深度学习模型参数量和训练数据集的爆炸式增长,以 Llama 3.1 为例:4050 亿参数、15.6 万亿 token 的训练量,如果仅靠单 GPU可能需要数百年才能跑完,或者根本无法加载模型。
并行计算(Parallelism)通过将训练任务分发到多个 GPU(单机多卡或多机多卡),并利用通信原语同步状态,能让训练过程变得可控且高效。
本文讲详细探讨Pytorch的数据并行(Data Parallelism)
扩展算力的两种路径扩展训练规模无非两种方式:纵向扩展(Vertical Scaling) 和 横向扩展(Horizontal Scaling)。
纵向扩展:
简单粗暴地升级硬件。比如把 10GB 显存的显卡换成 30GB 的。这种方式不需要改动代码,原本跑不起来的模型现在能跑了或者可以调大 batch size加快训练速度。
横向扩展:

增加机器数量。比如增加 7 台同配置(10GB)的机器,通过网络互联每台机器可以挂载单卡或多卡。这种方式需要代码层面的适配,利用 PyTorch 的分布式模块进行通信。
数据并行 vs 模型并行数据并行 (Data Parallelism):
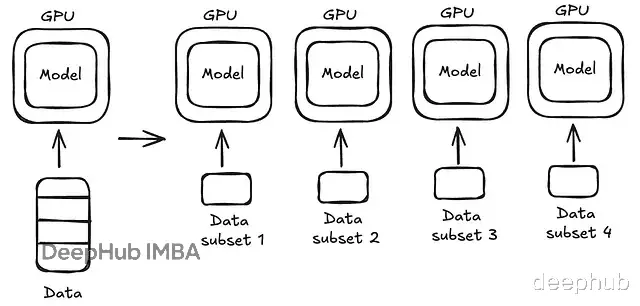
当模型本身能塞进单张 GPU,但数据量太大时,我们可以将模型复制到所有 GPU 上,将数据切分(Split),每个 GPU 并行处理一部分数据,在反向传播时同步梯度。
模型并行 (Model Parallelism):
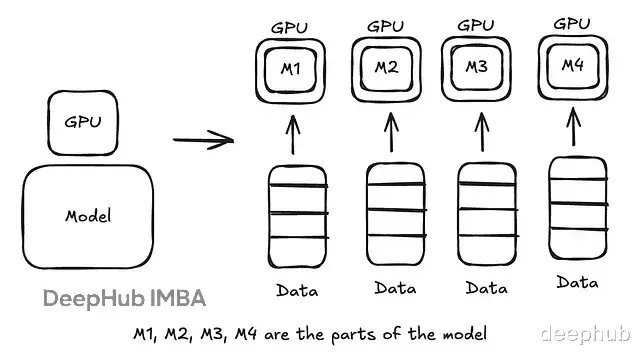
当模型大到单张 GPU 放不下时使用。将模型切分成不同部分,分配给不同 GPU。每个 GPU 负责计算前向/后向传播中的一部分层。
实际超大模型训练中,通常是两者的混合。
前置概念:梯度累积在讲 DDP 之前,先回顾一个基础技巧:梯度累积(Gradient Accumulation)。PyTorch 的设计中,loss.backward() 计算出的梯度默认是累加的,而非覆盖。
import torch # Let us define a tensor with requires_grad = True x = torch.tensor(4.0, requires_grad=True) # Creating a function y=x^2 y = x*x # Calculating dy/dx y.backward(retain_graph=True) # retain_graph = True because pytorch automatically removes the computation # graph and intermediate tensors once backward is called to save memory # If we want to call backward again, we need to tell pytorch not to delete # the computation graph and intermediate tensors print(f"Gradient of y w.r.t x after the first backward: {x.grad}") # Output: 8.0 as dy/dx = 2*x = 2*4 # Now let us try to call backward again y.backward() print(f"Gradient of y w.r.t x after the second backward: {x.grad}") # Output = 16 because 8 from the previous backward is added up here
利用这个特性,当大 Batch Size 导致 OOM 时,可以将其切分为多个 Mini-batch,连续执行多次 backward() 累积梯度,最后执行一次 optimizer.step()。这是单卡解决显存瓶颈的常用手段。
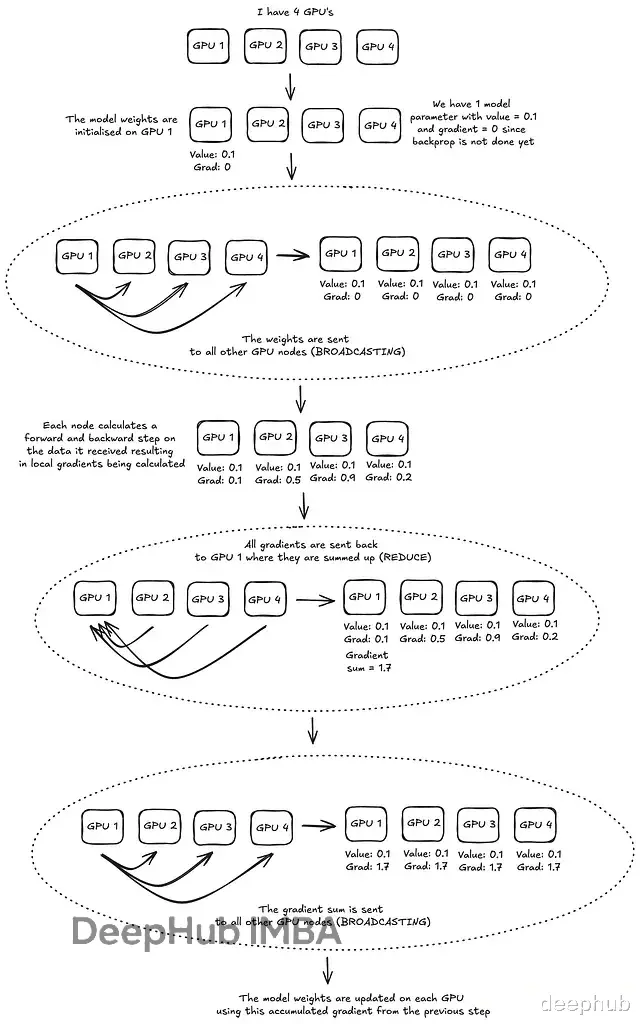
分布式数据并行 (DDP) 工作流PyTorch 的 DistributedDataParallel (DDP) 是实现数据并行的核心模块,基于 c10d 的 ProcessGroup 进行通信,每个进程(Process)通常控制一个 GPU 并持有一个模型副本。
DDP 的标准执行流程如下:
初始化 ProcessGroup:建立进程间的通信握手。
