清华唐杰团队让大模型打牌大模型玩斗地主惯蛋
清华唐杰团队新论文:大语言模型(LLM)能不能像AlphaGo那样,玩复杂纸牌游戏?
团队挑了八个游戏,包括斗地主、掼蛋、麻将、德扑、UNO等,用高质量数据对模型进行微调,看它能不能学会这些规则复杂的卡牌。结论还挺有意思:
- 只要数据好,LLM确实能学会这些游戏,甚至打得不比传统AI差;
- 不同游戏一起学也没问题,像斗地主和掼蛋这种相似玩法还能互相参考;
- 但如果把麻将、UNO这种机制差很多的游戏混在一起训练,模型反而会“晕”;
- 学会打牌之后,模型在常规任务上的能力(比如数学、编程)会下降,但加点通用训练数据又能拉回来。
研究中最关键的一点,是LLM不需要为每个游戏设计专属架构,靠数据微调就能上手,这跟之前围棋AI需要定制网络不大一样。
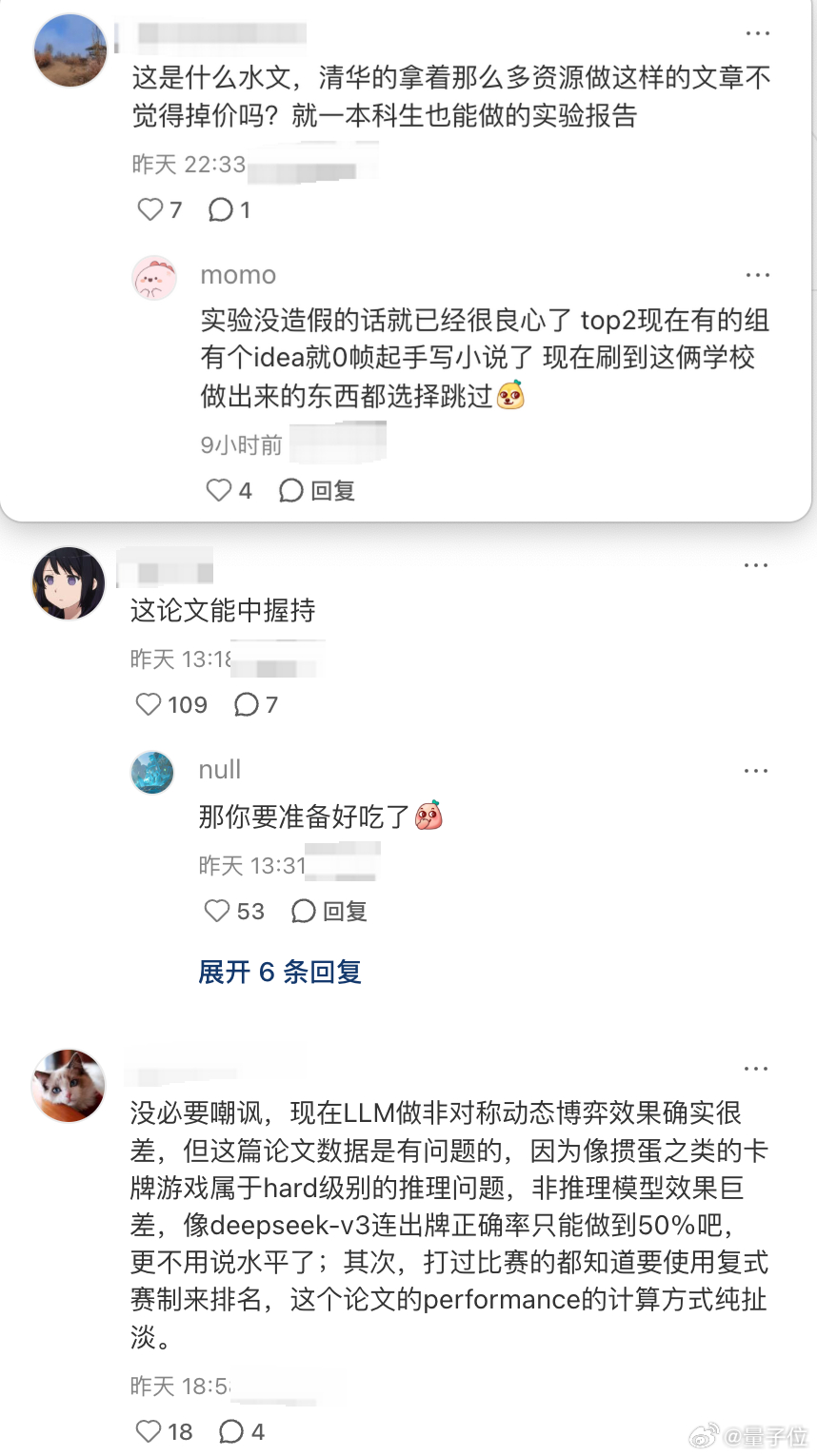
不过,这篇论文也引发了一些质疑。声音主要集中在论文含金量方面【图2】。
但不管怎么说,这篇论文展示了一种新的思路:LLM能否成为通用策略代理(general strategic agent),如果LLM连斗地主都能玩明白,也许未来能搞定更多复杂决策任务。
论文地址:arxiv.org/abs/2509.01328