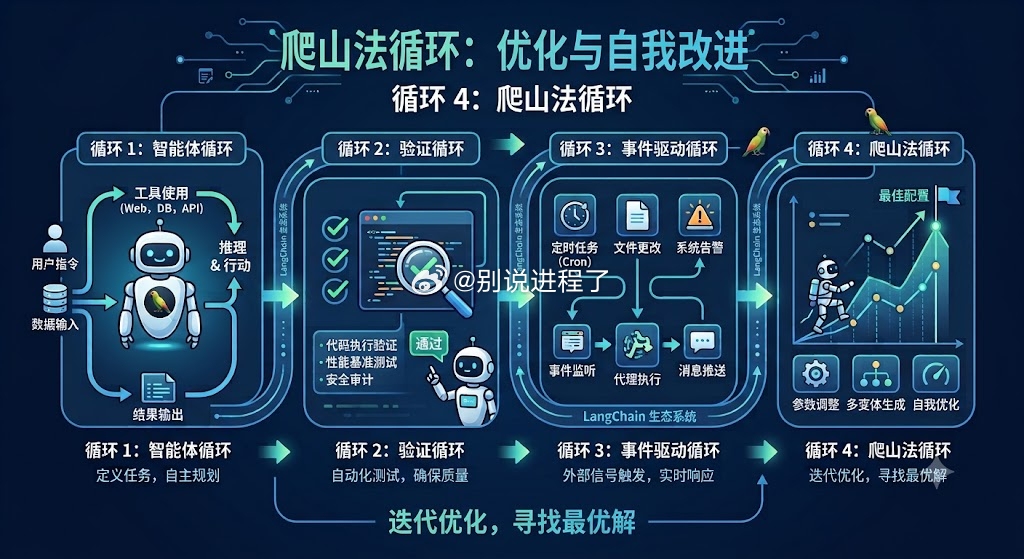
现在对于大模型的使用正在从与Agent进行提示词交互的循环进化到无需人工外部驱动的Agent自循环。这个过程目前分为四级,90%的用户停在第一级和第二级。原因在于从第一级进入第二级之后,Agent对每个任务的token消耗量增加2-3倍。但这一个升级,让模型不再把错误答案传递给客户。为模型平稳的进入生产环境铺平了道路,而目前的瓶颈时Token价格还是不够便宜,这个问题能够进一步解放,模型的能力会进一步释放,现在模型不是瓶颈,Token成本挡住了90%的用户进一步向第四级Agent迁移的速度。不用怀疑,算力,内存,硬盘,电力等基础设施是瓶颈!