要做这样一个 AI 助手:能上网查资料、能读写文件、能记住过去的对话,还能在执行有风险的操作前先征询人类的意见。听起来是不是很复杂,其实并不是LangChain 生态里现成的几套工具,把开发时间压到了几个小时。不过这里就多了一个问题: create_agent、Deep Agents 和 LangGraph,该挑哪一个。
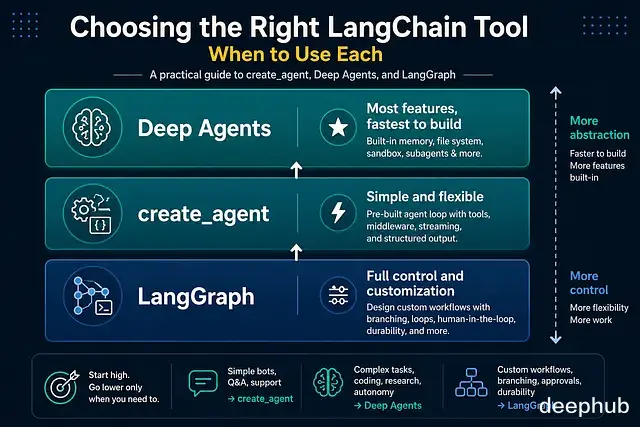
把它们看作不同抽象层级的工具更容易理解。LangGraph 在最底层,所有控制都掌握在开发者手里;create_agent 是预置好的 agent 循环,模型和工具一接就能跑;Deep Agents 在 create_agent 之上又加了一整套配套设施 —— 记忆、工具集、子 agent 编排都自带。
三者解决的是同一类问题。区别在于:层级越高,开发越快;层级越低,可调的地方越多。一个值得记住的原则:从最高的抽象起步,只有当上层确实满足不了需求时,再下沉到 LangGraph。
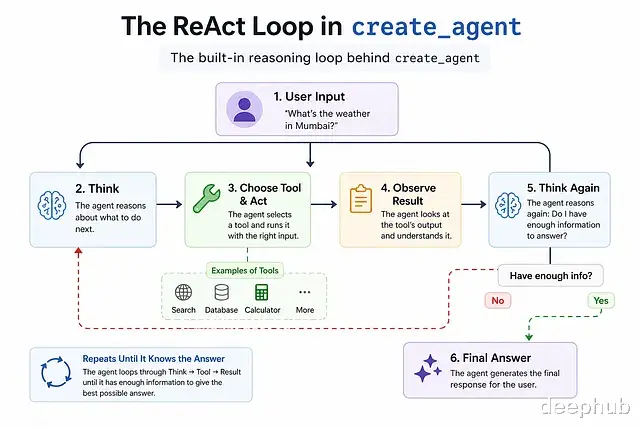
LangChain create_agentcreate_agent 是一个开箱即用的 agent。它在内部跑一个固定的循环——思考、选工具、执行、看结果、再思考,直到给出最终答案。这种范式叫 ReAct(Reasoning + Acting)。循环本身已经写好了,所以直接接入模型和工具即可。
最小可运行的例子长这样:
from langchain.agents import create_agentfrom langchain_core.tools import tool# 第一步:定义一个工具(就是普通的 Python 函数)@tooldef get_weather(city: str) -> str: """Get the current weather for a city.""" return f"It's 28°C and sunny in {city}!"# 第二步:创建 agentagent = create_agent( "anthropic:claude-sonnet-4-5", # 大脑 tools=[get_weather], # 双手)# 第三步:发问result = agent.invoke({ "messages": [{"role": "user", "content": "What's the weather in Mumbai?"}]})print(result["messages"][-1].content)# → "The weather in Mumbai is 28°C and sunny!"
