[CL]《Causal Attention with Lookahead Keys》Z Song, P Sun, H Yuan, Q Gu [ByteDance Seed] (2025)
CAuSal aTtention with Lookahead kEys(CASTLE)革新了自回归序列建模的注意力机制,通过动态更新先前token的key,突破传统因果注意力只能编码过去信息的限制,实现更精准的全局上下文捕获,且严格保持自回归结构。
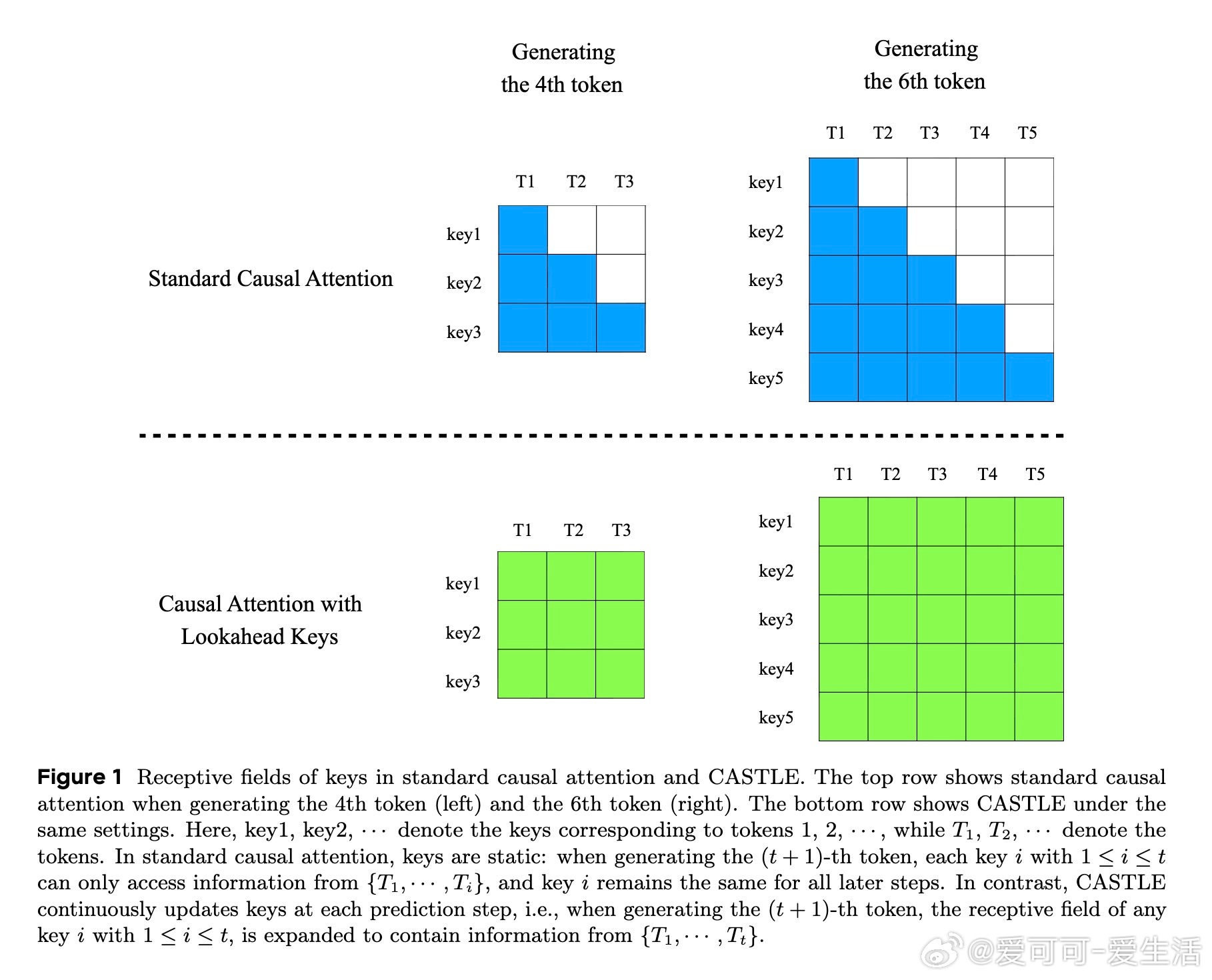
• 传统因果注意力中,query、key、value静态且仅编码先前上下文,限制了模型理解复杂句式(如garden-path句子)和捕获后续关键信息的能力。
