DC娱乐网
deephub的文章
用 Scikit-LLM 和 Groq 搭建情感分析 pipeline
2026-07-15 21:04
deephub
用 Scikit-LLM 和 Groq 搭建情感分析 pipeline
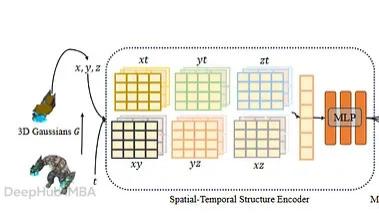
4D GS 是怎么工作的:从规范 Gaussian 到形变场的原理拆解
2026-07-08 21:08
deephub
4D GS 是怎么工作的:从规范 Gaussian 到形变场的原理拆解
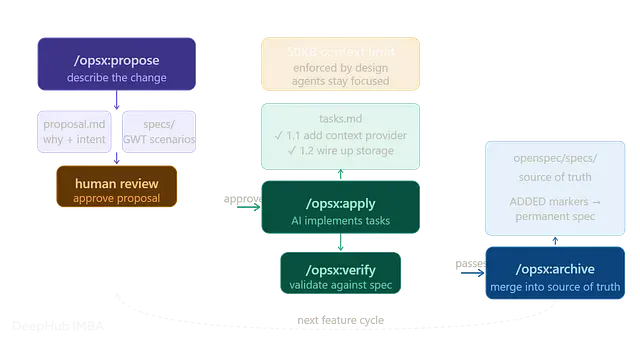
OpenSpec 三阶段工作流实操:从 Propose 到 Archive让代码返工率降到三分之一以...
2026-07-07 19:52
deephub
OpenSpec 三阶段工作流实操:从 Propose 到 Archive让代码返工率降到三分之一以下
Agent Harness 到底是什么:模型之外的那层控制系统
2026-07-06 20:37
deephub
Agent Harness 到底是什么:模型之外的那层控制系统
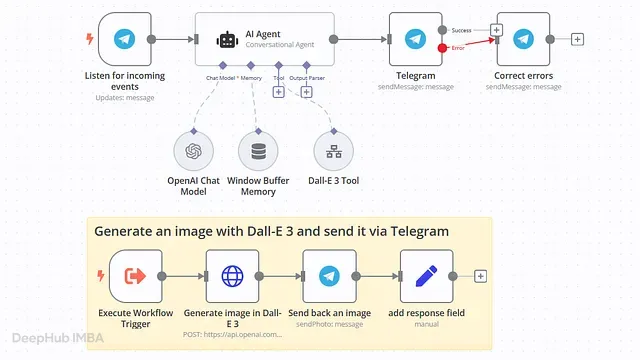
十个 AI Agent 工作流模板,照着搭就能用
2026-07-03 21:13
deephub
十个 AI Agent 工作流模板,照着搭就能用
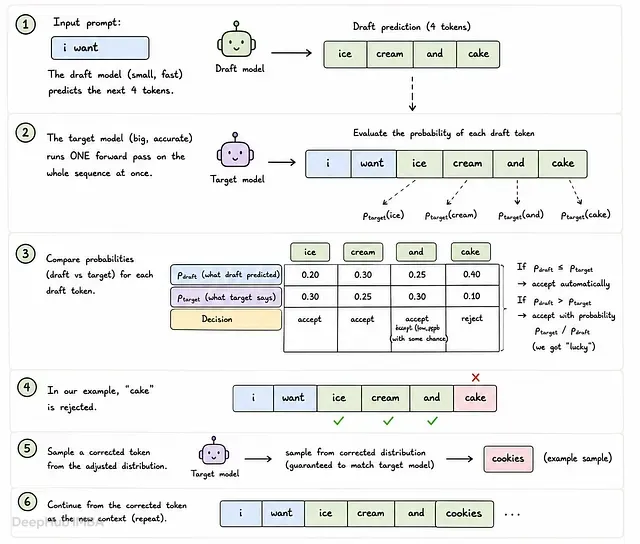
白得 2 到 3 倍加速的投机采样机制解析:草稿模型和目标模型是怎么配合的
2026-07-02 21:14
deephub
白得 2 到 3 倍加速的投机采样机制解析:草稿模型和目标模型是怎么配合的
Harness Engineering 实践案例:如何给编码 Agent 写一份行为规范
2026-07-01 19:53
deephub
Harness Engineering 实践案例:如何给编码 Agent 写一份行为规范
注意力架构变迁总结:稀疏、线性、SSM、混合架构如何摆脱 O(L²) 的代价
2026-06-30 21:36
deephub
