个部分:首先是 Context tracking,对会话上下文的总结;其次是 Instruction,即由模型产生的指令,这两个部分类似于思维链,为后续步骤的正确推理做铺垫。最终部分为 Response,它包括两种输出形式:“Response: <message>”旨在与用户进行交流,而“Request: <query>”则用于向推荐系统发起请求。

召回
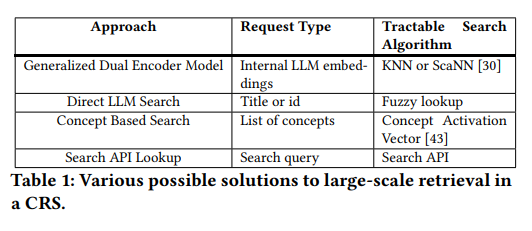
论文探讨了四种不同的推荐召回策略,如上图表格。首先是“Generalized Dual Encoder Model”,即最常用的双塔召回方法。由于 RecLLM 策略的设计理念是仅通过分析用户的对话内容来抓取用户的兴趣点,而不依赖于任何点击或其它行为数据,因此无法使用行为样本训练双塔。RecLLM 将会话上下文等用户信息输入至 LLM,直接使用其隐藏层作为用户向量,而物料向量则依赖于其他业务场景中已有的物料表示。然而,未经训练的方式无法确保用户和物料向量处于同一语义空间内,这导致了较差的性能表现;第二种是“Direct LLM Search”召回,通过 LLM 直接生成物料的 ID 或标题,进而在物料库中进行匹配。这种方法的缺点是,对大模型做微调既耗时又劳力,并且无法应对物料库的频繁更新;第三种方法为“Concept Based Search”,这是对双塔召回的改进。在这种方式中,LLM 输出一组相关“概念”,并利用“Concept Activation Vectors”将这些概念聚合并映射到物品表示空间中,从而确保用户和物品在相同的语义空间内。尽管如此,概念生成和概念激活向量的使用可能会损失一定的准确性,进而影响推荐精度;最后一种是“Search API Lookup”召回策略,这里大模型生成的是搜索查询 query,随后利用已经存在于业务中的搜索 API 来获得推荐内容。
排序

召回生成的候选集中的每一物料都将逐一被 LLM 打分,并同时生成语言解释,其流程如上图。由于内容冗长,物料的 Item Metadata(例如视频字幕、用户评论等)和用户对话上下文 Context 都需经过总结处理后再输入到 LLM 中。随后,该模型会输出评分以及语言解释,语言解释除了向用户展示外,也起到了思维链的作用。
用户画像
虽然用户在会话过程可以明确表达自身喜好,但为了提供更加个性化的体验,创建用户画像仍然十分必要。例如,如果用户指出他们不喜欢看偶像剧,那么应该在用户画像中记录该偏好,有助于避免未来用户重复提及。文本形式的用户画像不仅解释性强,而且还允许用户自己手动进行编辑和调整。
用户画像由三个关键部分组成。首先,Memory Extraction 负责使用 LLM 识别并记录用户显著的喜好表达,例如识别“我不喜欢看偶像剧”,并将其加入到用户画像。其次,Triggering and Retrieval 负责匹配每轮的对话内容与用户画像之间的文本相似性,由此筛选出所需要使用的用户画像。最后,System Integration 解决是关于如何将代表长期兴趣的用户画像与当前对话内容集成,即使它们相互矛盾,仍能够融合到一起的问题。例如,一个用户可能平时不喜欢偶像剧,但由于对某个热点事件感兴趣,可能暂时需要查找特定的偶像剧。同样,RecLLM 将两者统一输入至 LLM,借助于其强大的文本理解能力和推理能力来解决这一矛盾。
数据模拟和微调
用户模拟器的任务是仿真用户与对话式推荐系统(CRS) 的交互响应。为了确保用户模拟器的真实性,它与 CRS 互动所产生的对话分布 Q 应和真实用户与 CRS 的对话分布 R 无差异。RecLLM 提出了衡量两分布差异性的三种不同策略。第一种方法依赖于人工判断;第二种方法涉及创建分类器以确定样本是否来自真实分布;第三种方法则是构建对话的主题、情感和用户意图等细粒度分类器,精准的评估两个分布间的差异。
用户模拟器通过 LLM 实现,为了确保其真实性,RecLLM 提出了两种控制策略。第一种为全局对话控制,涉及通过类似用户画像声明作为输入来引导 LLM,例如:“I am a twelve year old boy who enjoys painting and video games”。第二种则是单次对话控制,利用用户在其他业务中的行为序列(例如搜索引擎中的 Query 序列)实现对用户对话轨迹的模拟。使用用户模拟器便可生成微调 LLM 的样本,例如额外输入提示词“在第 j 轮对话中提出生成 x 物料推荐的需求”。召回和排序阶段使用模拟的数据来微调即可。其中在召回阶段中为解决样本选择偏差问题需要额外负采样。对于对话管理模块,使用了 RLHF 算法来微调。

更多技术细节请阅读原始论文。