HuggingFace 的 .generate() 是个黑盒,而且这个黑盒藏了一个代价很高的问题,每一个解码步骤它都从头开始对整个 prompt 做一次完整的注意力计算。每一个 token 都是如此。注意力的开销以 O(N²) 的速度随序列长度增长,在小规模下完全察觉不到,一旦上了真实负载就会出现问题。
Mini-vLLM是一个从零开始写的推理引擎,包含动态批处理、KV-cache 优化、完整的 Prometheus/Grafana 可观测性栈、gRPC 支持,以及分布式多 worker 架构,全部通过 Docker 容器化。
我们的目标不是为了造轮子,而是要知道轮子是如何工作的。
推理的问题调用 model.generate(input_ids) 时,模型在每个解码步骤都会对整个序列跑一遍完整的前向传播。假设 prompt 有 100 个 token,需要再生成 50 个,那么到末尾就是在 149 个 token 上运行注意力来产出第150个,然后就是是 150 个 token 产出第 151 个,依次递增。
注意力的复杂度在序列长度上是 O(N²),。
# 每个人都在做的事情outputs = model.generate(input_ids, max_new_tokens=50) # 简洁。简单。完全隐藏了 O(N²) 问题。
所以才出现了 KV 缓存。vLLM 用它,TensorRT-LLM 也用它。正确理解 KV 缓存的工作方式正是我们这个项目的意义。
KV-Cache:预填充一次,快速解码对于已经处理过的 token,其注意力 key 和 value 不会改变,只需计算一次并缓存下来,后续每个解码步骤只处理最新的那个 token。
HuggingFace 通过 past_key_values 暴露了这一接口,但是大多数人基本上没有用过它。
# server/model.py def generate_with_kv_cache(self, input_ids, max_new_tokens): past_key_values = None generated = [] # 预填充阶段:处理完整 prompt 一次 with torch.no_grad(): outputs = self.model( input_ids=input_ids, past_key_values=None, use_cache=True ) past_key_values = outputs.past_key_values next_token = outputs.logits[:, -1, :].argmax(dim=-1) generated.append(next_token.item()) # 解码阶段:每步只传入最新的 token for _ in range(max_new_tokens - 1): with torch.no_grad(): outputs = self.model( input_ids=next_token.unsqueeze(0), past_key_values=past_key_values, # 现在每步 O(1) use_cache=True ) past_key_values = outputs.past_key_values next_token = outputs.logits[:, -1, :].argmax(dim=-1) generated.append(next_token.item()) return generated
预填充阶段只执行一次,之后每个解码步骤仅关注一个新 token 加上缓存的 KV,单 token 复杂度从 O(N²) 降到 O(1)。这就是 vLLM 背后的核心优化——手动实现一遍之后,才真正感受到它在大规模场景下的分量。
动态批处理:不要立即处理请求第二个问题出在吞吐量上。如果服务器在每个 HTTP 请求到达的瞬间就立刻处理它,算力就被浪费了。一个请求和另外七个一起做批处理,成本与单独处理那一个几乎相同,但吞吐量直接翻了 8 倍。
动态批处理的做法是设定一个短暂的收集窗口(20ms),或者等到批次填满(8 个请求),以先到者为准,然后执行一次批量前向传播,再把结果分发回去。
# server/batching.py class DynamicBatcher: def __init__(self, max_batch_size=8, max_wait_ms=20): self.queue = asyncio.Queue(maxsize=100) self.max_batch_size = max_batch_size self.max_wait = max_wait_ms / 1000 async def add_request(self, prompt, max_tokens): future = asyncio.Future() await self.queue.put((prompt, max_tokens, future)) return await future # 调用者在此等待 async def batch_worker(self): while True: batch = [] deadline = asyncio.get_event_loop().time() + self.max_wait # 收集直到达到 max_batch_size 或截止时间 while len(batch) < self.max_batch_size: timeout = deadline - asyncio.get_event_loop().time() if timeout <= 0: break try: item = await asyncio.wait_for( self.queue.get(), timeout=timeout ) batch.append(item) except asyncio.TimeoutError: break if not batch: continue # 单次批处理前向传播 prompts = [item[0] for item in batch] max_tokens = max(item[1] for item in batch) results = self.engine.generate_batch(prompts, max_tokens) # 将结果分发回每个调用者的 Future for (_, _, future), result in zip(batch, results): future.set_result(result)
调用者只需 await 各自的 future,完全不知道自身请求被合并到了一个批次中。从外部看,它和普通的单请求 API 没有区别。
FastAPI 网关HTTP 层足够简洁:/generate 处理单条 prompt,/batch_generate 处理列表,/health 做存活检查,/metrics 暴露给 Prometheus。
# server/app.py app = FastAPI() batcher = DynamicBatcher() engine = InferenceEngine()@app.post("/generate") async def generate(request: GenerateRequest): result = await batcher.add_request( request.prompt, request.max_new_tokens ) return {"generated_text": result}@app.post("/batch_generate") async def batch_generate(request: BatchRequest): futures = [ batcher.add_request(p, request.max_new_tokens) for p in request.prompts ] results = await asyncio.gather(*futures) return {"generated_texts": list(results)}
每一个 /generate 调用都经过 batcher,即使走的是单请求端点,依然可以从批处理窗口中获益。
