[LG]《XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization》A Tomar, C Hooper, M Lee, H Xi... [UC Berkeley & FuriosaAI] (2025)
XQuant:突破LLM推理的内存瓶颈,创新KV Cache重计算技术
• 现状挑战:LLM推理受限于KV Cache巨大的内存占用和带宽需求,随着GPU计算能力远超内存带宽,传统KV Cache缓存方式成为性能瓶颈。
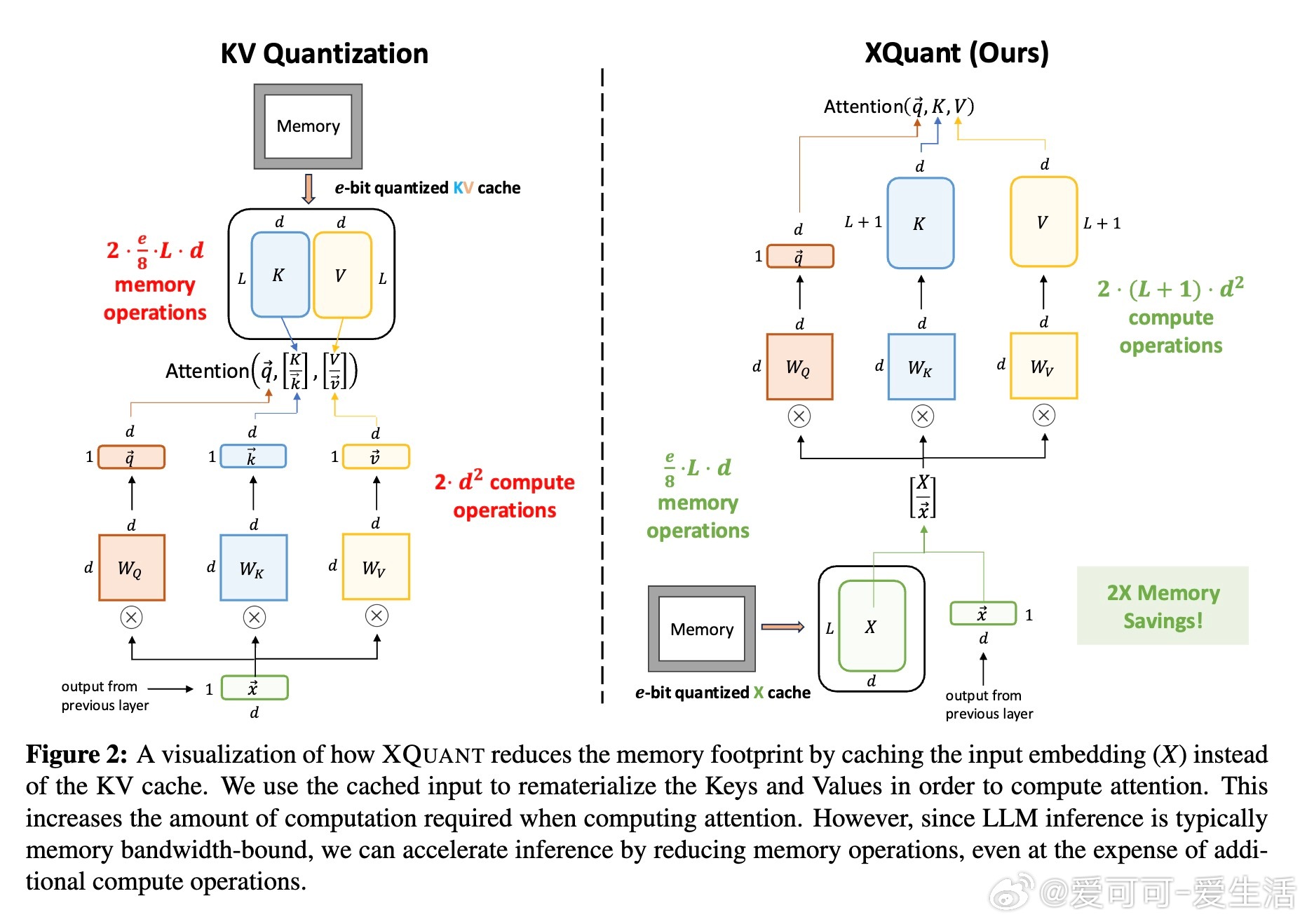
• 核心创新:XQuant不再缓存Keys和Values,而是对每层输入激活X进行低位量化并缓存,推理时动态重计算KV,内存使用量相比传统KV缓存降低约2倍。
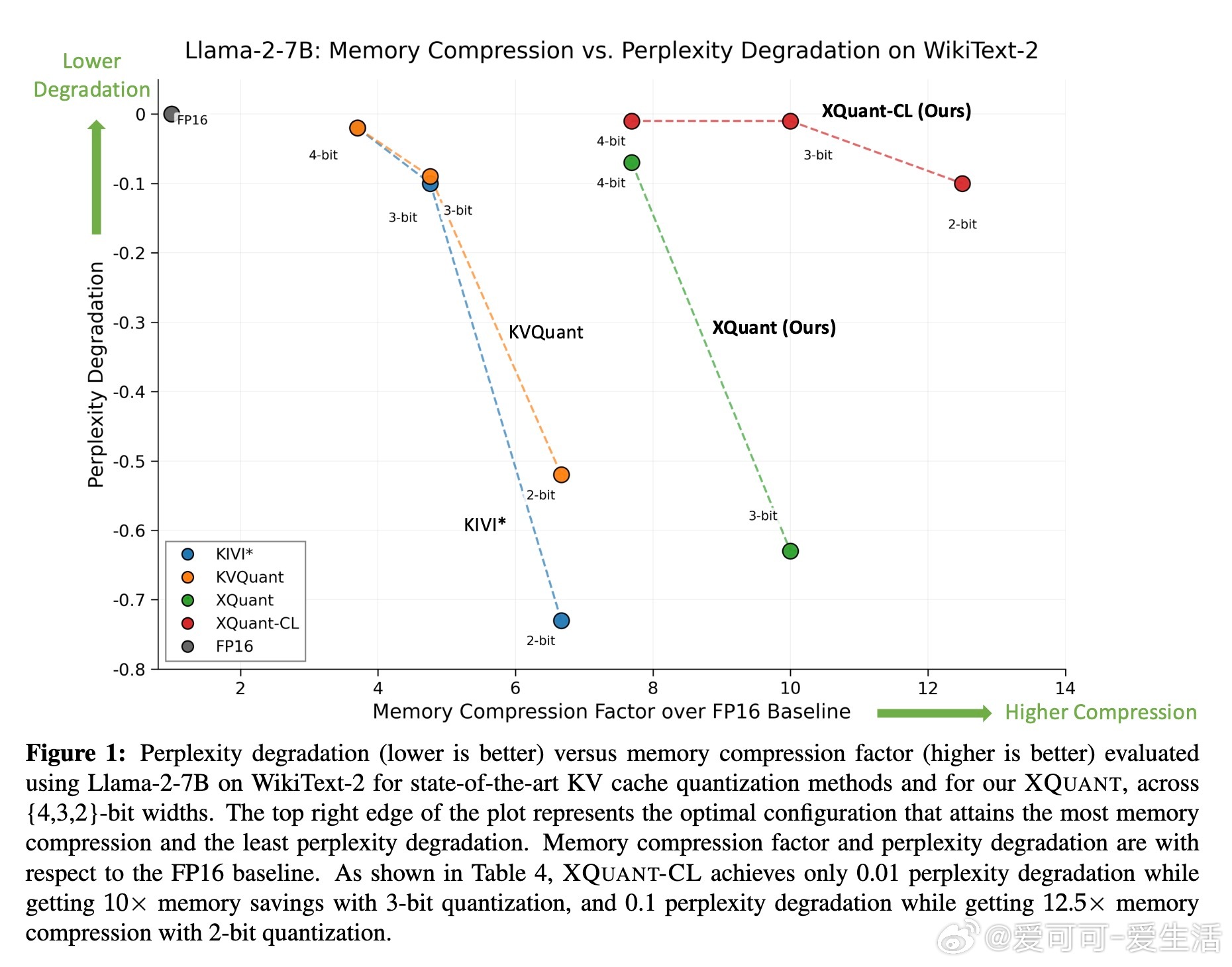
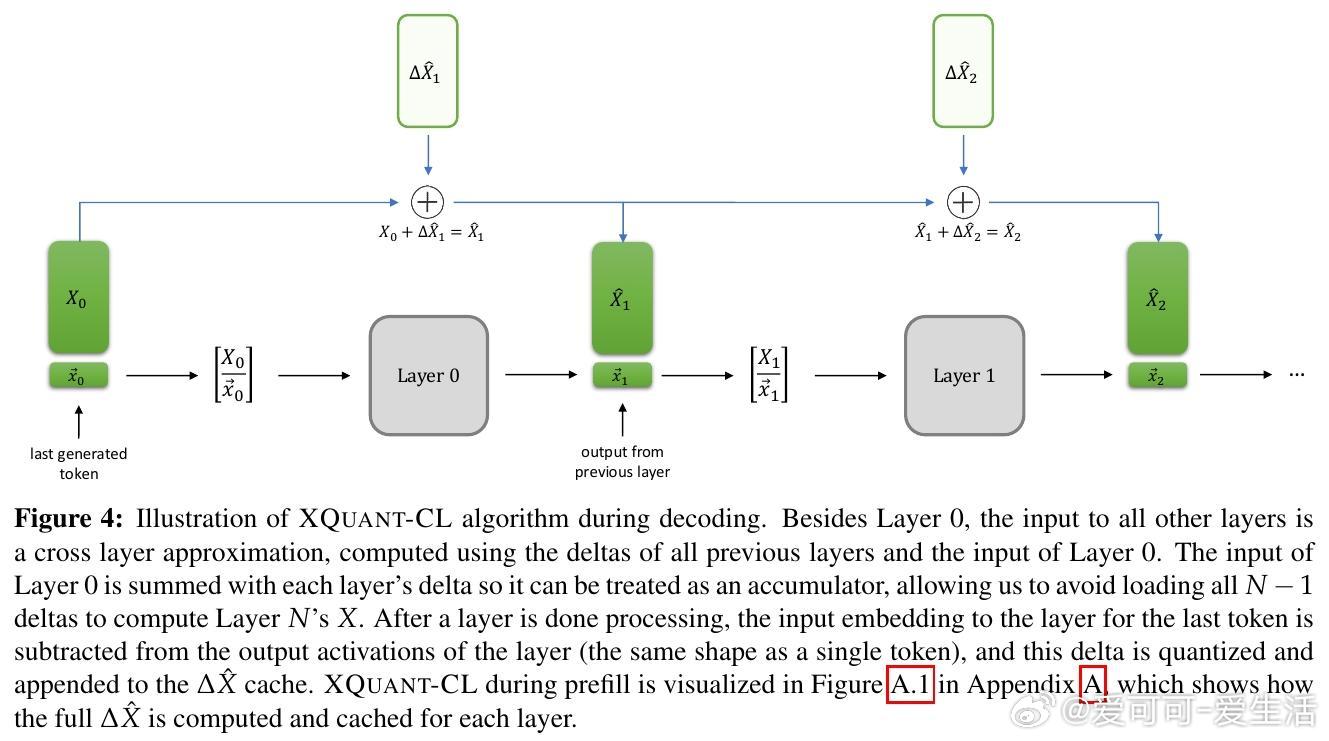
