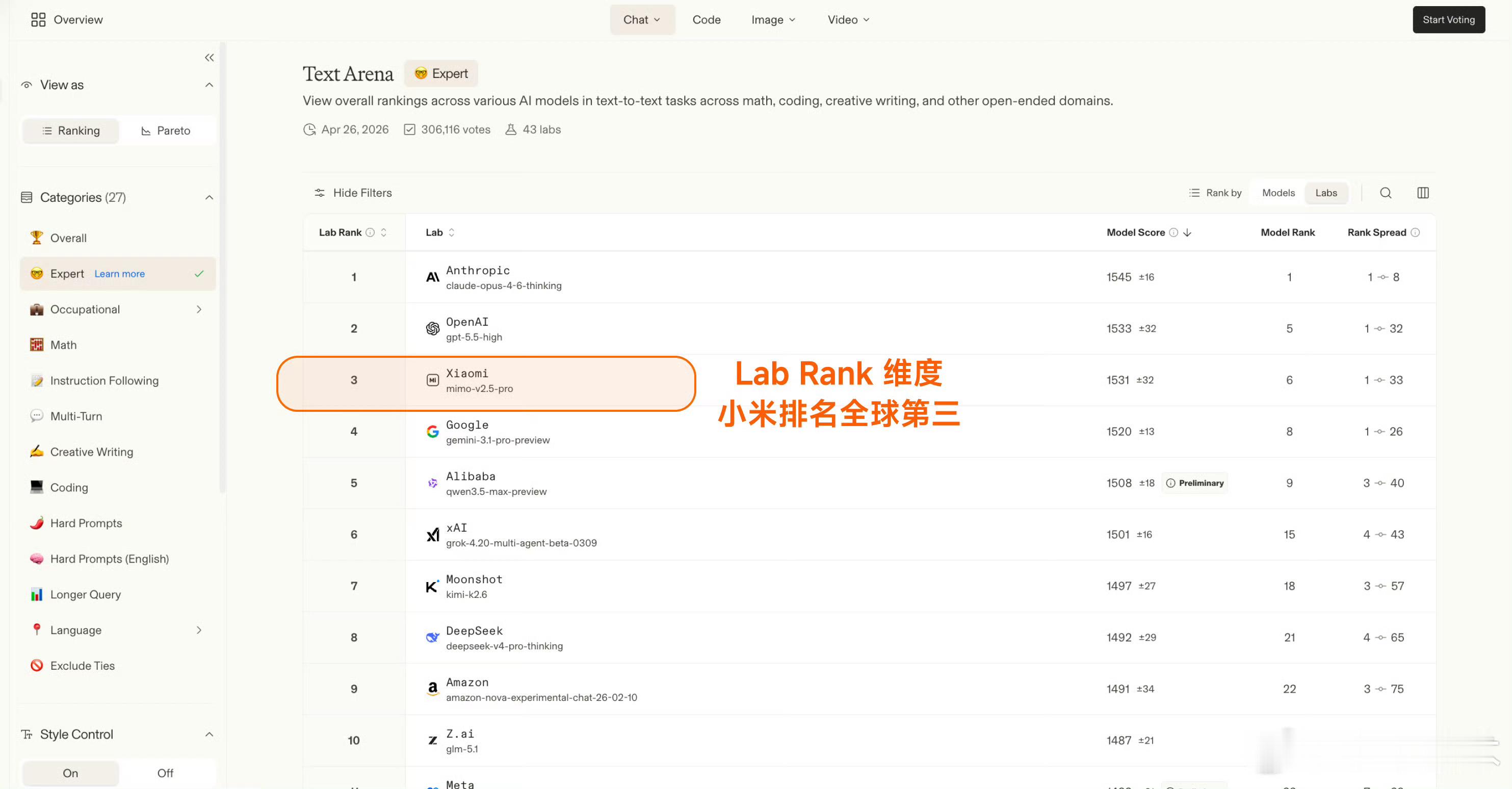
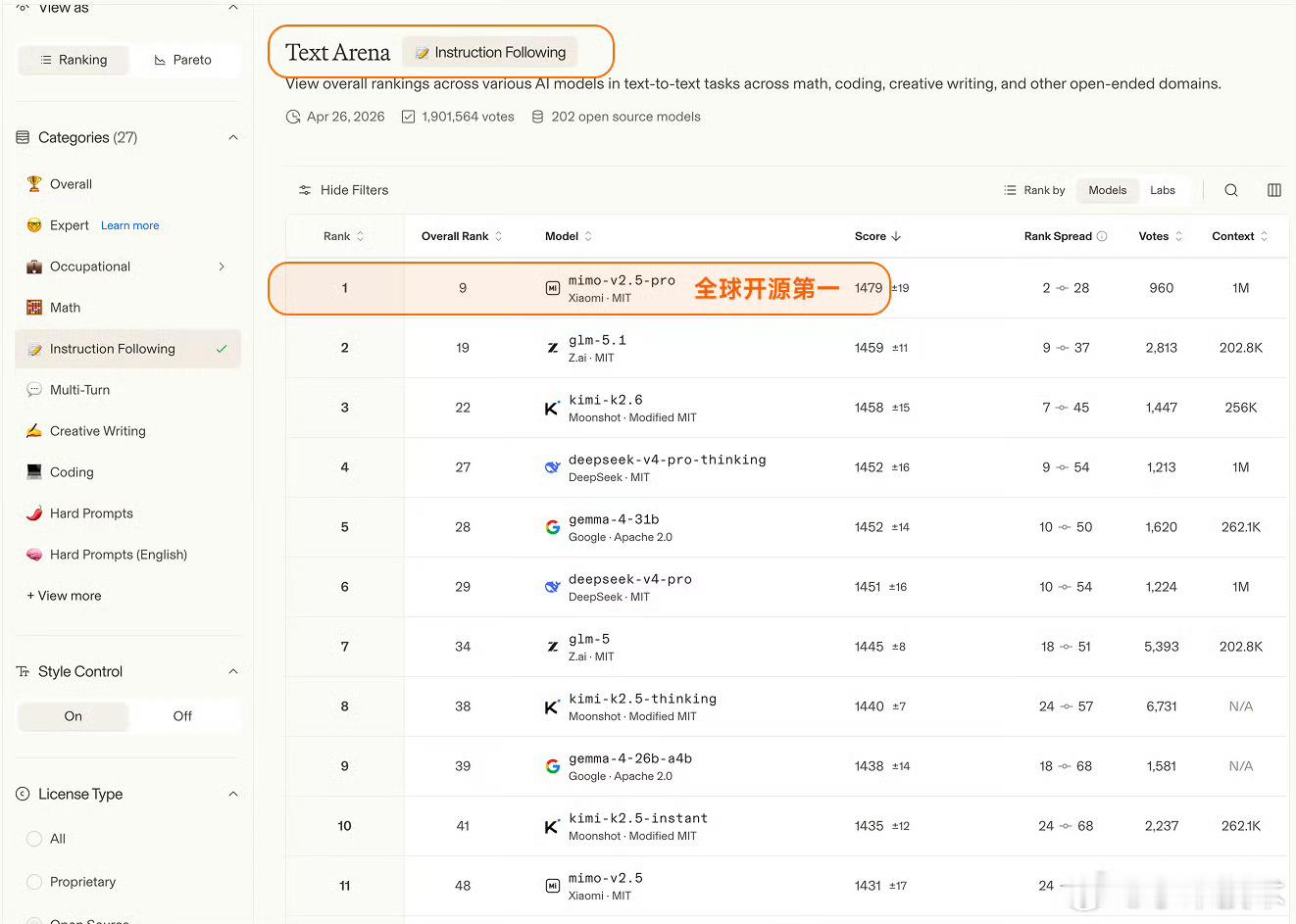
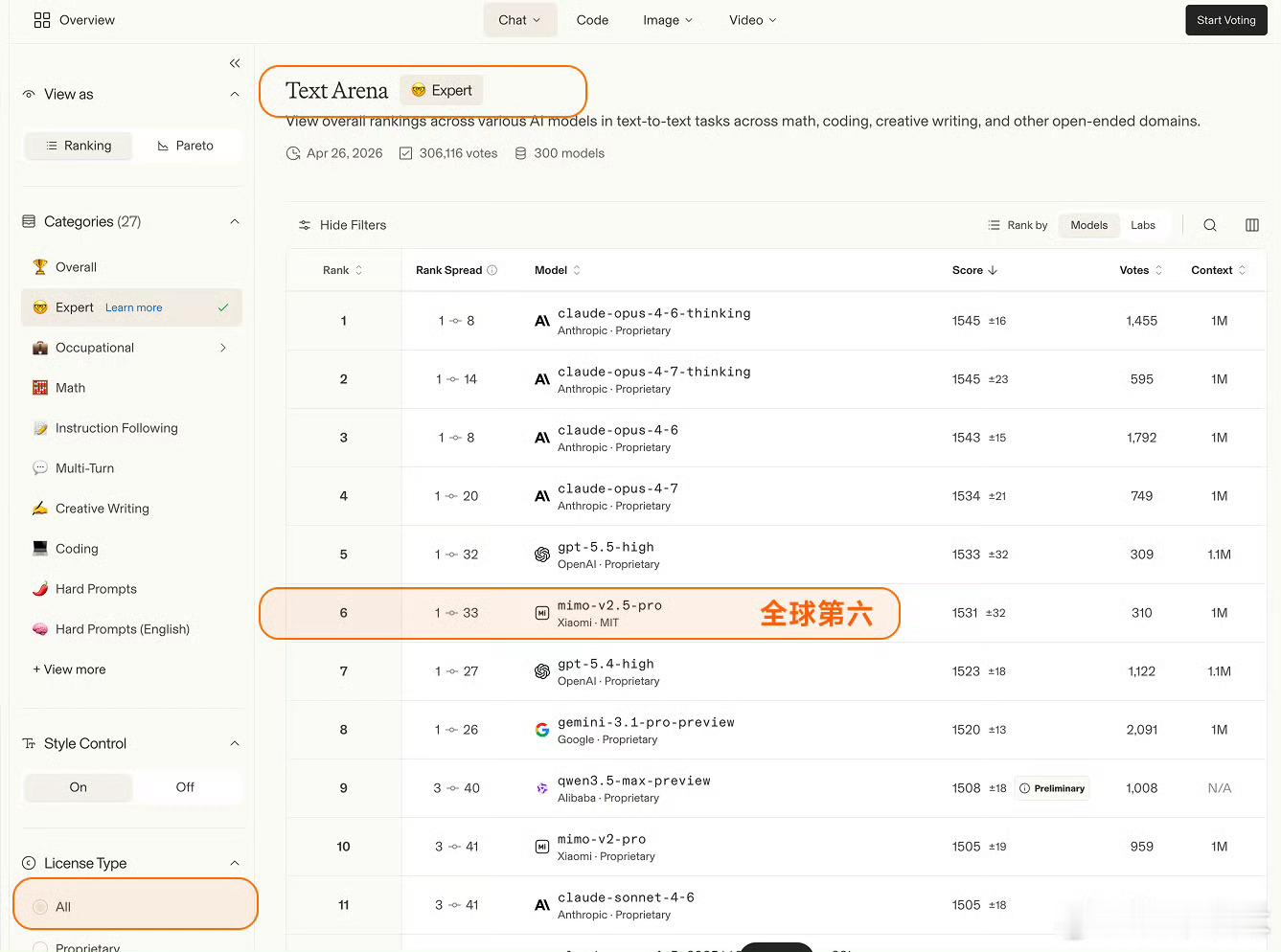
