小红书开源首个多模态模型小红书新模型接近Gemini2.5Pro
小红书开源了多模态模型dots.vlm1,模型基于DeepSeek V3 LLM,在多个主流评测中表现接近Gemini 2.5 Pro、Seed-VL1.5等闭源模型。
在结构化图像、STEM推理、长尾识别、视觉语言融合等任务中,dots.vlm1展现出强大的泛化与理解能力:
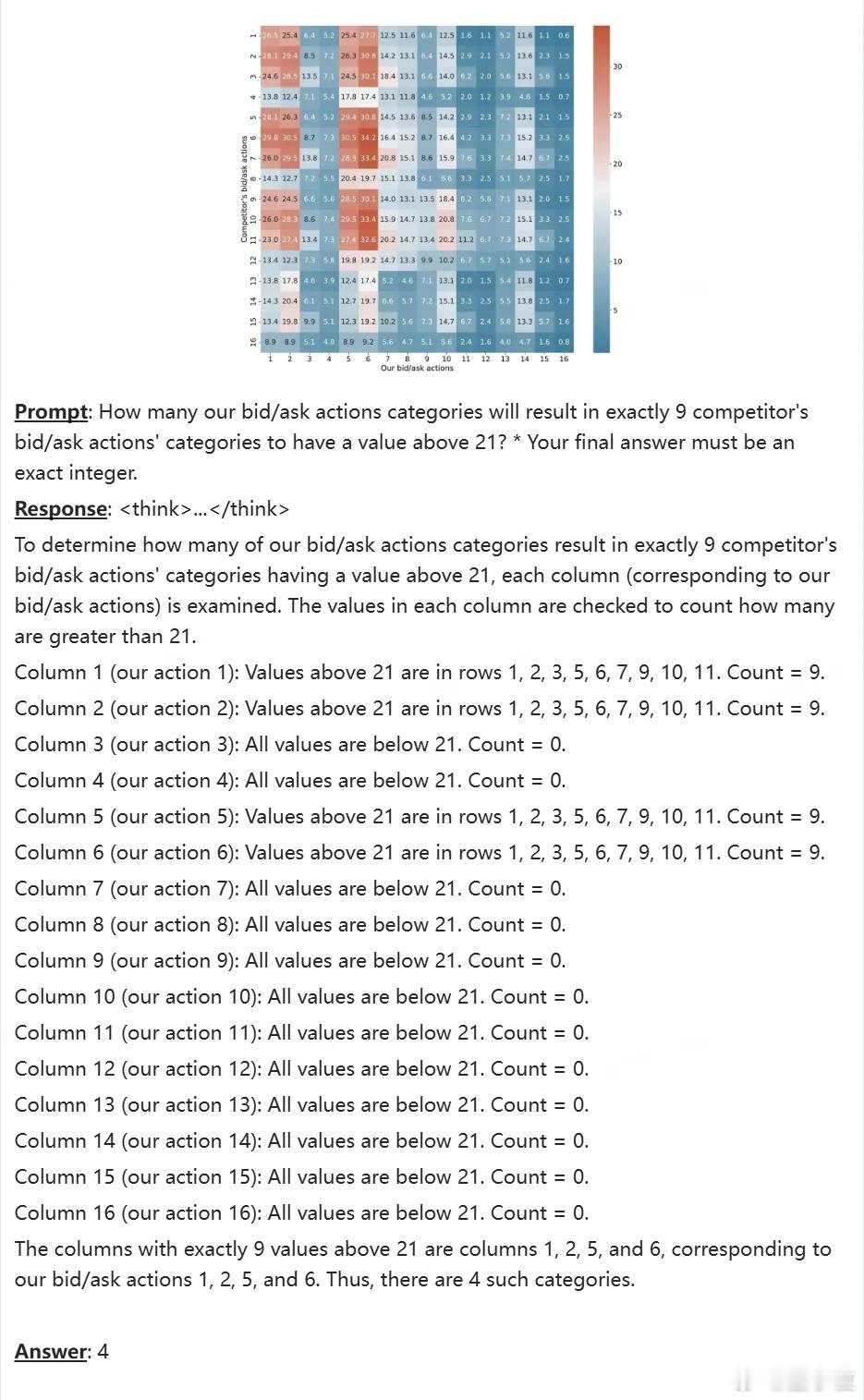
1. 复杂图表推理样例(参考图1)
模型需解析16×16热力图矩阵中的数值分布,判断每一列是否有恰好9个值大于21。任务看似简单,实则包含多步视觉感知、数值比对、行列遍历与最终计数判断。dots.vlm1在OCRReasoning、charxiv等任务中表现稳健,体现了其处理结构化图像与数值逻辑的综合能力。
2. 数学物理类STEM推理(参考图2)
面对几何图形与面积计算题,模型不仅要具备物理量理解,还需推导出多个中间变量并完成多步几何推理。这类任务对公式推理链条与图形结构识别要求极高。dots.vlm1在AIME 2025、GPQA等数据集上成绩稳定,具备处理数学与物理交叉题目的能力,适用于教育和理科辅导场景。
3. 文物识别与跨模态知识调取(参考图3)
识别青铜器类型并结合历史知识判断选项,对模型的图像细节感知与知识调用能力都是挑战。dots.vlm1在charxiv、InfoVQA等任务中具备对低频名词与专业实体的理解能力,得益于其引入PDF、百科等结构化文本资源,适用于文化、博物、古籍等垂直领域。
4. 视觉推理样例(参考图4)
从图中文字排列“LOAD”中联想到“download”,这类Rebus谜题要求模型将视觉空间信息与语言表达方式做深度融合。dots.vlm1在MathVision等任务中具备较强的图文融合能力,能识别隐喻、拆词、符号等复合信息结构,具备较强的类人联想与理解能力。
模型架构介绍:
- 自研NaViT视觉编码器:完全从零训练,支持动态分辨率,结合纯视觉任务提升感知力;
- 多源多模态数据:除常见图文对外,还引入图表、公式、文档等结构化图像,并对网页/PDF等真实数据进行重构清洗;
- 三阶段训练流程:从视觉预训练、多模态预训练,到有监督微调,构建出兼具视觉精度与语言泛化的VLM系统。
整体来看,dots.vlm1不仅能胜任结构化图像理解与科学类推理任务,在知识稀疏、语言融合等更复杂的跨模态场景中也展现出较强竞争力。
感兴趣可戳→
GitHub:github.com/rednote-hilab/dots.vlm1
Hugging Face:huggingface.co/rednote-hilab/dots.vlm1.inst
Demo体验:huggingface.co/spaces/rednote-hilab/dots-vlm1-demo