高效人工智能系列讲座地址:ickma2311.github.io/ML/HW-SW-codesign/涉及机器学习硬件-软件协同设计,目前有十三讲。
Efficient AI 第 1 讲:Introduction为什么 efficient AI 同时需要 algorithmic compression 和 hardware specialization:Deep Compression、EIE、MCUNetV3、高效 LM,以及推动 co-design 的硬件趋势。
Efficient AI 第 3 讲:Pruning and Sparsity(第一部分)为什么内存主导能耗,pruning 如何用 L0 constraint 表述,unstructured sparsity 与 structured sparsity 在硬件上的取舍,以及从 magnitude 到 second-order 和 regression-based methods 的主要 pruning criteria。
Efficient AI 第 4 讲:Pruning and Sparsity(第二部分)Layer-wise pruning ratios、使用 AMC 和 NetAdapt 的 automatic pruning、pruning 后的 fine-tuning,以及把 sparsity 转化为真实速度和能耗收益的硬件系统。
Efficient AI 第 5 讲:Quantization(第一部分)为什么 low-bit arithmetic 能节省能耗,numeric formats 如何在范围和精度之间权衡,以及 K-means 和 linear quantization 如何把压缩与硬件友好的 integer compute 联系起来。
Efficient AI 第 6 讲:Quantization(第二部分)Post-training quantization 的 granularity、clipping 与 calibration、AdaRound、带 STE 的 QAT,以及在保持可控性的同时进一步降低精度的 binary / ternary quantization 方法。
Efficient AI 第 7 讲:Neural Architecture Search(第一部分)经典高效 building blocks、cell-level NAS search spaces、elastic scaling dimensions,以及从 grid search 到 RL、differentiable search 和 evolution 的主要 architecture-search 策略。
Efficient AI 第 8 讲:Neural Architecture Search(第二部分)Accuracy estimation、weight inheritance、hypernetworks、ProxylessNAS、Once-for-All networks、zero-shot NAS,以及 neural network、mapping 和 accelerator 的联合搜索。
Efficient AI 第 9 讲:Knowledge Distillation小型 student model 如何通过 soft targets、temperature、intermediate features、self distillation、online distillation 和 task-specific distillation,从大型 teacher model 中学习。
Efficient AI 第 10 讲:MCUNet 与 TinyMLmicrocontroller 内存限制下的 TinyML:TinyNAS search-space specialization、Flash 和 SRAM 约束、CNN activation bottlenecks、patch-based inference,以及 network redistribution。
Efficient AI 第 11 讲:TinyEngineTinyEngine 通过 memory-aware kernels、loop locality、SIMD-aware execution、避免 im2col、in-place depth-wise convolution,以及 NHWC 等 layout 选择,让神经网络推理能够在 microcontrollers 上实际运行。
Efficient AI 第 12 讲:Transformer 与 LLMTransformer 和 LLM 设计,涵盖 tokenization、embeddings、attention、masking、FFNs、positional encodings,以及 encoder / decoder 变体、KV-cache 优化、grouped-query attention、现代 LLM 架构和多模态扩展。
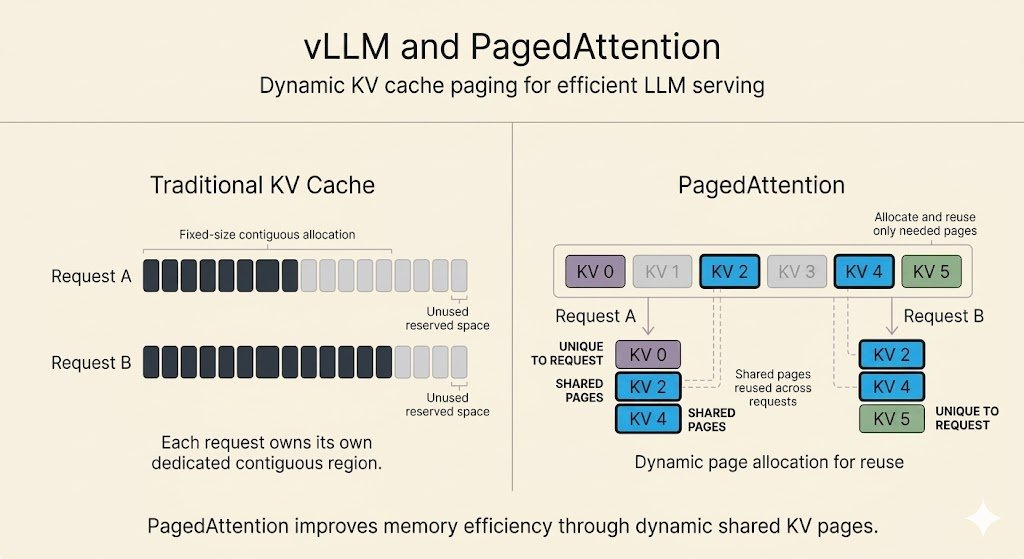
Efficient AI 第 13 讲:LLM 部署技术LLM serving 技术,从 SmoothQuant、AWQ 到 INT4 kernels、activation-aware pruning、MoE、PagedAttention、FlashAttention、speculative decoding 和 batching。
AI创造营