注意力架构变迁总结:稀疏、线性、SSM、混合架构如何摆脱 O(L²) 的代价
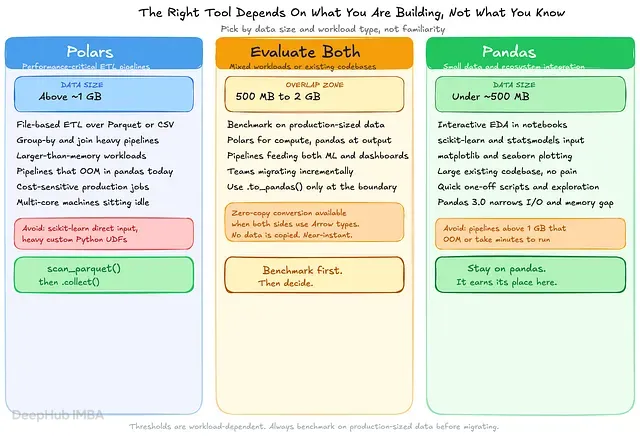
Polars vs Pandas 在生产 Pipeline 中的对比
2026-06-29 21:10
deephub
Polars vs Pandas 在生产 Pipeline 中的对比
UV vs pip vs Conda: Python环境管理应该怎么选
2026-06-28 20:44
deephub
UV vs pip vs Conda: Python环境管理应该怎么选
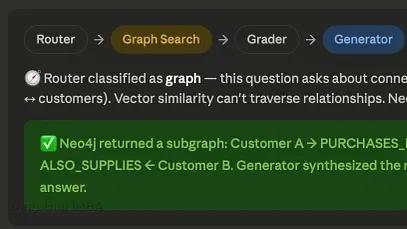
用 LangGraph 改造单一 RAG 架构:让 Agent 决定调用向量、图遍历还是网络搜索
2026-06-25 21:56
deephub
用 LangGraph 改造单一 RAG 架构:让 Agent 决定调用向量、图遍历还是网络搜索
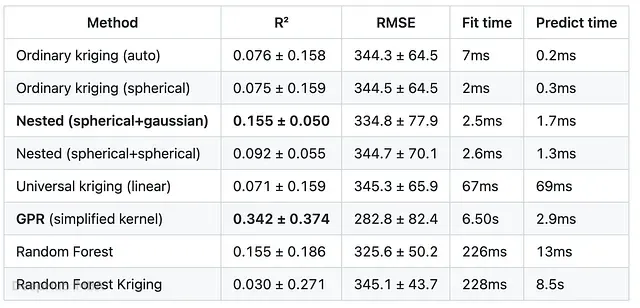
为什么Kriging 与高斯过程回归出自同一数学框架,但实际效果却差很远
2026-06-24 21:58
deephub
为什么Kriging 与高斯过程回归出自同一数学框架,但实际效果却差很远
百亿参数模型的并行训练:节点内张量并行、节点间数据并行
2026-06-23 21:06
deephub
百亿参数模型的并行训练:节点内张量并行、节点间数据并行
DiffusionGemma:用离散文本扩散和双向注意力,把推理瓶颈从内存带宽转移到算力
2026-06-22 23:20
deephub
DiffusionGemma:用离散文本扩散和双向注意力,把推理瓶颈从内存带宽转移到算力
微调LocateAnything-3B 实现超高密度的目标检测
2026-06-21 21:49
deephub
微调LocateAnything-3B 实现超高密度的目标检测
第一页
作者信息
deephub
提供专业的人工智能知识,包括CV NLP 数据挖掘等
分类: 科技
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量