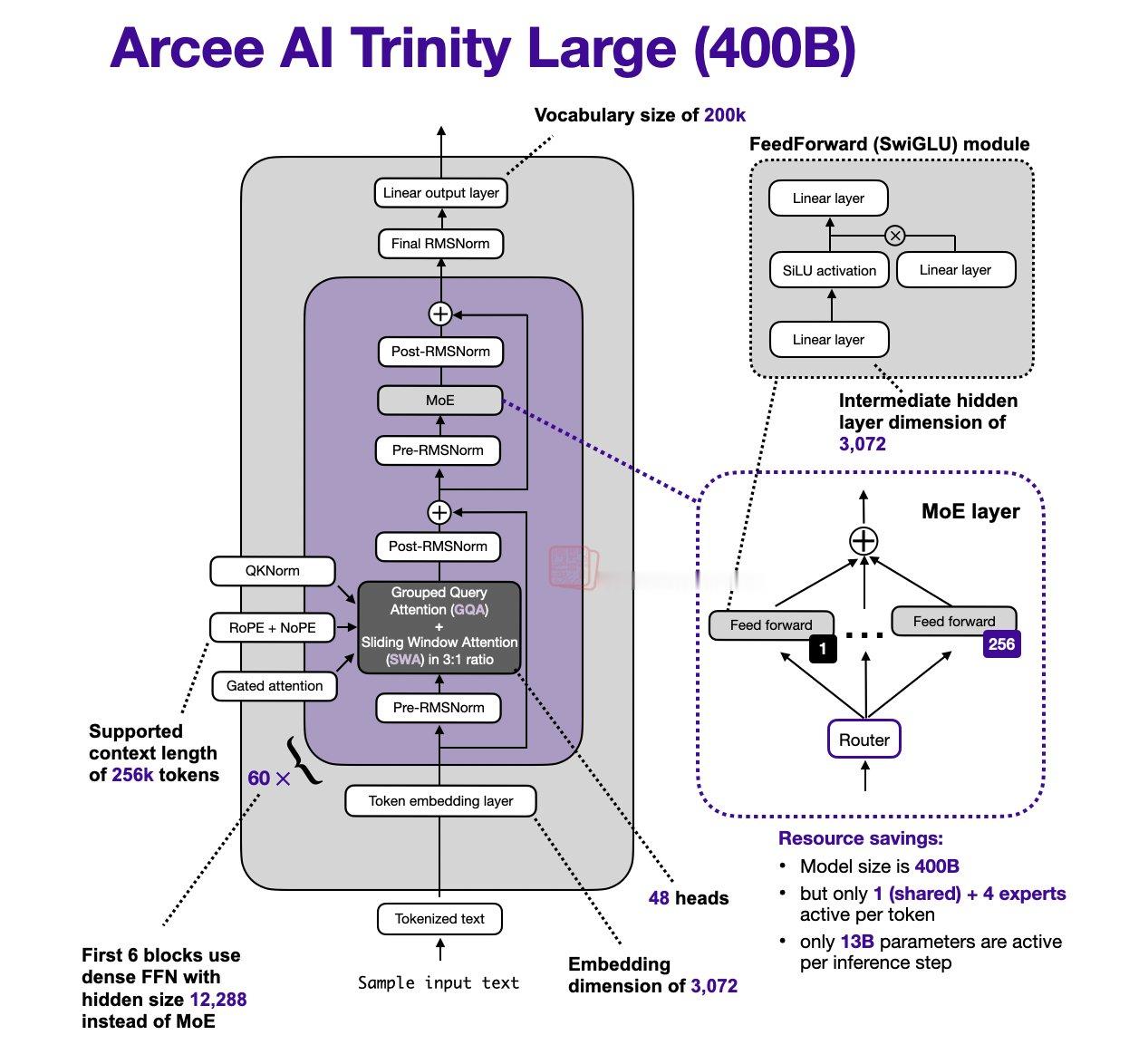
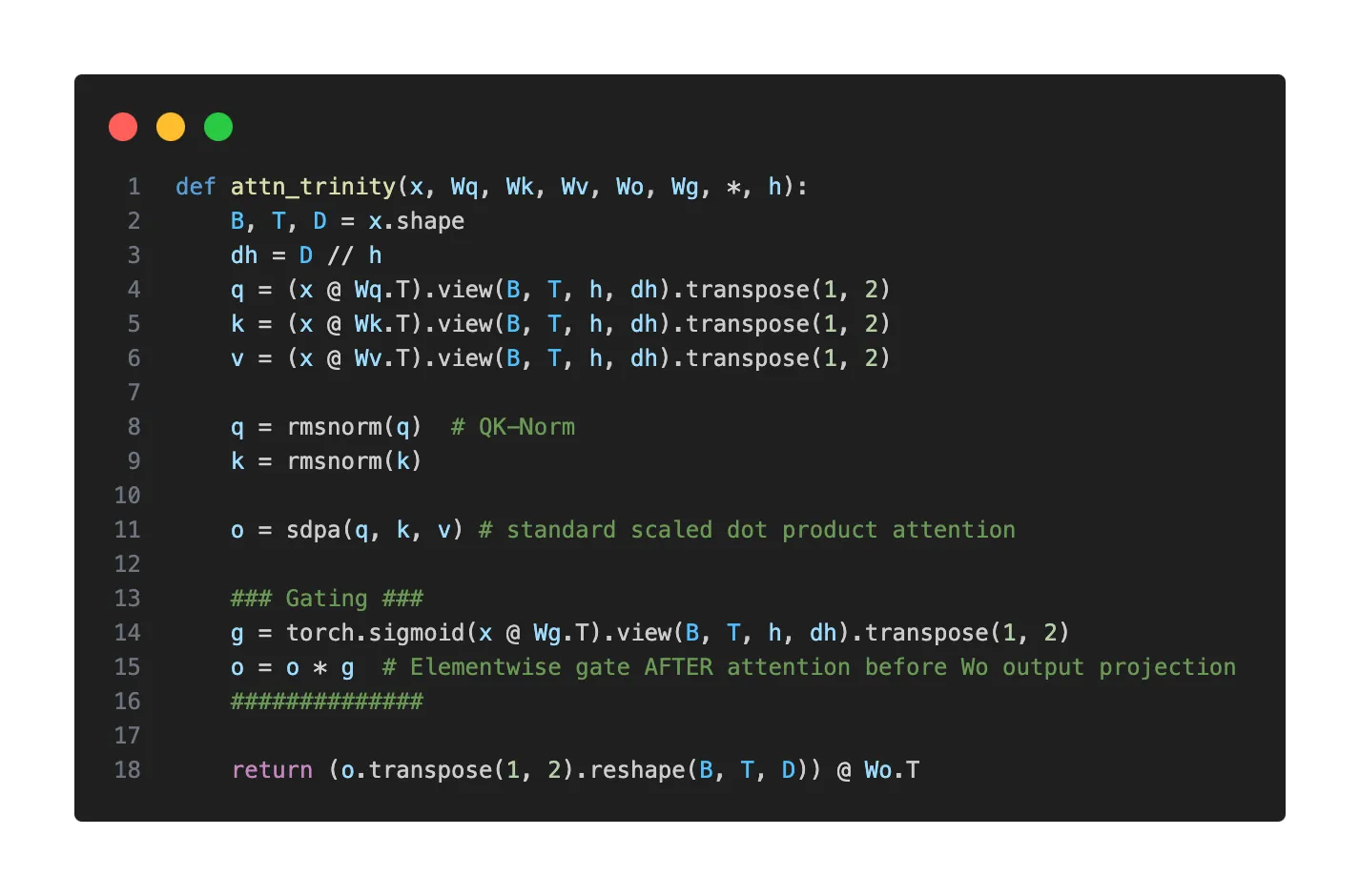
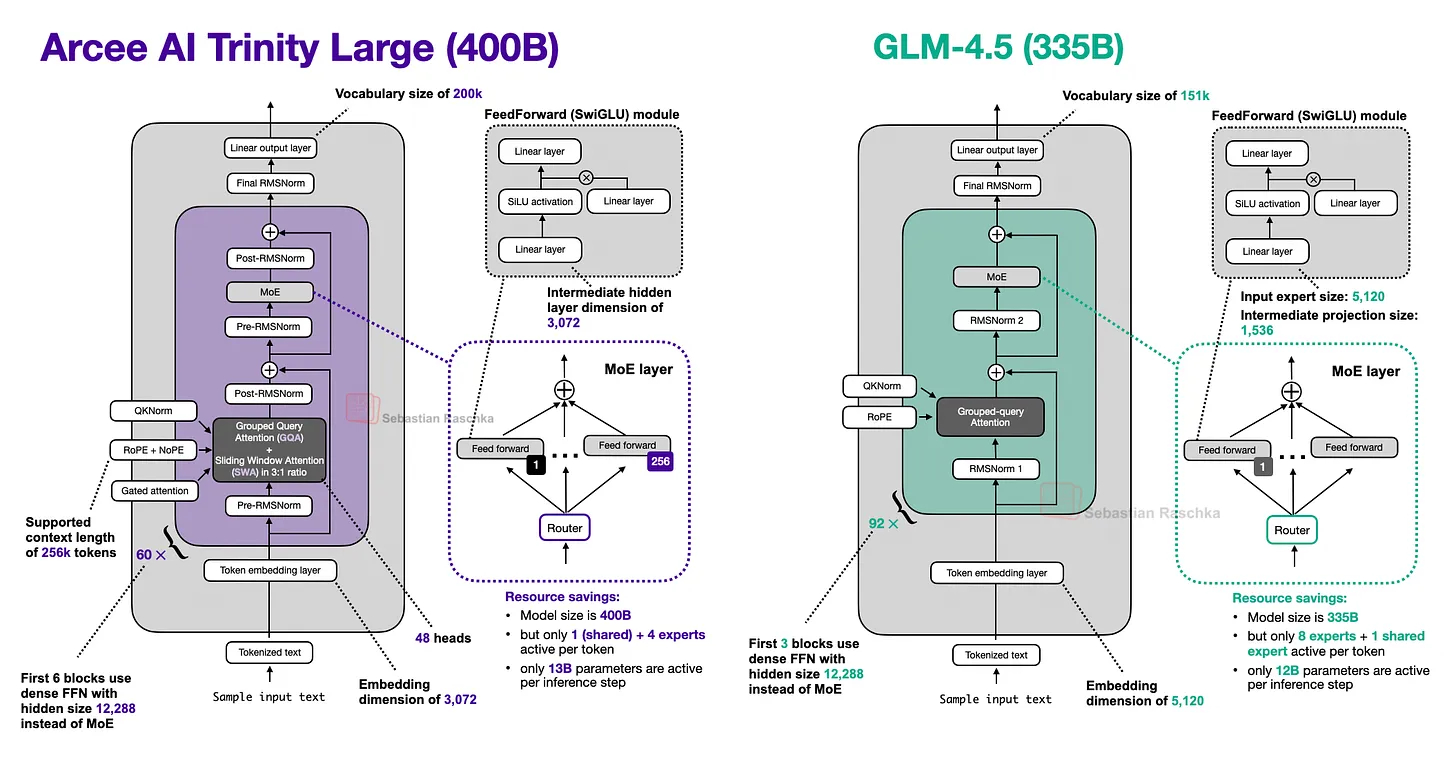
难得一见的美国开源模型:Arcee AI发布的 Trinity Large模型,参数400B,激活13B。用2000个 B300 GPU 训练(国内厂商投来羡慕的目光).----------------以下为Sebastian Raschka对其架构的驾照距离上一次 LLM 架构的更新已经有一段时间了。1 月 27 日,Arcee AI(一家此前我并未关注过的公司)开始在模型枢纽(Model Hub)上发布其 400B Trinity Large 开源权重系列模型,以及两个较小的变体版本。其旗舰级大模型是一个拥有 400B 参数的 MoE(混合专家)模型(其中激活参数为 13B)。两个较小的变体分别是 Trinity Mini(26B 参数,3B 激活参数)和 Trinity Nano(6B 参数,1B 激活参数)。图1:Trinity Large 架构概览。除了模型权重外,Arcee AI 还发布了一份细节丰富的技术报告。让我们深入了解一下这款 400B 的旗舰模型。