• 极致压缩:XQuant-CL利用Transformer残差流中层间输入激活X的高度相似性,压缩层间差异,实现10-12.5倍内存压缩,3-bit和2-bit量化下仅有极小困惑度(perplexity)损失(分别为0.01和0.1)。
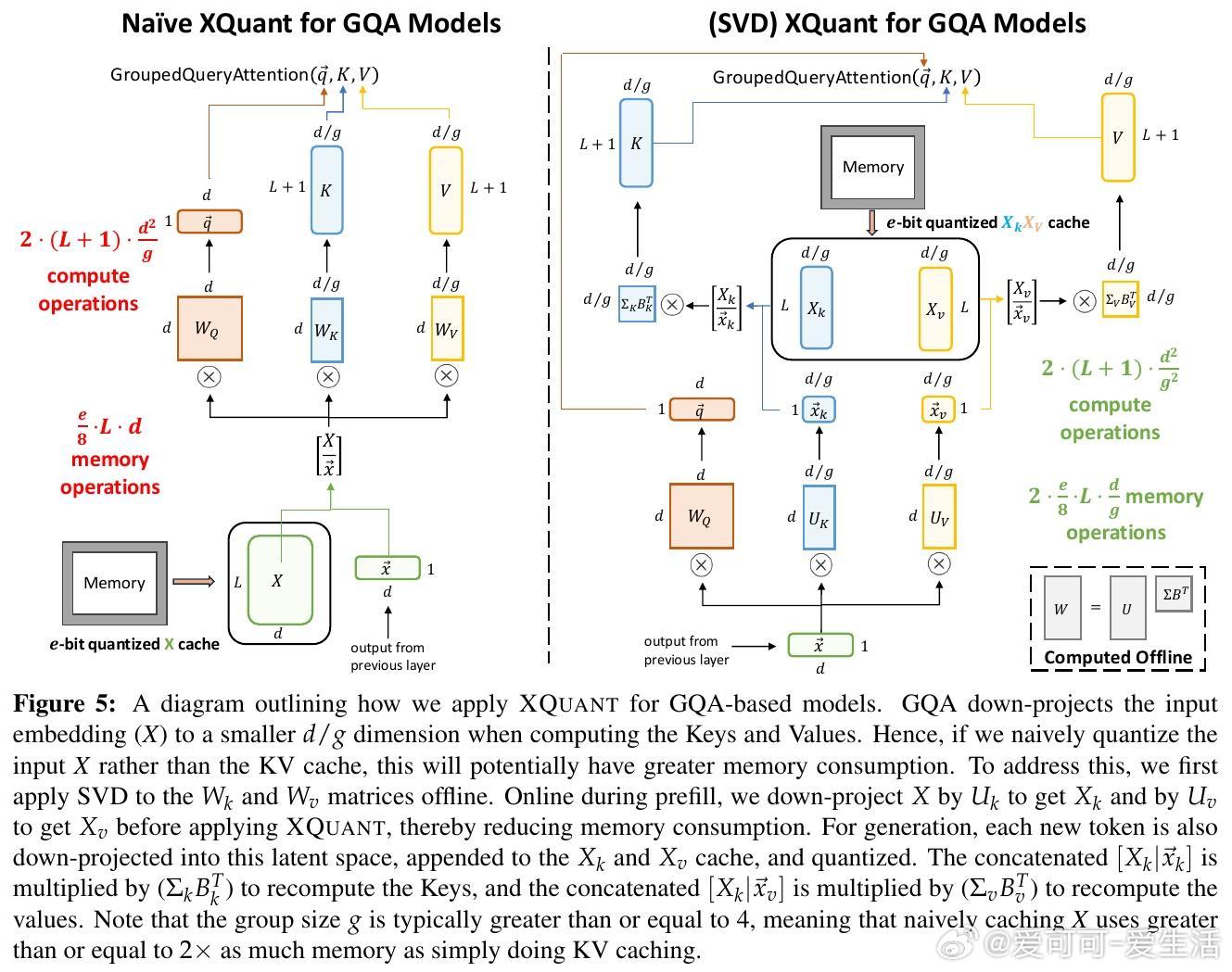
• 支持GQA:针对Grouped Query Attention结构,采用SVD分解权重矩阵,在线下降维输入激活X,量化潜在空间,保持内存优势同时提升量化准确度。