广播权重(Broadcast):训练开始时,Rank 0 节点的模型权重被广播到所有其他节点,确保初始状态一致。
前向反向传播:每个节点在自己的数据子集上独立计算。
梯度归约(All-Reduce):各节点的梯度被汇聚(求和或平均),然后同步回所有节点。
参数更新:各节点使用同步后的梯度独立更新权重。
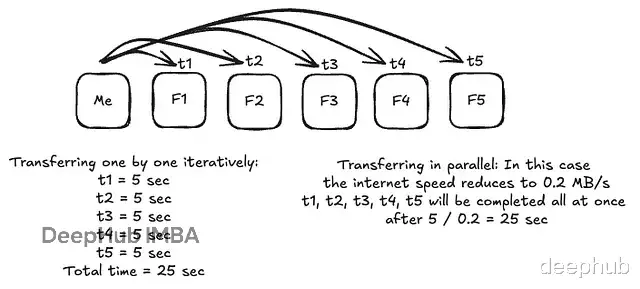
分布式训练中,点对点(Point-to-Point)通信效率太低。假设要把 5MB 参数发给 5 个节点,逐个发送会导致耗时线性增长。集合通信(Collective Communication) 利用拓扑结构(如树状、环状)并行传输,是高性能计算的基石。
DDP 主要依赖两个原语:
Broadcast: 将数据从一个节点(通常是 Rank 0)分发给其余所有节点,用于初始化权重。
Reduce / All-Reduce: 将所有节点的数据汇总,DDP 中用于梯度同步。
故障恢复 (Failovers) 与 Checkpointing在分布式环境中,节点故障是常态,一旦某个 Rank 挂了,重启整个集群从零训练成本过高。必须使用 Checkpointing:定期将模型权重写入共享存储(Shared Disk)。
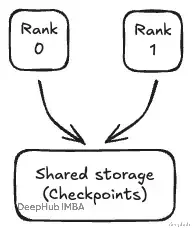
这样恢复训练时,可以从最新的 Checkpoint 加载权重。这里需要注意的是只允许 Rank 0 写入 Checkpoint,避免多进程同时写文件造成损坏。
代码实战:从 CPU 到 GPU下面通过代码演示 DDP 的完整流程。先以 CPU 模拟多进程环境,再迁移到 GPU。
基础组件:Dataset 与 Mode
import torch import torch.nn as nn from torch.utils.data import Dataset class SimpleDataset(Dataset): def __init__(self, size=100): self.size = size self.data = torch.randn(size, 10) # generate 100 samples each having dimension 10 self.labels = torch.randn(size, 1) # generate labels corresponding to each sample def __len__(self): return self.size def __getitem__(self, idx): return self.data[idx], self.labels[idx] class SimpleModel(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(10, 5) self.fc2 = nn.Linear(5, 1) def forward(self, x): x = torch.relu(self.fc1(x)) return self.fc2(x)
初始化环境
setup 函数负责建立进程组。
import os import torch.distributed as dist def setup(rank, world_size): os.environ['MASTER_ADDR'] = 'localhost' # IP of the "master" node os.environ['MASTER_PORT'] = '12355' # Port of communication # If we have 4 processes, each process independently calls setup() with # its own rank dist.init_process_group(backend='gloo', rank=rank, world_size=world_size) # 'gloo' is the collective communication backend used for CPU # nccl is used for CUDA print(f"\n{'='*60}") print(f"[Rank {rank}] Process initialized!") print(f"[Rank {rank}] Backend: {dist.get_backend()}") print(f"[Rank {rank}] World Size: {dist.get_world_size()}") print(f"{'='*60}\n")