下图将其与此前讨论过的 GLM 4.5(第 11 节)进行了对比,后者在规模上与之最为接近。此外,Trinity 的技术报告显示,Trinity Large 与 GLM-4.5 基础模型(Base model)的建模性能几乎完全一致(我推测他们没有与更近期的基础模型对比,是因为现在许多公司只分享微调后的模型)。图2:Arcee AI Trinity Large 与规模相近的 GLM 4.5 对比(400B vs 335B)。我们可以看到,Trinity 模型中加入了一些有趣的架构组件。首先,它采用了类似 Gemma 3、Olmo 3、小米 MiMo 等模型中出现的 局部/全局交替(滑动窗口)注意力层。但它并没有使用 Gemma 3 和小米常用的 5:1 比例,而是选择了与 Olmo 3 类似的 3:1 比例,且滑动窗口大小为 4096(也与 Olmo 3 相似)。除了 QK-Norm(在第 2 节 Olmo 2 中涵盖)之外,他们在全局层中使用了 NoPE(我们在第 7 节 SmolLM3 中讨论过)。他们还采用了一种形式的门控注意力(Gated Attention)。虽然不是完整的 GatedDeltaNet(见第 12 节),但使用了一种类似于 Qwen3-Next 注意力机制中的门控方式。具体来说,他们修改了标准注意力机制:在输出线性投影之前,对缩放点积(Scaled dot-product)结果添加了逐元素门控(Elementwise Gating)(如下图所示)。这种做法减少了注意力汇聚(Attention Sinks)现象,提升了长序列的泛化能力,并有助于增强训练稳定性。图3:Trinity Large 在注意力机制中所使用的门控机制示意图。你可能已经注意到,在之前的 Trinity Large 架构图中使用了四个(而非两个)RMSNorm 层。这就是所谓的 “深度缩放三明治归一化”(Depth-scaled sandwich norm)。虽然这是基于前人的研究,但在主流架构中我还从未见过。整体上看,它的 RMSNorm 布局类似于 Gemma 3,但不同之处在于,每个块中第二个 RMSNorm 的增益是随深度缩放的——这意味着其初始值约为 1/L(L 为总层数)。因此,在训练初期,残差更新量很小,并随着模型学习到正确的尺度而逐渐增大。其 MoE(混合专家系统) 采用了类似 DeepSeek 的结构,拥有大量的小型专家,但为了提高推理吞吐量,他们将其处理得更“粗粒度”一些(我们在 Mistral 3 Large 采用 DeepSeek V3 架构时也看到过类似做法)。HOW I AI