• 性能优势:在Llama-2、Llama-3.1和Mistral-7B等多模型和数据集上,XQuant与XQuant-CL在相同内存预算下,显著优于当前最先进KV Cache量化方法(如KVQuant和KIVI*),并保持近FP16精度。
• 计算权衡:XQuant通过额外计算换取大幅内存节省,符合未来硬件计算能力远超内存带宽的发展趋势,支持更长上下文推理且加速整体推理速度。
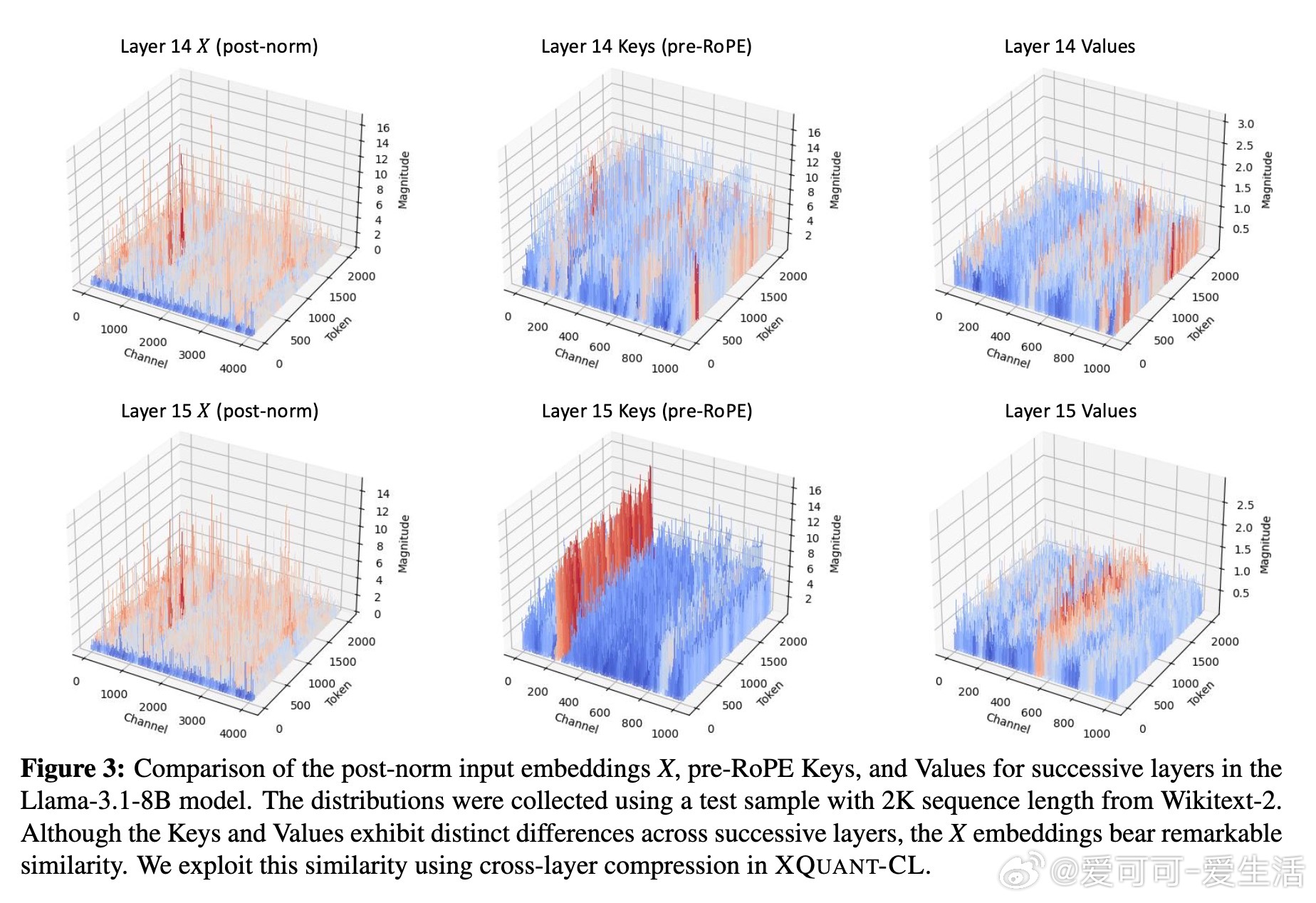
• 深层洞察:输入激活X的量化比KV Cache更易实现低位量化,且层间差异量化利用残差流特性达到极致压缩,揭示Transformer架构中信息演进的渐进性质。
• 下游验证:LongBench、GSM8K等长上下文及复杂推理任务评测显示,XQuant系列方法在多任务表现上匹配或优于基线,证明其实际应用价值。
XQuant代表了在存算不平衡背景下,利用计算资源突破内存限制的前瞻性思路,为大规模语言模型推理带来新的效率革命。
了解详情🔗arxiv.org/abs/2508.10395
大规模语言模型模型压缩量化推理加速内存优化Transformer