数据切分:DistributedSampler
这是数据并行的关键。DistributedSampler 会根据 Rank ID 自动切分数据集,确保每个进程拿到不重叠的数据子集。
注意:必须在每个 epoch 开始前调用 set_epoch(epoch),否则每个 epoch 的数据切分顺序将完全一样导致模型只见过部分数据,影响泛化能力。
# Example usage conceptual# Create DistributedSampler for each rank # sampler_rank0 = DistributedSampler(dataset, num_replicas=4, rank=0) # ... # Loopfor epoch in range(num_epochs): train_sampler.set_epoch(epoch) # Different shuffle each epoch for batch in train_loader: # Training code
核心训练 Loop (Worker)
from torch.nn.parallel import DistributedDataParallel as DDP def print_separator(rank, message): print(f"\n[Rank {rank}] {'-'*40}") print(f"[Rank {rank}] {message}") print(f"[Rank {rank}] {'-'*40}") def train_worker(rank, world_size, num_epochs=2, batch_size=8): # setup the distributed environment setup(rank, world_size) model = SimpleModel() # wrap the model with DDP # This is where weights are synchronized across ranks ddp_model = DDP(model) dataset = SimpleDataset(size=32) sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=False) dataloader = DataLoader(dataset, batch_size=batch_size, sampler=sampler) optimizer = optim.SGD(ddp_model.parameters(), lr=0.01) criterion = nn.MSELoss() for epoch in range(num_epochs): sampler.set_epoch(epoch) # Ensure different shuffling per epoch epoch_loss = 0.0 for batch_idx, (data, target) in enumerate(dataloader): optimizer.zero_grad() output = ddp_model(data) loss = criterion(output, target) # Backward pass - THIS IS WHERE DDP MAGIC HAPPENS loss.backward() # Gradients are synchronized (All-Reduce) here automatically optimizer.step() epoch_loss += loss.item() dist.destroy_process_group() print(f"[Rank {rank}] Training completed and cleaned up!\n")
验证集不能像训练集那样随意。有两种处理策略:
Rank 0 独占:只在 Rank 0 上跑全量验证集。这个方法比较简单但会造成其他 GPU 等待所以效率低。
分布式验证:各 Rank 跑一部分最后聚合 Loss 和样本数,一般都会用这个方案。