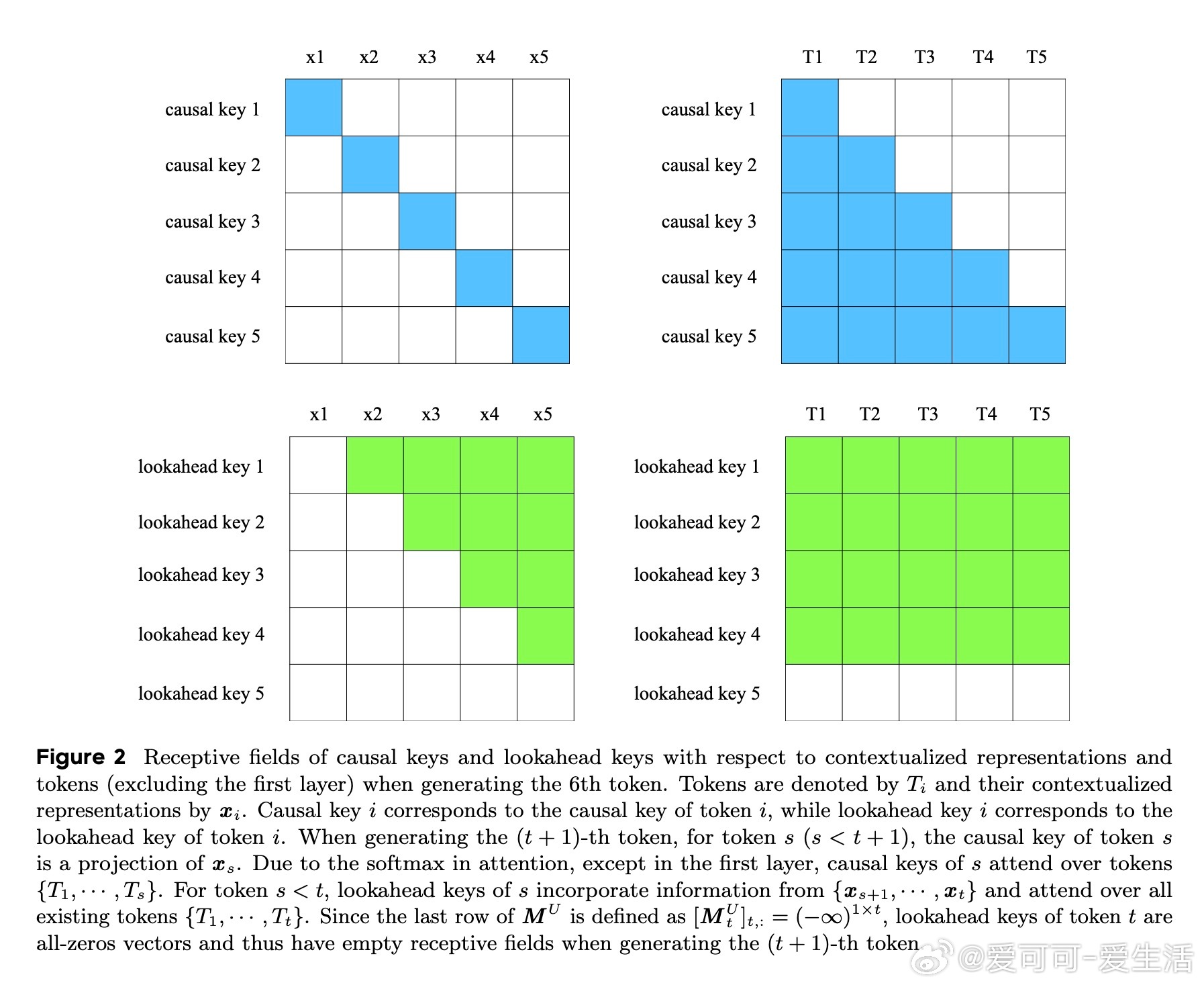
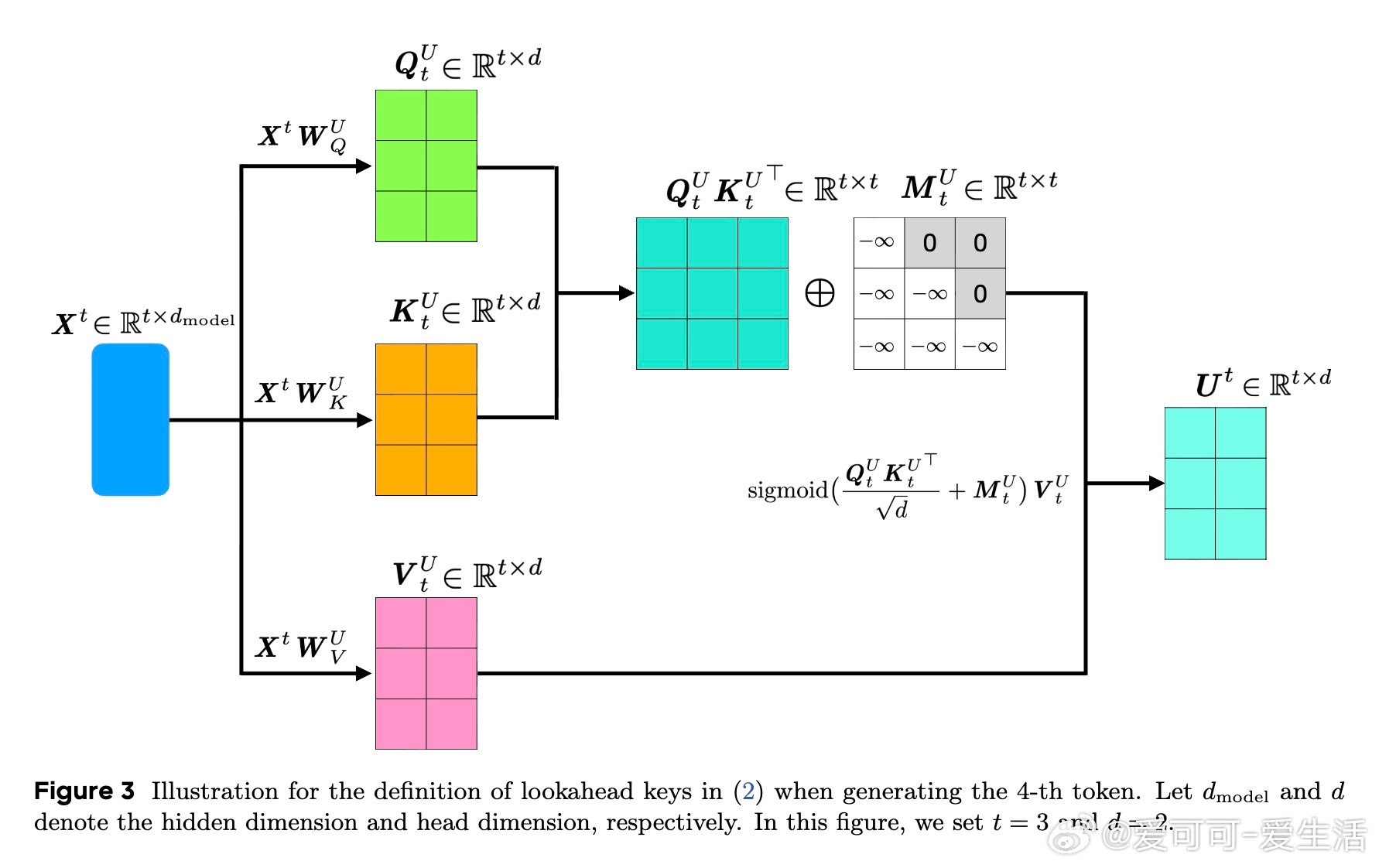
• CASTLE引入“lookahead keys”,在生成第(t+1)个token时,动态更新所有前序token的key,使其包含后续tokens的语义信息,极大提升了表示的全局感知能力。
