前天的小鹏AI DAY上,何小鹏在介绍XNGP的最新进展时,提到了这样一句话,“小鹏是国内首个将端到端大模型量产上车的公司”。

无独有偶,在北京车展前夕,华为在发布最新一代智驾ADS 3.0时,也表示用GOD网络和PDP网络实现了感知和规控的“端到端”。

当两家国内TOP.1级别的智驾大佬,都不约而同提到“端到端”时,我们就知道,智驾技术又要开启新一轮的军备竞赛了。
但对我们消费者来说,这“端到端”究竟是什么?有了“端到端”的智驾,又能给我们带来什么不一样的智驾体验?
智驾是怎么工作的?
想搞清楚“端到端”是什么,我们得先搞清楚智驾是怎么运行的。

在我看来,智驾可以分成两个部分,按前后顺序,分别是“感知”和“规控”。
“感知”很好理解,就是让智驾能“看到”车辆周围的交通道路环境和各种障碍物。
而“规控”就是基于感知的结果去制定行驶策略,再控制转向、油门、刹车去执行。

“感知”和“规控”一样,都需要输入数据,然后通过算法计算,输出计算结果。
但这里又提到了“数据”和“算法”,它们又是干什么的?
我们再来深究一下智驾的工作流程:
第一步是感知,摄像头&雷达会把它们看到的各种场景和障碍物,以数据的形式输入给感知算法。

而感知算法则会计算这些数据,从而搞清楚摄像头&雷达看到的各种物体究竟是什么、有多大、离我们有多远。
感知算法计算出的这些数据,接下来又会输入给规控算法,后者则会结合导航地图,规划接下来可行驶的行驶路径。
比如当规控算法确认,前方有一辆慢车需要超车后,就会规划出一条变道超车的路径,然后控制转向和油门去执行。

而在这一过程中,感知和规控算法还会持续关注慢车和附近的其它交通参与者的状态,来实时调整自己的行驶路径。
怎么让智驾更智能?
在智驾的这一套工作流程中,感知和规控算法都在不断地计算数据,这些计算工作,主要是靠众多“小的算法模型”来分工实现的。
这些“小模型”虽然工作兢兢业业,但也有自己的先天不足,这就导致智驾的舒适性和安全性,没有办法做到更好。

怎么理解“小模型”的不足呢?举个例子,这些“小模型”就像流水线上的工人,每个人只会做某个固定工序上的重复机械式工作。
如果让他们同时干好几条流水线,那这个时候他们肯定是顾不过来的,工作效率和质量都会大打折扣。
而如果让他们干超出固定工序的工作,由于之前可能没培训过,就很容易出错,后续工序也会被影响。
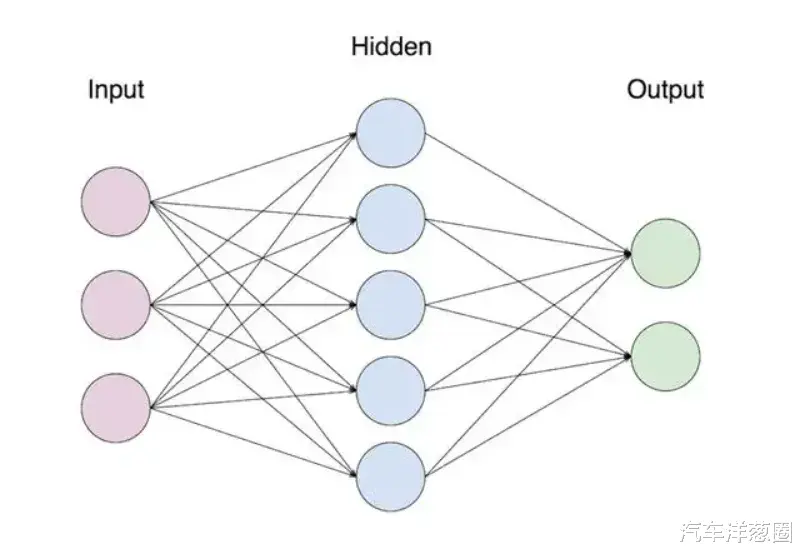
智驾也是这个道理。一方面是消费者想让智驾变得更智能,另一方面是国内复杂的路况也需要更强的算法应对,所以单纯靠大量“小模型”,以及各种手写的规则代码,肯定是没法穷尽驾驶时遇到的各种场景和情况的。
于是,车企开始用性能更强的“大模型”来取代“小模型”,原本庞大的模块化结构,也由此开始变得简洁起来了。
而在这个过程中,由于一些大模型的性能足够强,只需要一、两个大模型,就能搞定感知和规控的所有计算工作,而且效率更快,于是就有车企提出,有没有可能靠它们来实现智驾?