整个过程里,agent 自己判断出该调用 get_weather,把参数传过去,拿到返回值后再写出一段自然的回复。循环逻辑一行都不用写。
放到稍微真实一点的场景——客户支持机器人——也是同样的写法:
from langchain.agents import create_agentfrom langchain_core.tools import tool@tooldef lookup_order(order_id: str) -> str: """Look up the status of an order.""" # 实际场景里这里会查数据库 orders = { "1234": "Shipped - arrives Friday", "5678": "Processing - ships tomorrow", } return orders.get(order_id, "Order not found")@tooldef check_return_policy() -> str: """Get the return policy.""" return "You can return any item within 30 days for a full refund."agent = create_agent( "openai:gpt-4o", tools=[lookup_order, check_return_policy], system_prompt="You are a friendly customer support agent. Always be polite.",)result = agent.invoke({ "messages": [{"role": "user", "content": "Where is my order #1234? And can I return it?"}]})# agent 会同时调用 lookup_order("1234") 和 check_return_policy(),把两个结果合起来回答
一次对话里调用多个工具、把多份结果拼起来回答,agent 自己会判断。
如果希望返回值不是一段自然语言而是固定结构的数据(比如一个带特定字段的 JSON),structured_output 能直接接管解析:
from pydantic import BaseModelclass SupportReply(BaseModel): answer: str # 实际回复 needs_human: bool # 是否需要转人工 category: str # "billing"、"shipping"、"returns"agent = create_agent( "anthropic:claude-sonnet-4-5", tools=[lookup_order, check_return_policy], structured_output=SupportReply, # 强制按这个 schema 输出)result = agent.invoke({"messages": [...]})reply = result["structured_output"]print(reply.needs_human) # True 或 Falseprint(reply.category) # "shipping"
正则、解析、字段抽取的逻辑都不用写。
那么什么场景适合用 create_agent?需求是单个 agent 调用工具——聊天机器人、问答系统、客服 bot 之类——基本都能覆盖;想要通过 middleware 加护栏、加日志、加限流,可以;需要流式输出或者结构化返回也可以。
如果需要分支判断的工作流——条件 A 走一条路,条件 B 走另一条路——create_agent 表达不了;多个 agent 之间互相协作也不行;需要在服务器重启后恢复执行的持久化场景不行;让 agent 真的去读写本地文件、在沙箱里跑代码,也不行。
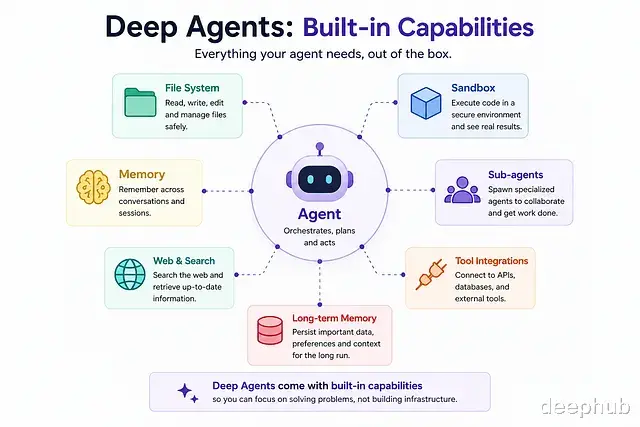
Deep AgentsDeep Agents 可以理解成预先装备好的 create_agent。它由 LangChain 在 create_agent 和 LangGraph 之上构建,自带一整套基础设施:虚拟文件系统、代码沙箱、子 agent 派生机制、跨会话的长期记忆,以及对 MCP/ACP/A2A 协议的支持。甚至还内置了一个类似终端版 GitHub Copilot 的 CLI 编码助手。
最简形态写法跟 create_agent 几乎一样:
from deepagents import create_deep_agentdef search_web(query: str) -> str: """Search the web for information.""" return f"Top results for '{query}': ..."agent = create_deep_agent( model="anthropic:claude-sonnet-4-5", tools=[search_web], system_prompt="You are a helpful research assistant.",)result = agent.invoke({ "messages": [{"role": "user", "content": "Research LangGraph and write a summary."}]})