• 设计巧妙地保持了自回归属性——更新的key仅利用已生成令牌,不访问未来未生成token,保障生成安全性。
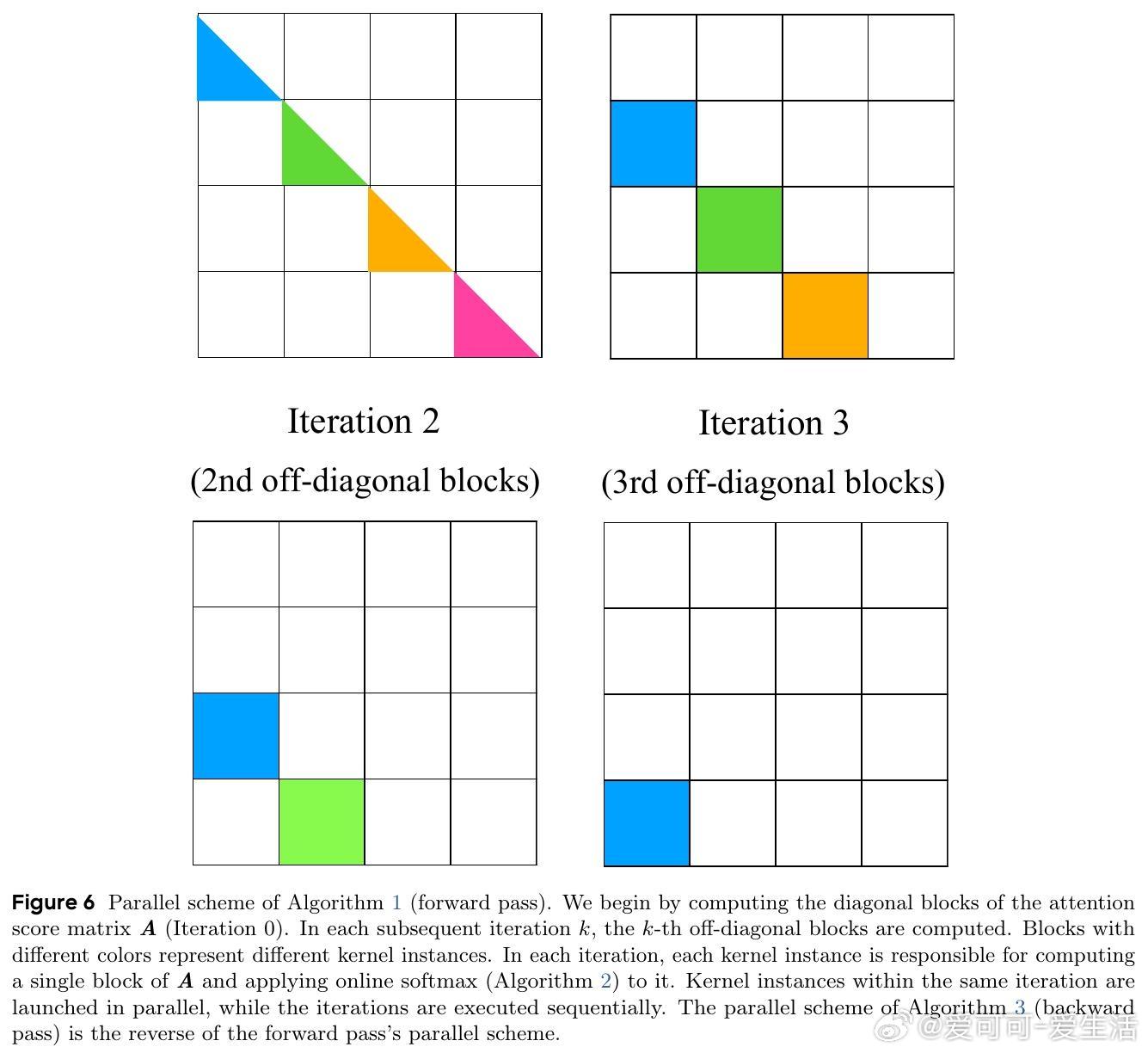
• 通过数学等价变换,避免了显式计算所有lookahead keys,支持高效并行训练,复杂度降至O(L²d),训练规模大幅提升。
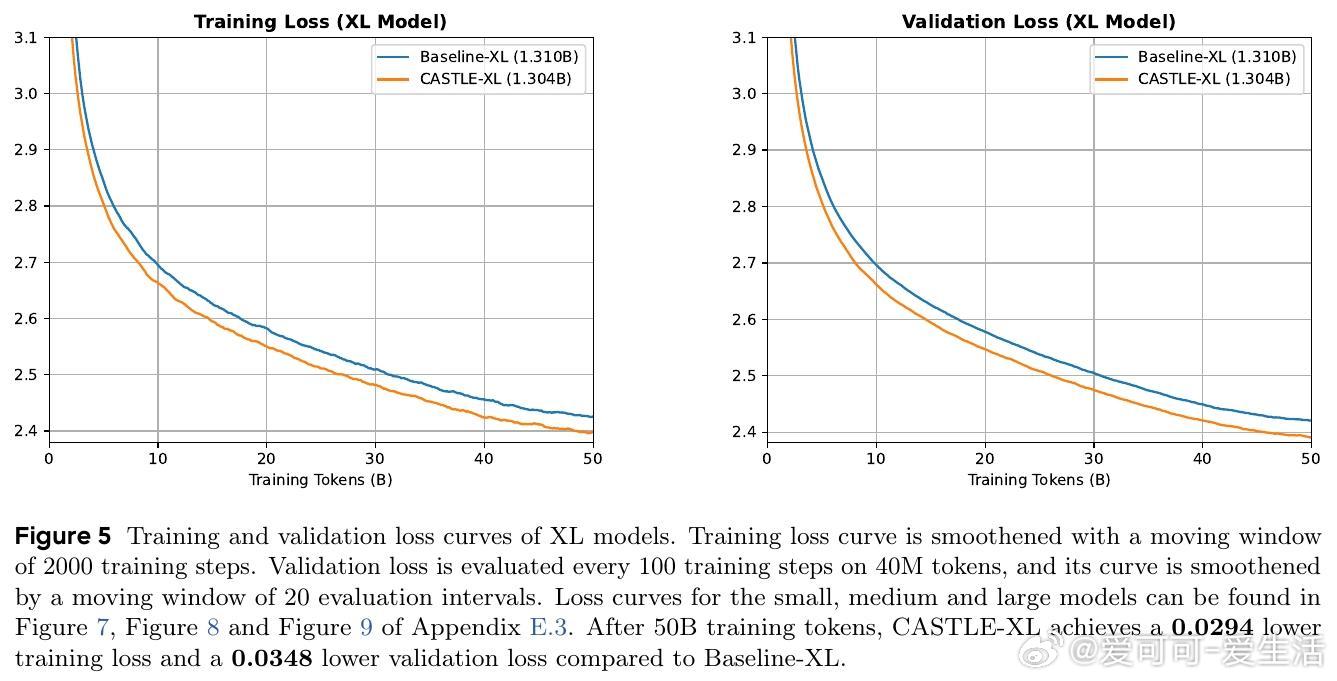