特斯拉最早提出了这个想法,并且号称用一个模型就在FSD V12上实现了;华为和小鹏则是紧随其后,先后宣布了对应的算法升级。
而特斯拉、华为和小鹏提到的这个想法和算法升级,就是“端到端”。
“端到端”怎么让智驾更智能?
简单来说,所谓的“端到端”就是从感知层的数据输入,到规控层的策略输出,这一整套流程,都由一个或两个大模型搞定。
之所以“端到端”能做到这一点,是因为大模型的性能足够强。
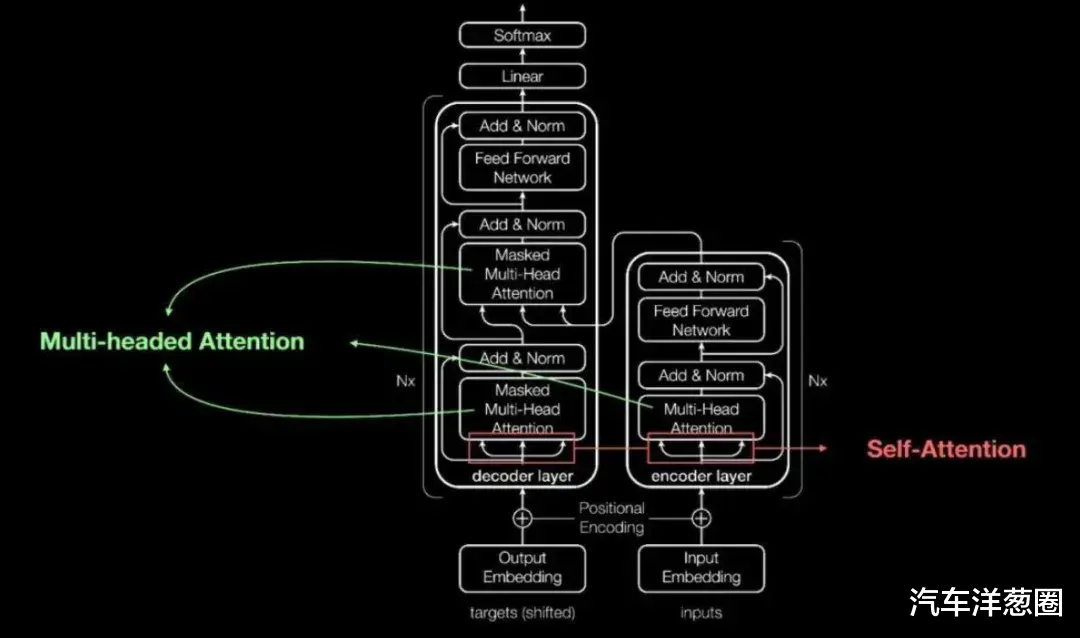
按照车企的描述,这些基于Transformer架构打造的深度神经网络大模型,不仅具备超高的并行计算能力,还可以借助自注意力机制获得更强的学习理解能力。
以上换成说人话的版本,就是大模型既能同时计算大量数据,又能计算复杂数据,其实就是AI赋能了智驾,直接给打开了一个无上限的能力天窗。
而这就能赋予智驾在面对复杂交通场景时更快的反应速度和更拟人的驾驶风格。
而在取代以小模型为主的模块化结构的同时,大模型也取代了相当多的手写代码,让智驾的算法结构更加精简了,这有利于提升算法的运行效率。
比如马斯克之前就说,“端到端”的FSD V12只有2000多行代码,而之前的FSD V11则有3000多万行。
“端到端”完美无瑕?
虽然“端到端”有无法忽视的优势,并且也已经成为了智驾技术发展的下一阶段,但它在目前阶段,其实也并不是一个靠谱的技术。
概念容易被营销利用
首先是对车企来说,“端到端”是一个非常好的营销概念,是不论如何,只要有条件,就要努力蹭一蹭的。
于是,这就导致大家对“端到端”的定义,始终处在一种非常模糊的状态,这就导致它的实际效果,可能会没你想得那么好。

