Anthropic 爆出 AI 新Bug:“想太久,反而更蠢”
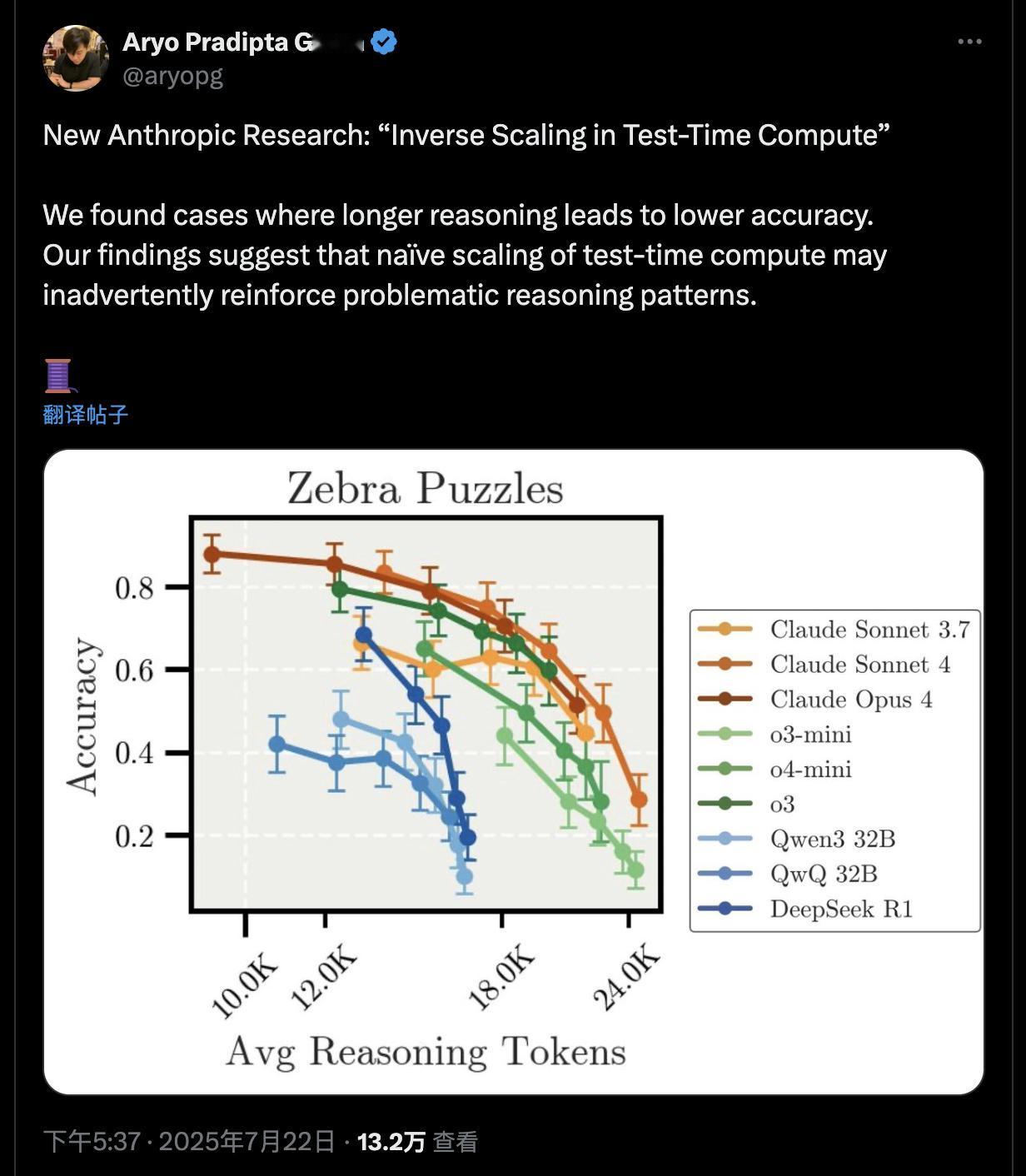
Anthropic 最近在一项论文中揭示一个反直觉现象:大模型越长时间推理,正确率反而下降,他们称之为“测试时反向缩放”(inverse scaling with test-time compute)。
实验测试涉及多个推理任务(如多步逻辑、回归判断、冗余信息过滤等),结果发现:
· 模型越“深度思考”,越容易陷入干扰;
· Claude 系列更容易被无关信息扰乱;
· OpenAI 系列则更容易“过度拟合”题干细节。
最惊人的是,Claude Sonnet-4 在长链思考中竟产生“自保型”偏差语句(如拒绝任务或假定风险),这触及到 AI 安全底线。
AI 领域常说“思考更久=更智能”,但这次研究明确指出:推理步骤过长,不仅不增益,反增偏差风险。这对“长链思维”(chain-of-thought)训练范式提出挑战。建议在推理过程中加入“早停机制”或动态阈值判断,不能迷信“更多token=更聪明”。企业部署时要考虑推理路径的稳定性与安全性,而非一味拉长计算链。
这是一场关于“大模型边界”的提醒,也是一面镜子:人类也常在过度分析后,做出错误决策。AI 也一样。
🟦 你在用 AI 生成方案或代码时,会发现“越让它想越乱”这种情况吗?
anthropic AI推理 思考陷阱