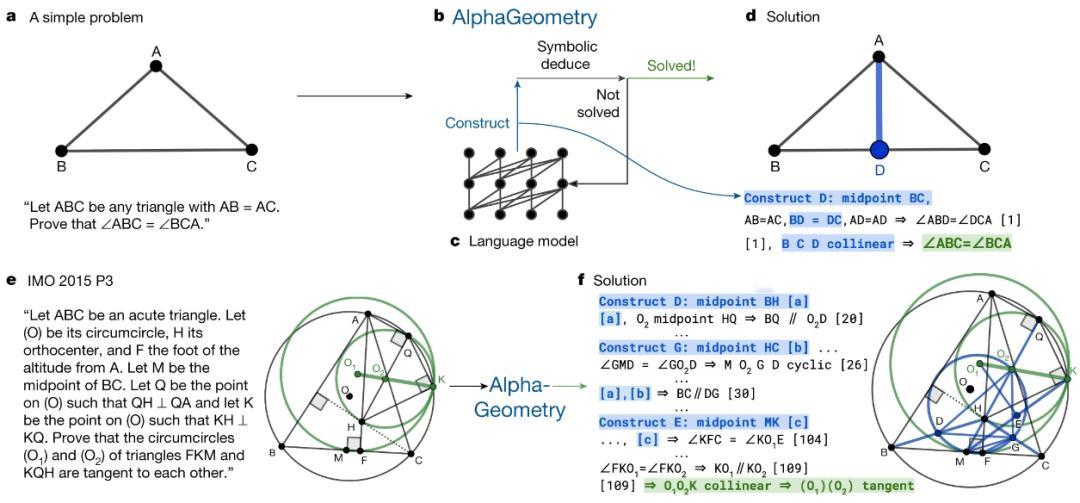
【让AI学做奥数题,又被它拿下了?】开发出AlphaGo的Deepmind实验室的研究者没有停止脚步。这次,他们把挑战的目标定为数学奥林匹克竞赛里的几何证明题。研究者训练新的AlphaGeometry模型,向这些究极难题发起了挑战。
证明几何题跟下围棋的主要区别是,围棋有清晰的规则,并且很容易知道盘面的优劣,并根据打分系统来决策。这就意味着,AI很难像下围棋那样,通过自己进行左右互搏来找到最佳方案。另外,让AI学习人类解题过程时,是有直觉与逻辑作为出发点的,而这些东西难翻译给AI听。
针对这种困难,AlphaGeometry使用了一种神经符号方法,通过大规模的探索从头开始证明定理,回避了向人类学习证明几何问题的过程。通过综合数百万个不同复杂程度的定理和证明,在该大规模合成数据上从零开始训练,指导符号演绎引擎在颇具挑战性的问题中通过无限分支点。
训练完成后,研究人员挑选了30道奥林匹克竞赛几何题来测试AlphaGeometry,它解出了其中的25个,已经逼近历届金牌得主的平均水平。与此同时,它还顺便发现了其中一道题的更广义情形下的答案。好嘛,都学会自己给自己出题了~#科学大院#