比如按照特斯拉的描述,“端到端”就应该是“一个模型走天下”,这也是目前大家比较公认的、最严格意义上的“端到端”。
而华为则是在ADS 3.0上,用两个“大模型”,分别实现了感知和规控的“端到端”。这个说法有点取巧,但也算合乎逻辑。

小鹏在AI DAY上的说法则更模糊,因为XNGP是被分为了感知XNet和规控XPlaner两部分,个人猜测可能和华为类似,但也不好说。
这些“端到端”大模型虽然性能够强,但终究是要靠有效数据去训练、从而提升驾乘体验的,所以如果训练不够、或者训练不到位,体验都不会太好。
而除了“端到端”,“大模型”的定义也一直在被车企模糊。比如传统认知里的大模型,就真的是一个单独的、大参数的深度神经网络模型。
而有些车企的大模型,实际可能是一些中模型和小模型的集合,只是这个集合的规模很大,所以叫做大模型。
听起来很扯淡是不是?但这就跟方便面包装袋上“一切解释权归厂家”的字眼一样,反正车企说是它就是,其余你别管就是。
自带的黑盒属性
“端到端”极其依赖大模型,而大模型又是一类神经网络结构。
而神经网络有一个先天缺点,就是具备不可解释性,也叫“黑盒”属性。

换成说人话的版本,就是神经网络的计算过程,是一个“黑盒”。你能给到它输入数据,并让它得出正确的计算结果,但你不知道这个结果是被它怎么算出来的。
举个例子,比如智驾在直线行驶时突然变道了,而附近既没有障碍物,也不需要切换车道,显得非常莫名其妙。
这个突然变道的策略就是一个黑盒。我们不知道智驾为什么要变道,神经网络也不会告诉我们它为什么这么想。

而如果当时相邻车道正好有其他障碍物,或者恰逢路面湿滑、车速过快,那么这就很有可能要酿成事故了。
神经网络的“黑盒”会给智驾的安全性带来影响。而“端到端”智驾又主要靠大模型来工作,所以“黑盒”问题也会被放大。
“黑盒”问题现在还无解,车企能做的,无非也只是靠增加数据标注来提供更多可解释性的推导依据,或者给大模型绑上更多的规则代码,确保它不要太放飞自我。
总结
总的来说,“端到端”是一项非常重要的智驾技术,它不仅能让智驾变得更智能好用,还会指引智驾通往最终的无人自动驾驶。
但其中的安全风险也同样重要,因为对消费者来说,“端到端”并不能解决安全问题;并且技术上的领先≠体验上的领先,特斯拉的FSD V12就是个例子。
另一方面,车企为了营销,也在不断稀释“端到端”的含金量,就像之前某些车企公布的销量榜单,只要前置定语足够多,我就是第一名。
消费者想要分辨车企技术实力的难度也在不断增加,而我们则会坚持去伪存真,继续帮助大家去解读汽车技术。