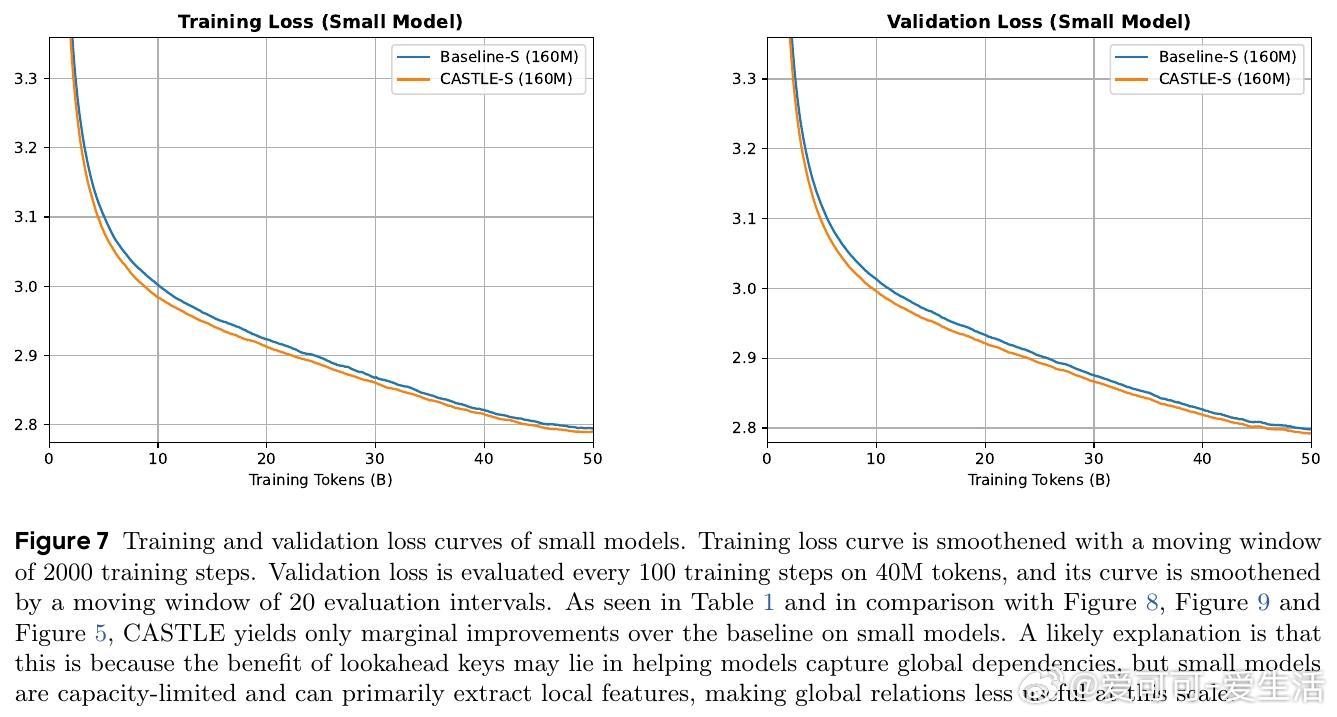
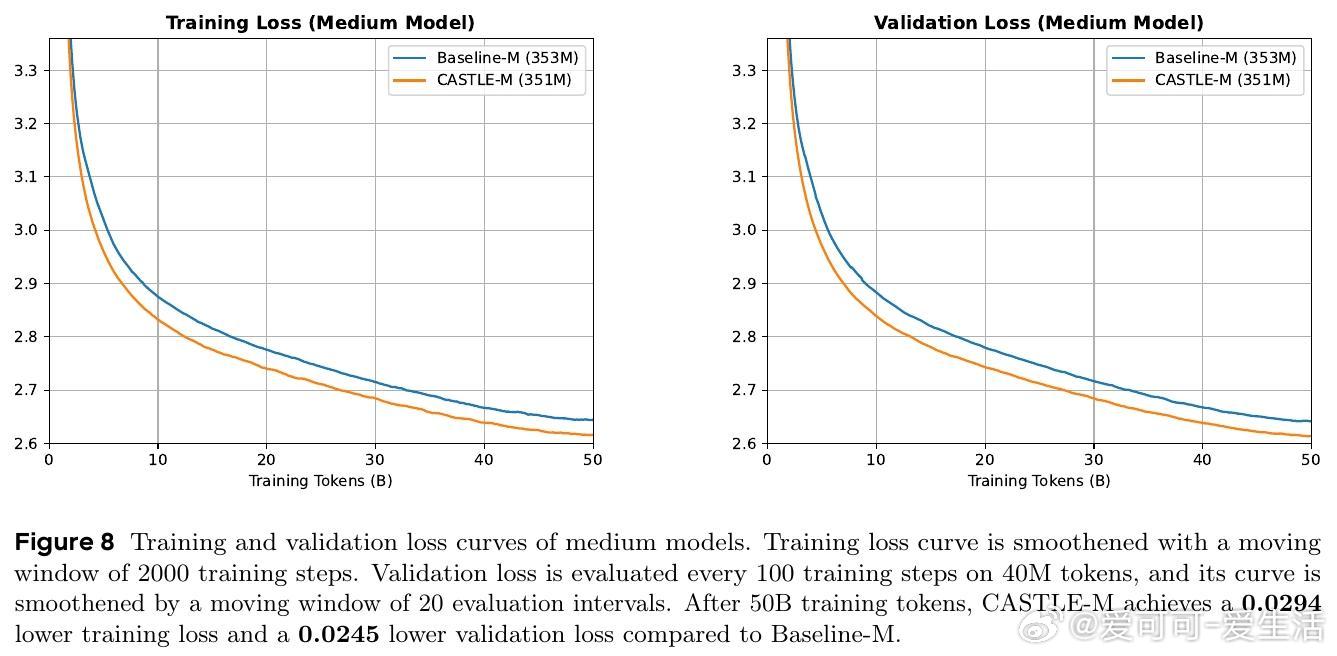
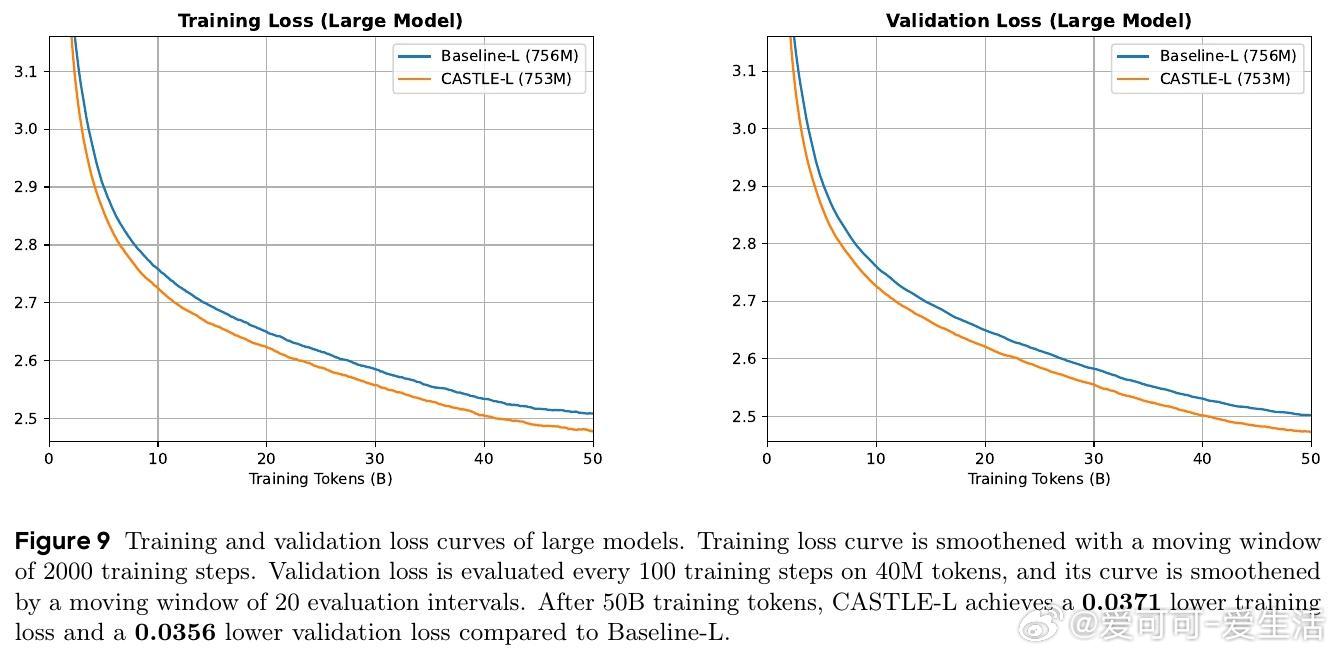
• 实验覆盖0.16B至1.3B参数规模,CASTLE在FineWeb-Edu数据集训练50B