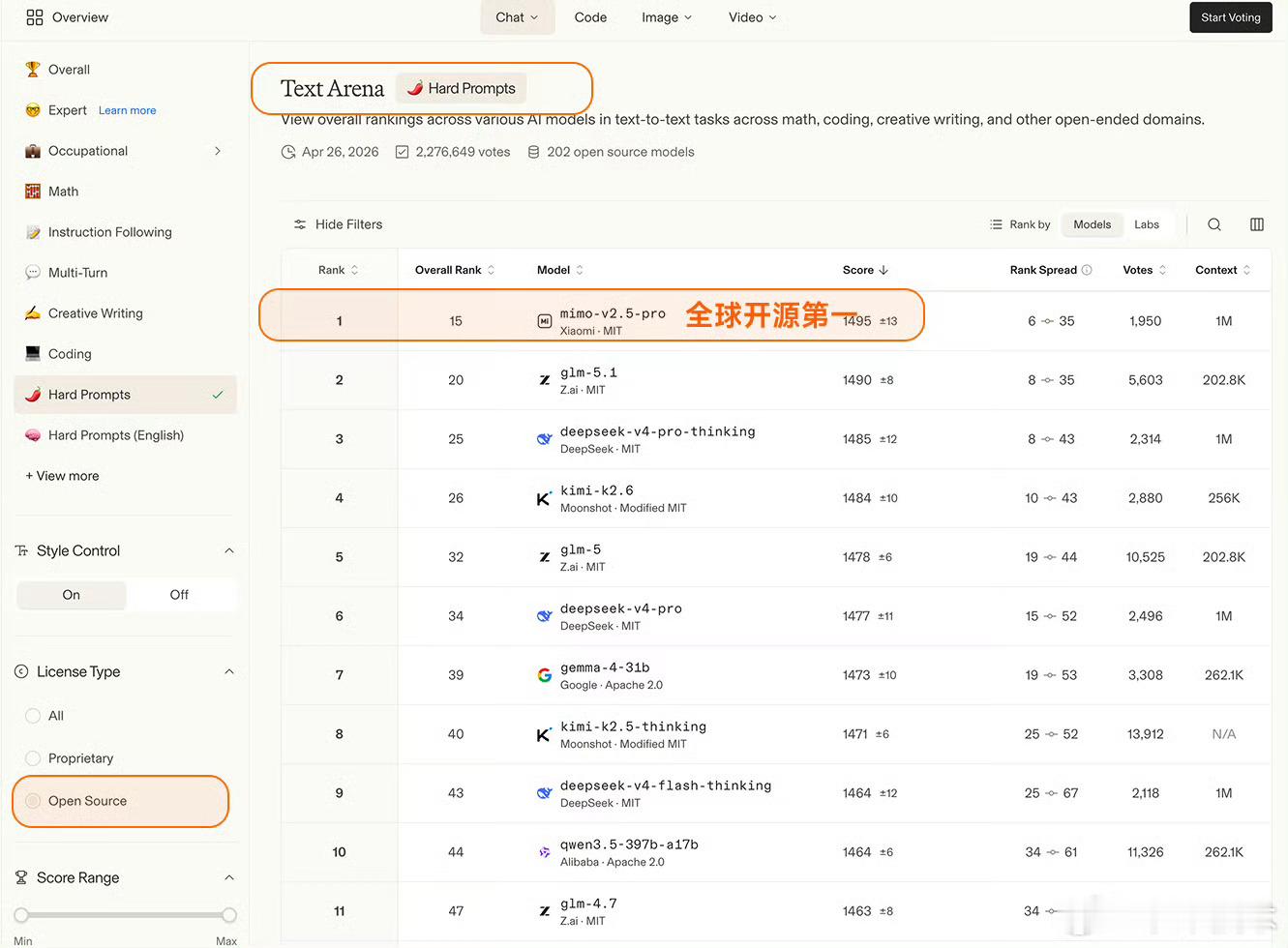
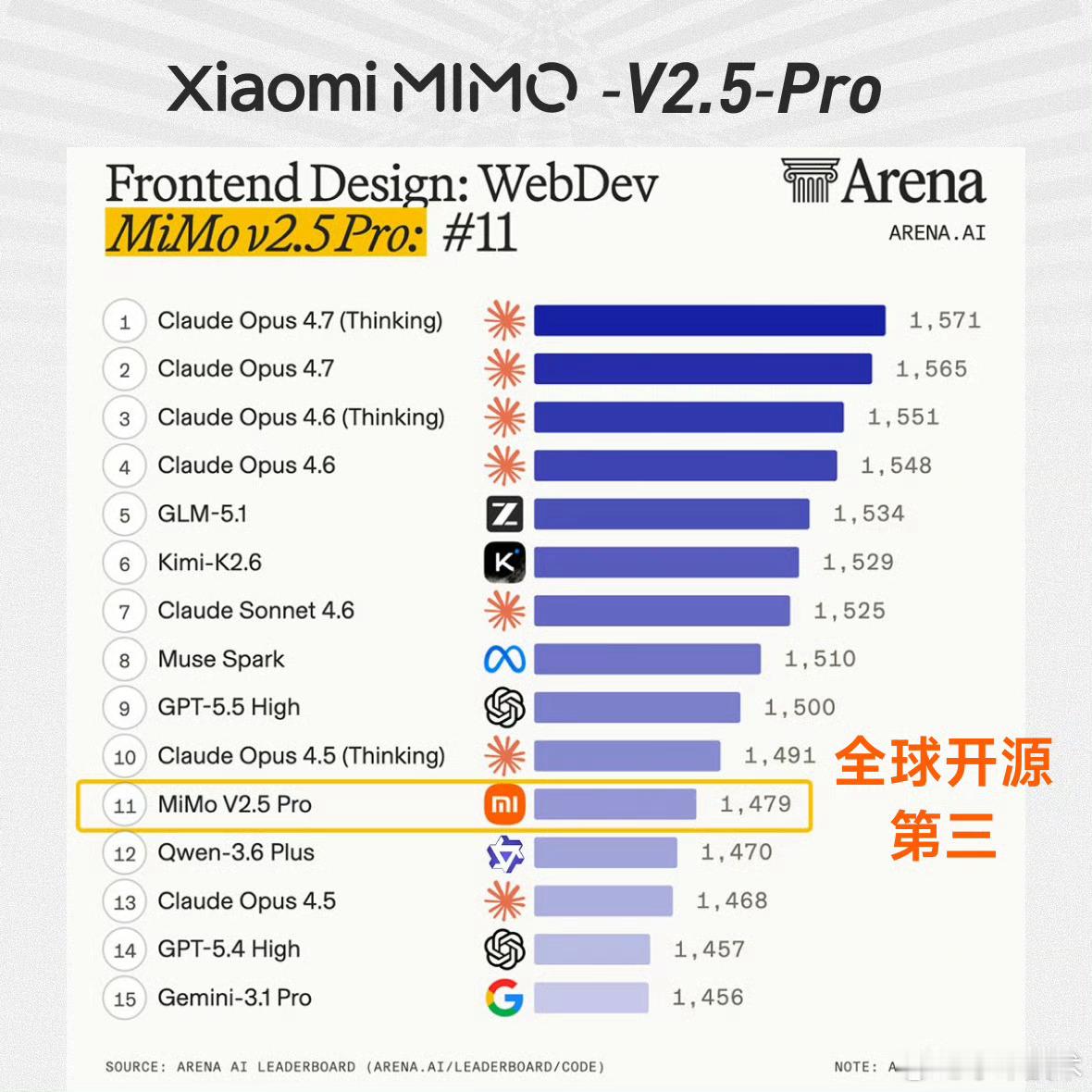
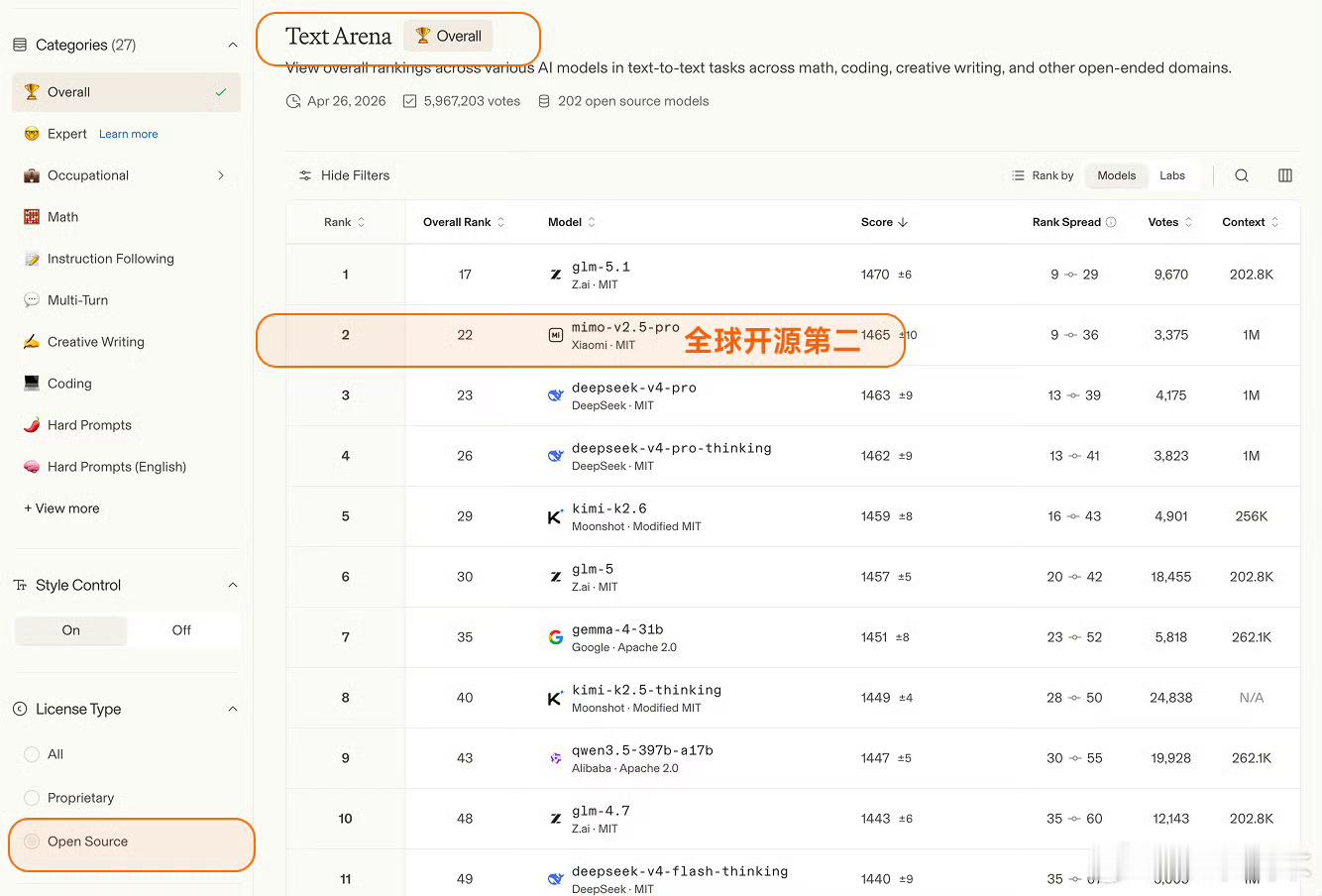
Arena评测的核心机制是「双盲测试」——所有模型身份完全隐藏,由全球真实用户基于回答质量即时投票,从底层逻辑上规避了传统评测里“针对特定数据集调优刷榜”的问题,是目前行业里公认的、最能反映大模型真实对话与解决问题能力的标尺之一。这次更新里,MiMo-V2.5-Pro在Text Arena Expert榜单上拿到了全球第六的排名,这也是整个榜单里排名第一的开源模型、同时也是排名最高的国产模型。更值得关注的是实验室维度的排名,小米以大模型研发主体的身份,排在全球第三,仅次于Anthropic和OpenAI,是目前唯一挤入这个顶级梯队的非美系、非闭源玩家。除了Expert硬核榜单,MiMo在其他维度的表现同样能打:覆盖数学、编程、创意写作等综合文本任务的Overall榜单里,位列全球开源模型第二;考察真实前端代码生成能力的Code Arena WebDev榜单,跻身全球开源前三;而在困难任务、英文困难任务、指令遵循、长文任务这四个关键子维度,更是全部拿下了全球开源模型第一的成绩,底层能力没有明显短板。这个成绩的含金量远不止几个排名数字。开源模型要在这种盲测机制里跑赢,难度远高于闭源模型——闭源模型可以无上限堆算力、针对场景定向调优,而开源模型需要在性能、可部署性、泛化能力之间做平衡,还要在用户完全不知道模型身份的情况下,靠硬实力赢过闭源巨头,本质上是小米技术路线连续性的一次验证,也给国产开源AI的发展路线打了样。