差别在底层——这个 agent 已经能用文件系统、记忆、子 agent 这些工具,而不需要开发者额外注册任何东西。
放到更复杂的任务上,差距就拉开了。下面是一个能写代码、能跑代码、能自己审代码的 agent:
from deepagents import create_deep_agentfrom deepagents.tools import FileSystemTool, SandboxToolagent = create_deep_agent( model="openai:gpt-4o", tools=[ FileSystemTool(), # 读写真实文件 SandboxTool(), # 在隔离环境里跑 Python ], system_prompt="""You are a senior software engineer. When writing code: 1. Write the code to a file 2. Run it in the sandbox to test it 3. Spawn a reviewer sub-agent to critique it 4. Fix any issues found 5. Return the final version""", enable_subagents=True, # 允许派生子 agent memory_enabled=True, # 记住该用户的偏好)result = agent.invoke({ "messages": [{ "role": "user", "content": "Write a Python script that scrapes news headlines and saves them to a CSV." }]})
执行起来是这样:agent 把脚本写到 headlines_scraper.py,在沙箱里跑一遍验证,再派一个子 agent 去审查代码里的 bug 和安全问题,拿到反馈后自己改,最后把审查过的版本交回来。整个 1 到 4 步都不需要开发者写,Deep Agents 自己编排完了。
跨会话记忆是另一项实用能力:
# 第一次对话agent.invoke({"messages": [{"role": "user", "content": "I prefer Python over JavaScript."}]})# 几天之后,新的会话agent.invoke({"messages": [{"role": "user", "content": "Write me a web scraper."}]})# agent 记得这位用户偏好 Python,自然就写 Python 而不是 JavaScript
create_agent 在两次会话之间什么都不记得;Deep Agents 会留住这些信息。
它适合的场景集中在长链路、多步骤的复杂任务——编码助手、研究助手、自主 agent 这类——以及需要文件读写、代码执行、agent 之间相互调度的场合。如果还要多租户、RBAC 这些生产级能力,自己造太累,Deep Agents 直也可以直接用。
但是如果需要 Deep Agents 那套预设之外的、非常规的控制流;只是写一个单轮聊天机器人(配一架机器人用一辆挖掘机);或者想看清底层每一步发生了什么——那种情况下,直接用 LangGraph 更合适。
LangGraphLangGraph 是底层的引擎。create_agent 和 Deep Agents 内部跑的就是 LangGraph,只不过把图的接线藏起来了。当上层框架的预设挡了路,就是直接用 LangGraph 的时候。
它的核心抽象是图。节点是函数,代表一步操作;边连接节点,决定下一步走向;状态是在所有节点之间传递的共享数据。整体的心智模型可以画成:
START → [步骤 A] → [步骤 B] → [步骤 C] → END ↓ [步骤 D] ← 条件分支
每个方框是节点,每个箭头是边,全都由开发者自己定义。最简单的图只做一件事:
from langgraph.graph import StateGraph, MessagesState, START, END# 节点就是普通的 Python 函数def say_hello(state: MessagesState): return {"messages": [{"role": "ai", "content": "Hello, world!"}]}# 构建图graph = StateGraph(MessagesState)graph.add_node("say_hello", say_hello) # 注册节点graph.add_edge(START, "say_hello") # 连边:开始 → say_hellograph.add_edge("say_hello", END) # 连边:say_hello → 结束app = graph.compile()result = app.invoke({"messages": []})# → {"messages": [AIMessage("Hello, world!")]}
实际意义不大,但它把基本骨架交代清楚了。
换个真实场景,文档审查工作流。流程是:收到文档 → 判定是否合规 → 合规走批准路径,不合规走拒绝路径 → 发送对应的回复。这种带分支的过程是 create_agent 表达不了的,但是到了 LangGraph 就很简单:
from langgraph.graph import StateGraph, MessagesState, START, ENDfrom langchain_anthropic import ChatAnthropicllm = ChatAnthropic(model="claude-sonnet-4-5")# 节点 1:对文档分类defify_document(state: MessagesState): response = llm.invoke([ {"role": "system", "content": "Reply ONLY with 'compliant' or 'non-compliant'."}, *state["messages"] ]) return {"messages": [response]}# 节点 2a:批准路径def approve(state: MessagesState): return {"messages": [{"role": "ai", "content": "Document approved. Filing now."}]}# 节点 2b:拒绝路径def reject(state: MessagesState): return {"messages": [{"role": "ai", "content": "Document rejected. Notifying author."}]}# 路由函数:决定走哪条分支def route_decision(state: MessagesState) -> str: last_message = state["messages"][-1].content.lower() if "compliant" in last_message: return "approve" else: return "reject"# 把这些都接起来graph = StateGraph(MessagesState)graph.add_node("classify",ify_document)graph.add_node("approve", approve)graph.add_node("reject", reject)graph.add_edge(START, "classify")graph.add_conditional_edges( "classify", # 走完这个节点之后…… route_decision, # 调用这个函数判断方向…… {"approve": "approve", "reject": "reject"} # 把判断结果映射到下一节点)graph.add_edge("approve", END)graph.add_edge("reject", END)app = graph.compile()result = app.invoke({"messages": [ {"role": "user", "content": "Please review: This contract follows all GDPR rules."}]})
LangGraph 还有一项很实用的能力:human-in-the-loop。图可以在运行到某个节点时停下来等人。
from langgraph.checkpoint.memory import MemorySaverfrom langgraph.types import interruptdef human_approval(state: MessagesState): """这个节点会暂停,等待人类输入。""" # interrupt() 在这里中断执行,并把状态全部保存下来 human_decision = interrupt({ "message": "Should I approve this document?", "document": state["messages"][-1].content, }) # 人类响应之后,从这里恢复 return {"messages": [{"role": "ai", "content": f"Human decided: {human_decision}"}]}# 编译时挂上 checkpointer,暂停状态才会保存下来app = graph.compile(checkpointer=MemorySaver())thread_id = {"configurable": {"thread_id": "review-session-1"}}# 运行直到 interrupt——图在 human_approval 处暂停for event in app.stream(input_data, thread_id): print("Processing:", event)# ... 图在这里暂停 ...# -- 几小时后,人类作出回应 --# 用人类的决定恢复执行from langgraph.types import Commandapp.invoke(Command(resume="approved"), config=thread_id)# 图从暂停的位置继续往下走
状态会落到 checkpointer 里,生产环境可以换成数据库支撑。暂停的时长不受限制——几分钟、几小时、几天都行。
时间旅行是另一项调试利器。一次运行的所有 checkpoint 都被记录下来,可以回到任意一步重跑:
# 查看一次运行的完整历史history = list(app.get_state_history(thread_id))# 第 0 步:START# 第 1 步:classify 跑完之后# 第 2 步:human_approval 跑完之后# 第 3 步:approve 跑完之后(终点)# 对结果不满意?回到第 1 步,换一份输入再跑一次old_checkpoint = history[1].configresult = app.invoke( {"messages": [{"role": "user", "content": "Actually,ify this more strictly."}]}, config=old_checkpoint # 从第 1 步重启)# 用新输入从第 1 步往后跑,第 0 步保持不动
像是给 agent 的执行加了一个 Git——任意分支、回退、重放。
LangGraph 的适用场景是:需要分支判断、需要循环重试、需要并行、需要人在工作流中途介入、需要服务器崩溃后恢复执行、需要回放调试,以及需要自己设计的复杂多 agent 拓扑。反过来,如果只是要一个调用工具的聊天 agent,直接用 create_agent;如果要文件系统、沙箱、子 agent 那一套,Deep Agents 已经做好了;新手如果没有特别明确的定制流需求,从 create_agent 起步就够了。
如何选择判断从哪一层下手,只需要先问一个问题:需不需要定制控制流。
定制控制流指的是基于条件的分支、并行步骤、循环、运行中途等待人类、或者重放执行。答案是"不需要",直接走更高的抽象层;答案是"需要",直接用 LangGraph。
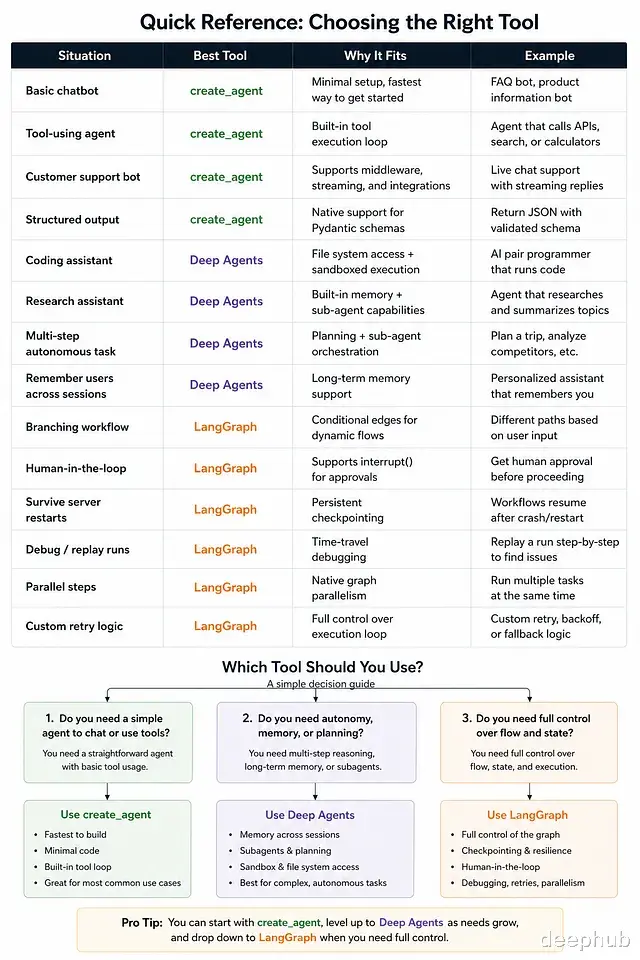
把场景一一对应,大致是这样一棵决策树:
简单的聊天机器人或问答 bot → create_agent,快、简单,正合适
调用 API 或数据库的客服 agent → create_agent,工具加 middleware 已经够用
跨会话记住用户的 agent → Deep Agents,长期记忆是内置的
要读写文件、跑代码的 agent → Deep Agents,FileSystemTool 加 SandboxTool 直接给
编码助手或研究助手 → Deep Agents 就是为这个场景设计的
多个 agent 自动协同 → Deep Agents,子 agent 是原生概念
带 IF/ELSE 分支的工作流 → LangGraph,用 conditional edges
中途要人类批准的流程 → LangGraph,interrupt 加 checkpointer
需要在重启后继续的长任务 → LangGraph 的持久化执行
复杂的自定义架构(并行、重试循环之类)→ LangGraph,完全可控
同一个任务,三种写法把同一个任务拿出来——"用一个搜索工具回答问题"——分别用三种框架实现一遍,各自隐藏了多少东西就看得清清楚楚。
Deep Agents 的版本:
from deepagents import create_deep_agentdef search(query: str) -> str: """Search the internet.""" return f"Search results for: {query}"agent = create_deep_agent( model="anthropic:claude-sonnet-4-5", tools=[search],)result = agent.invoke({ "messages": [{"role": "user", "content": "What is LangGraph?"}]})print(result["messages"][-1].content)
create_agent 的版本,大约 12 行:
from langchain.agents import create_agentfrom langchain_core.tools import tool@tooldef search(query: str) -> str: """Search the internet.""" return f"Search results for: {query}"agent = create_agent( "anthropic:claude-sonnet-4-5", tools=[search],)result = agent.invoke({ "messages": [{"role": "user", "content": "What is LangGraph?"}]})print(result["messages"][-1].content)
LangGraph 的版本,大约 35 行:
from langgraph.graph import StateGraph, MessagesState, START, ENDfrom langgraph.prebuilt import ToolNodefrom langchain_anthropic import ChatAnthropicfrom langchain_core.tools import tool@tooldef search(query: str) -> str: """Search the internet.""" return f"Search results for: {query}"# 把工具绑定到模型上llm = ChatAnthropic(model="claude-sonnet-4-5").bind_tools([search])# 调用模型的节点def call_model(state: MessagesState): response = llm.invoke(state["messages"]) return {"messages": [response]}# 决定下一步:用工具还是结束?def should_continue(state: MessagesState) -> str: last_message = state["messages"][-1] return "tools" if last_message.tool_calls else END# 手动构建图graph = StateGraph(MessagesState)graph.add_node("model", call_model)graph.add_node("tools", ToolNode([search]))graph.add_edge(START, "model")graph.add_conditional_edges("model", should_continue)graph.add_edge("tools", "model") # 循环:工具跑完 → 回到模型app = graph.compile()result = app.invoke({ "messages": [{"role": "user", "content": "What is LangGraph?"}]})print(result["messages"][-1].content)
三段代码跑出来的答案一样。create_agent 和 Deep Agents 在底下做的就是 LangGraph 版本里那些事——只是把图的接线藏起来了。只有当你想去 改 那段接线时,才真正需要写 LangGraph 版本。
几个新手容易踩的坑第一个坑是上来就用 LangGraph。它强大但代码量大,很多人觉得它"看起来更专业"就直接选了。如果没有明确的定制流需求,大量精力会花在写 create_agent 一行就能完成的样板代码上。默认从 create_agent 起步,撞墙再升级。
第二个坑是用 Deep Agents 写一个简单的聊天机器人。Deep Agents 本身没问题,问题在于一个基础问答 bot 用不上它带的文件系统、子 agent、记忆这些东西,反而把整体复杂度拉高。简单的工具调用 agent,create_agent 又快又轻。
第三个坑——把 LangGraph 当成 create_agent 的对立面。它们不是竞争关系,是同一个栈的不同层。create_agent 内部用的是 LangGraph;Deep Agents 两者都用。把这三个东西看作叠加的层,而不是并列的选项,后面很多决策会清晰很多。
第四个坑出现在 human-in-the-loop 上:用了 interrupt() 但忘了挂 checkpointer。图一暂停,状态就没了。
# 错误写法——暂停时状态丢失app = graph.compile()# 正确写法——暂停时状态保留from langgraph.checkpoint.memory import MemorySaverapp = graph.compile(checkpointer=MemorySaver())# 生产环境用数据库 checkpointerfrom langgraph.checkpoint.postgres import PostgresSaverapp = graph.compile(checkpointer=PostgresSaver.from_conn_string("postgresql://..."))
第五个坑跟 LLM 怎么挑工具有关——工具函数没写 docstring。LLM 是靠 docstring 判断这个工具该在什么时候调用,留空的话,agent 很可能一次都不会去碰它。
# 反例——没有 docstring,agent 可能永远不会调用这个工具@tooldef get_price(product: str) -> float: return 29.99# 正例——清晰的 docstring 告诉 agent 什么时候用它@tooldef get_price(product: str) -> float: """Get the current price of a product by its name.""" return 29.99
总结create_agent 是预制的 agent 循环,塞一个模型加一组工具,推理逻辑它自己处理,大多数聊天机器人和工具型 agent 用它就够了。
Deep Agents 是带了一整套外设的 create_agent——文件系统、代码沙箱、子 agent、长期记忆全都内置。任务复杂、链路长、或者需要多个 agent 协作的场合,选它。
LangGraph 是底下的原始引擎,控制权最大,封装最少。需要定制分支、需要在工作流中间插入人类审批、需要持久化执行,或者需要上层框架表达不出的并行流程时,直接用它。
https://avoid.overfit.cn/post/f016859c086a48c1b28e8758bbee4b76
by Ramakrishna Gedala