tokens后,验证困惑度均显著低于标准因果注意力,尤其在中大模型表现突出。
• 多项下游任务(ARC、BoolQ、HellaSwag、MMLU等)0-shot与5-shot评测中,CASTLE持续优于基线,显示更强的推理、常识和少样本泛化能力。
• 细致消融验证了混合设计的必要性(因果key与lookahead key共存)、SiLU激活函数的泛化贡献,以及性能提升非仅由key数量增加驱动。
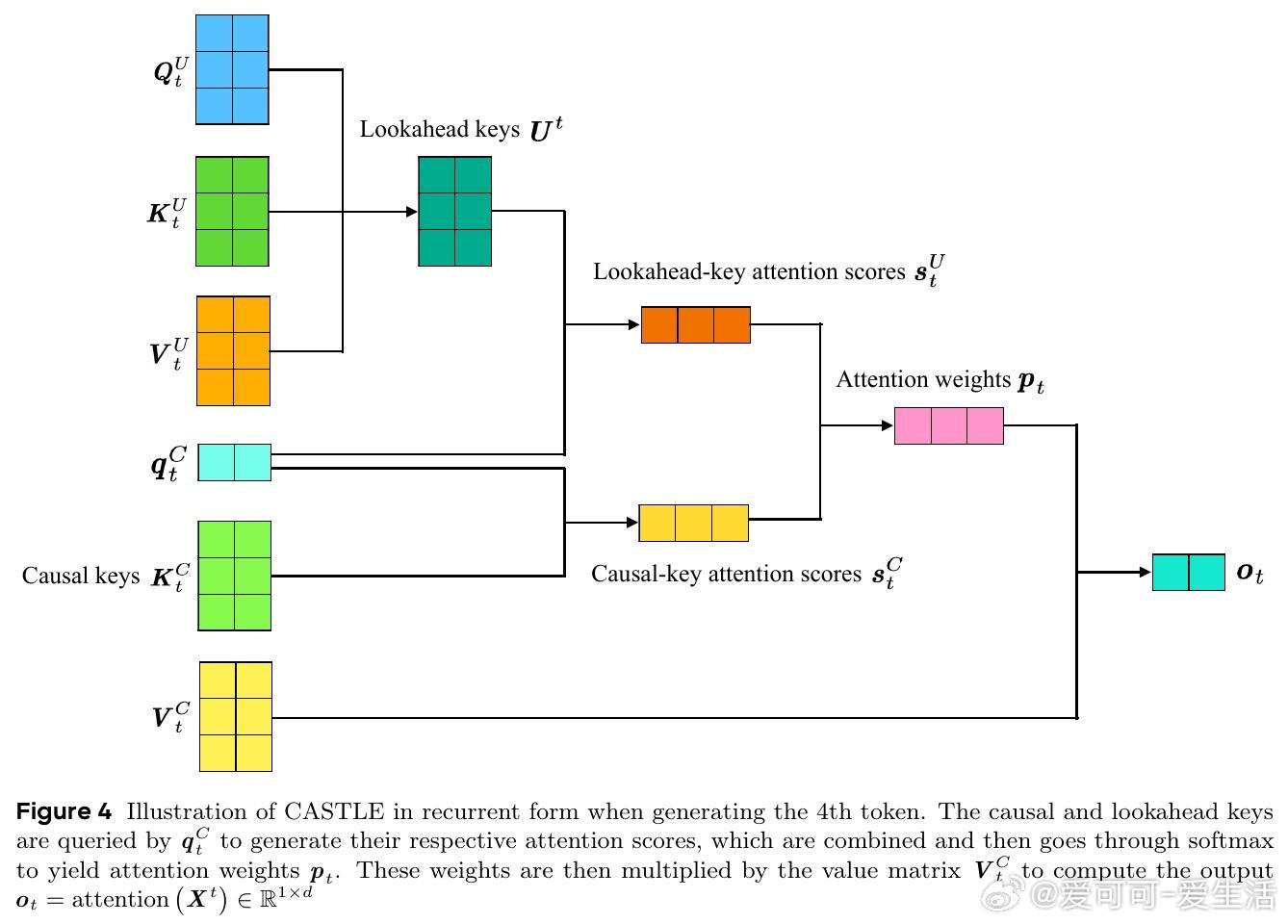
• 推理阶段引入UQ-KV缓存,结合递归公式实现高效解码,兼顾速度与性能。
心得:
1. 动态更新key的机制突破了传统因果注意力对未来信息的封闭性,赋予模型更灵活的上下文理解能力,尤其在结构复杂、语义依赖跨越长距离的语句中表现更优。
2. 保持自回归特性的同时有效利用未来信息,体现了对模型生成安全性与表达能力的平衡与创新。
3. 通过数学等价与高效并行算法设计,CASTLE成功解决了看似递归机制的训练效率瓶颈,展示了理论创新与工程实现的深度融合。
了解更多🔗arxiv.org/abs/2509.07301
人工智能自然语言处理注意力机制自回归模型深度学习大语言模型