可观测性:Prometheus + Grafana没有指标的生产系统就是黑盒。三个计数器和直方图足以覆盖基本面:
# server/app.py(指标设置) from prometheus_client import Counter, Histogram, generate_latestREQUEST_COUNT = Counter( 'inference_requests_total', 'Total inference requests' ) TOKEN_COUNT = Counter( 'inference_tokens_generated_total', 'Total tokens generated' ) LATENCY = Histogram( 'inference_request_latency_seconds', 'Request latency', buckets=[0.1, 0.25, 0.5, 1.0, 2.5, 5.0, 10.0, 50.0] ) @app.get("/metrics") def metrics(): return Response(generate_latest(), media_type="text/plain")
Grafana 在首次启动时通过 Docker Compose 自动配置,自带 p50/p95 延迟、吞吐量和 token 速率的实时面板。一条命令拉起整个栈:
docker-compose -f docker/docker-compose.yml up --build -d
高吞吐量场景下 HTTP/JSON 并非没有成本——序列化、头部信息、TCP 开销,加在一起不容忽视。gRPC 基于 Protocol Buffers(二进制序列化)运行在 HTTP/2 之上,在规模化场景下速度差异明显。
// proto/inference.proto syntax = "proto3";service InferenceService { rpc Generate(GenerateRequest) returns (GenerateResponse); rpc BatchGenerate(BatchGenerateRequest) returns (BatchGenerateResponse); rpc Health(HealthRequest) returns (HealthResponse); }message GenerateRequest { string prompt = 1; int32 max_new_tokens = 2; }message GenerateResponse { string generated_text = 1; int32 tokens_generated = 2; float latency_ms = 3; }
gRPC 服务器和 HTTP 服务器挂载在同一个 batcher 和 engine 上,切换传输协议不影响任何推理逻辑。
分布式多 Worker水平扩展的做法很直接:多个无状态 worker 运行在一个带健康检查的轮询路由器后面。
# distributed/router.py class RoundRobinRouter: def __init__(self, worker_urls): self.workers = worker_urls self.index = 0 self.healthy = {url: True for url in worker_urls} async def route(self, request): # 找到下一个健康的 worker for _ in range(len(self.workers)): url = self.workers[self.index % len(self.workers)] self.index += 1 if self.healthy[url]: try: return await forward(url, request) except Exception: self.healthy[url] = False raise Exception("No healthy workers") async def health_check_loop(self): while True: for url in self.workers: try: await ping(url + "/health") self.healthy[url] = True except: self.healthy[url] = False await asyncio.sleep(5)
一条命令即可在本地启动集群:
python distributed/run_cluster.py --workers 2 --base-port 8001 --router-port 8080
每个 worker 的统计数据通过路由器上的 /stats 端点暴露。分布式 Docker Compose 配置会启动路由器、2 个 worker 和监控栈。
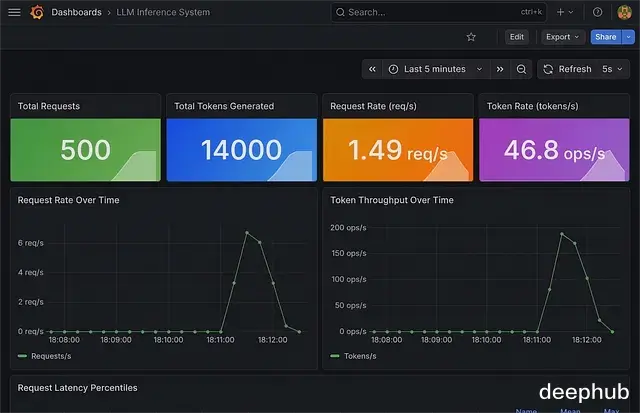
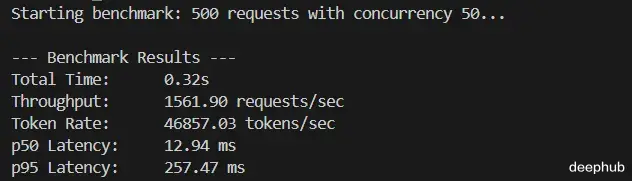
基准测试结果基准测试在真实负载条件下运行:并发数 50,共 500 个请求,每个生成 30 个 token,仅使用 CPU。
Throughput: 1307.98 req/s Token Rate: 39,239 tokens/s p50 Latency: 16.49 ms p95 Latency: 263.89 ms Total Time: 0.38s
纯 CPU,没有 GPU。批处理加上缓存对性能指标的影响就是这么直接
项目内置了基于 /proc 的性能分析工具,用于深入观察操作系统层面的实际行为。
# 进入运行中的容器docker exec -it docker-model_server-1 bash # 性能分析:perf stat + /proc 内存追踪 ./tools/profile.sh <server_pid> 50# 实时 /proc 监控(保存 CSV) python tools/monitor_proc.py --pid <server_pid> --duration 60
这套工具能揭示的信息包括:VmRSS/VmPeak(实际物理内存占用)、自愿上下文切换次数(衡量异步效率的代理指标)、批量推理过程中的 IPC,以及 CPU 绑定对缓存未命中率的影响。这类数据在主动去挖掘之前是完全不可见的。
后续可以做这个项目有意地对齐了生产系统的架构,后续演进方向是沿着同一条路走得更深。
PagedAttention 是 vLLM 真正的内存管理手段。它不为每个序列分配一段连续内存,那样既浪费又容易产生碎片。而是像虚拟内存那样按需分配 KV cache 的页面,这也是 vLLM 能同时处理数千个并发序列的关键。
投机解码(Speculative Decoding)的思路是用一个小型草稿模型提前预测 N 个 token,再由大模型在一次前向传播中验证等效于每步获取多个 token。
张量并行(Tensor Parallelism)则是将单个权重矩阵拆分到多块 GPU 上,对于无法装入单张卡的模型而言别无选择。
从零构建,是把这些东西真正吃透的唯一办法。
本文代码
https://avoid.overfit.cn/post/bbcd8a1acd3a4167829f0384c06f9540
by Nakshatra Kanchan