def validate(model, val_loader, criterion, rank, epoch): model.eval() val_loss = 0.0 num_samples = 0 with torch.no_grad(): for batch_idx, (data, target) in enumerate(val_loader): output = model(data) loss = criterion(output, target) val_loss += loss.item() * data.size(0) num_samples += data.size(0) # Aggregate metrics across all processes total_loss_tensor = torch.tensor([val_loss]) total_samples_tensor = torch.tensor([num_samples]) # Sum across all processes dist.all_reduce(total_loss_tensor, op=dist.ReduceOp.SUM) dist.all_reduce(total_samples_tensor, op=dist.ReduceOp.SUM) global_avg_loss = total_loss_tensor.item() / total_samples_tensor.item() return global_avg_loss
启动进程,CPU 演示通常用 mp.spawn:
def main(): world_size = 2 mp.spawn( demo_worker, args=(world_size,), nprocs=world_size, join=True )
生产环境迁移:CUDA 与 Torchrun在实际 GPU 训练中,需要做 5 点改动:
Backend: gloo -> nccl (NVIDIA 专用,速度最快)。
Model: model.cuda(rank)。
DDP Wrapper: DDP(model, device_ids=[rank])。
Data: data.cuda(rank)。
Device: torch.cuda.set_device(rank)。
启动方式不再推荐使用mp.spawn,而是直接使用Torch自带的CLI工具 torchrun,它能自动处理环境变量(RANK, WORLD_SIZE, LOCAL_RANK)并支持故障重启。
# Code expects env varsrank = int(os.environ["RANK"]) local_rank = int(os.environ["LOCAL_RANK"]) world_size = int(os.environ["WORLD_SIZE"]) demo_worker(rank, world_size)
运行命令:
torchrun --nproc_per_node=4 train.py
性能优化:Bucketing 与 OverlapPyTorch DDP 之所以快,不仅仅是因为分了数据,更在于它对通信的优化。
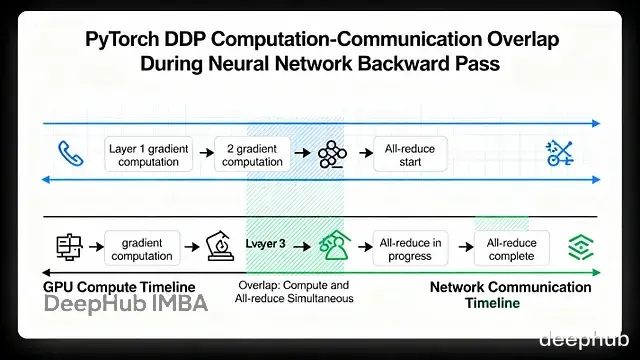
通信与计算重叠 (Communication Overlap)
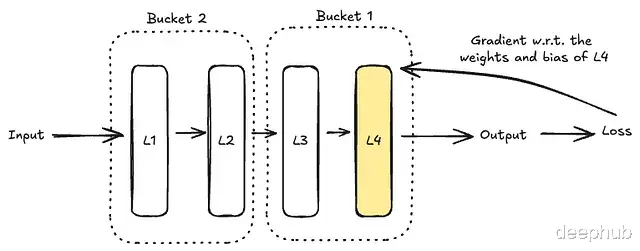
我们可能认为要等所有层的梯度算完再同步,但这会导致 GPU 出现长时间空闲(Wait)。所以DDP 的做法是一旦某层的梯度算出来,如果不被依赖,就立刻发送同步。
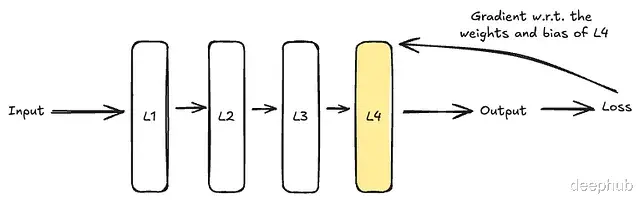
如上图,Layer 4 的梯度一算好,在计算 Layer 3 的同时,Rank 0 已经在处理 Layer 4 的同步了。
分桶 (Bucketing)
为了避免频繁发送小包导致网络拥塞,DDP 会将梯度打包进 Bucket(默认 25MB)。
当一个 Bucket 被填满(例如包含 Layer 4, 5, 6 的梯度),就会触发一次 All-Reduce。这种批量处理大幅降低了通信开销。
这是一个为您准备的结尾总结,保持了之前设定的专业且行动导向的风格,同时也呼应了原作者关于“下一篇讲解模型并行”的预告:
总结我们已经拆解了 PyTorch DDP 的核心运作机制:从底层的 ProcessGroup 通信握手,到梯度的 All-Reduce 同步,再到 Bucket 分桶与计算通信重叠的性能优化。掌握这些,你已经具备了将单卡代码低成本迁移到多卡集群的能力,不再受限于单机的训练时长。
https://avoid.overfit.cn/post/11d9f5d9b4fc4cd49cf1b8f97f09252f
作者:Trinanjan Mitra