研究表明AI看不懂多视角画面多模态新标准无一模型及格
多模态大语言模型的多视角理解有多难?GPT-4o竟然连及格线都没摸到。
所谓“多视图”理解,是让AI像人类一样从不同角度整合信息。
此前一直缺乏评测标准,UC伯克利、香港大学、牛津等团队,联合推出All-Angles Bench基准,专门评估AI模型在遮挡、相对位置判断、相机视角识别等方面的能力。
测试覆盖90个真实场景,2100+多视图问答对,囊括Counting、Attribute Identification、Relative Distance等六大任务,全面考察AI的三维理解力。【图1】
他们评测了27个主流模型,结果发现,多模态大语言模型与人类水平之间存在显著差距。
进一步研究发现,多模态大模型存在两种主要的缺陷模式【图2】:
(1)在遮挡情况下跨视图对应能力较弱;
(2)对粗略相机位姿的估计能力较差。
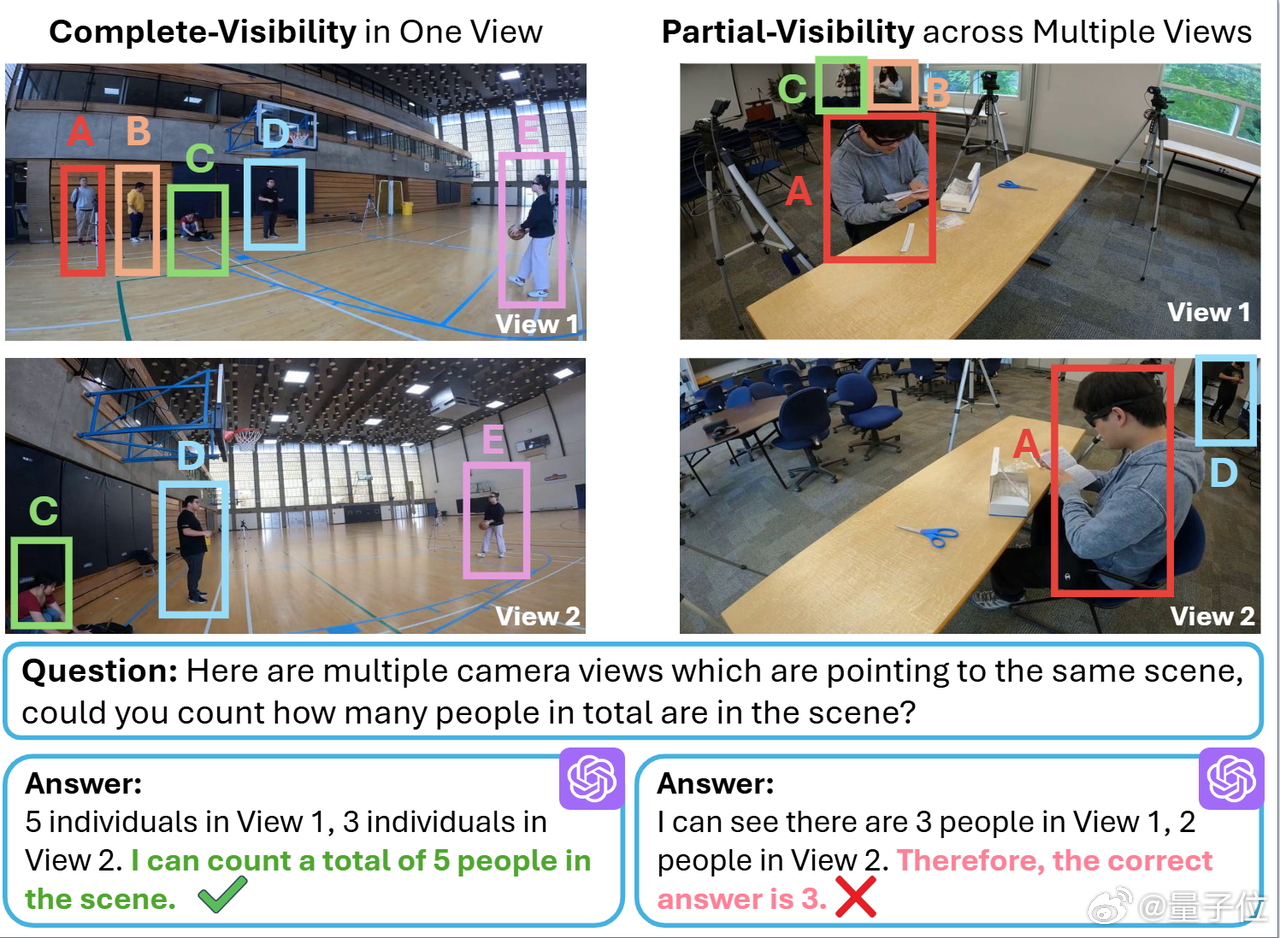
此外,GPT-4o有时会选择每个视角中的最大数量,而不是对跨视角的物体数量进行统一统计。【图3】
通过可视化的方法,研究人员让MLLM推理多视图下的物体和相机的位置与朝向。
虽然GPT-4o和Gemini-2.0-Flash对单张图像的场景理解表现尚可,但它们在对齐不同的相机视角时存在困难,难以正确处理视角变换。【图4】
论文:
项目: