How the Training Procedure Impacts the Performance of Deep Learning-based Vulnerability Patching
Antonio Mastropaolo, Vittoria Nardone, Gabriele Bavota, Massimiliano Di Penta
Università della Svizzera italiana (USI), Lugano, Switzerland
University of Molise, Campobasso, Italy
引用
Mastropaolo A, Nardone V, Bavota G, et al. How the Training Procedure Impacts the Performance of Deep Learning-based Vulnerability Patching[J]. arXiv preprint arXiv:2404.17896, 2024.
论文:https://arxiv.org/pdf/2404.17896
摘要
本文通过比较自监督和监督预训练在漏洞修补方面的现有解决方案,并首次尝试不同类型的prompt-tuning来填补这一空白。研究中使用了23个深度学习模型,发现以缺陷修复为重点的监督预训练虽然在数据收集方面昂贵,但大大提高了基于深度学习的漏洞修补效果。在这种监督预训练模型上应用prompt-tuning时,并没有显著的性能提升,但对于自监督预训练模型,prompt-tuning可以大幅提升不依赖于缺陷修复预训练的自监督预训练模型的性能。
1 引言
随着软件系统的复杂性不断增加,漏洞修补成为保障软件安全不可或缺的一环。传统的漏洞修复方法往往需要大量的人力和时间,且无法满足日益增长的安全需求。近年来,深度学习技术的快速发展为解决这一挑战带来了新的希望。深度学习模型凭借其在图像识别、自然语言处理等领域的卓越表现,被引入漏洞修补领域,以实现自动化的漏洞修复。
然而,深度学习模型在漏洞修补中面临着诸多挑战。首先,漏洞修补数据集的获取十分困难,因为漏洞修补的样本数量相对较少。其次,深度学习模型的泛化能力和效果受到模型的预训练方式和训练数据质量的影响。因此,如何有效地利用有限的数据资源,提升深度学习模型在漏洞修补中的性能,成为当前研究的关键问题之一。
为了解决这一问题,一些研究者提出了从预训练模型开始的方法,即利用预先在编程语言或类似任务上训练的模型作为漏洞修补任务的起点,以获得更好的泛化性能。然而,这些方法的有效性和可行性尚待进一步验证。
除了预训练之外,另一种克服训练数据不足的策略是prompt-tuning,即将下游任务(即微调)的训练目标转化为类似预训练阶段的目标,因此可能重新利用在该阶段获得的信息。对于漏洞修复任务,经典的微调会将易受攻击的代码作为输入,要求模型生成其修补版本。
有研究表明,对漏洞修补进行监督预训练是更有利的,但也有其他研究报道自监督预训练的优越性,以及最近有关为其他软件工程任务进行prompt-tuning的研究。然而,对于漏洞修补任务,缺乏对这些训练策略进行系统比较和对比的研究。本文旨在填补这一空白,通过对漏洞补丁生成任务中可用的不同训练策略进行大规模实验。为了建立研究的基础,我们首先复现了现有的基于深度学习的漏洞修补工作,即 Fu 等人的工作,该工作表明自监督预训练相对于有监督的bug修复预训练的优越性。在进行这样的复制过程中,我们发现了 Fu 等人使用的训练集和测试集中存在“逐标记”重复,这意味着所报告的性能可能存在膨胀。因此,我们清理了数据集,重新训练了模型,并观察到与 Fu 等人报告的性能相比,性能大幅下降。然后我们在相同的清理数据集上尝试了几种不同的训练程序,包括:(i) 不进行预训练,即模型直接用于漏洞修补任务的微调;(ii) 自监督预训练和标准微调;(iii) 基于bug修复的监督预训练和标准微调,代表先前提出这一想法的工作;以及 (iv) 在预训练模型(无论是自监督还是监督预训练策略)之上执行了十种不同类型的prompt-tuning。总体而言,我们的研究需要训练和测试 23 个模型。我们的主要发现表明:(i) 鉴于微调数据(即真实世界的漏洞修补)的稀缺性,预训练对漏洞修补任务始终有益,无论是自监督还是监督;(ii) 不足为奇的是,监督预训练(使用bug修复)优于自监督预训练,与先前的发现相矛盾;(iii) 在漏洞修补的背景下,prompt-tuning是一个廉价的机制,可以大幅提升自监督预训练模型的性能,而对于受益于监督预训练的模型来说,它并不真正有助于模型,因为它们“丢失了关于其预训练的自然语言的知识”。
2 技术介绍
实验的详细训练策略如下:
无预训练 + 微调。我们在VulRepairFC数据集上对一个 模型进行微调(即与 CodeT5中使用的相同模型),没有进行任何预训练。这样的模型将作为基准,评估预训练对模型性能的影响。自监督预训练 + 微调。我们复制了符合Fu等人的VulRepair方法,但是在VulRepairFC数据集上进行微调(即其数据集的清理版本)。VulRepair利用了预先训练的 CodeT5,如前所述,该模型使用了自监督的掩码语言模型预训练目标。自监督和监督预训练 + 微调。我们的目标是训练一个模型,利用自监督(掩码语言模型)和监督(缺陷修复)预训练,在微调漏洞修复之前。这种方法受到 Chi等人和Chen等人的研究启发。我们再次从(自监督)预训练的 CodeT5 开始。然后,我们使用缺陷修复数据集进一步对其进行5个时期的训练。最后,我们使用 数据集将模型专门用于下游任务。prompt-tuning。如前所述,对于每个微调实例,prompt-tuning会进行变换,使其类似于在预训练过程中遇到的数据。我们在预训练模型之上进行prompt-tuning实验。也就是说我们不进行常规微调过程,而是将其替换为硬或软的prompt-tuning。3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下研究问题:
RQ1:不同的训练程序如何影响基于深度学习的漏洞修复系统的性能?
RQ1.1:自监督预训练目标的使用在多大程度上有助于生成漏洞修补程序?
RQ1.2:监督预训练目标的使用在多大程度上有助于生成漏洞修补程序?
RQ1.3:当修补易受攻击的代码时,prompt-tuning起到什么作用?
本实验采用了如下几种训练方式:
1. 自监督预训练。在尝试使用掩码语言模型目标进行自监督预训练时,我们利用了CodeT5,这是一个在代码上进行了预训练并且在软件工程文献中被广泛使用的文本到文本转换Transformer(T5)模型。因此,我们以下描述了用于其预训练的数据集。
Wang等人利用了CodeSearchNet数据集来预训练CodeT5。该数据集包含技术自然语言(即代码注释)和代码。此外,Wang等人还从GitHub的C/C#代码库中收集了补充数据,共计8,347,634个预训练实例,这里一个实例是一个代码函数。其中3,158,313个是包含代码和文档的,而5,189,321个只包含代码。
2. 基于bug修复的有监督预训练。Chen等人提出了在对漏洞修补的任务进行微调之前,使用基于bug修复的有监督预训练。因此,我们使用他们提供的bug修复语料库作为监督预训练数据集。为了构建这个数据集,作者挖掘了7.29亿个GitHub提单,将其中的2100万个标识为bug修复,并在其中选择了91万个C/C++ bug修复提交。然后收集了用于修复bug的函数级别更改,形成 ⟨Fb, Ff⟩ 对,其中 Fb 和 Ff 分别表示函数 F 的有bug版本和修复后的版本。经过去重处理剩下544,858个有效实例,可用于训练一个用于bug修复任务的模型(即,输入 Fb,期望输出 Ff)。在这些对中,有534,858个用于训练,剩下的10,000个用于验证(即,用于识别bug修复任务的最佳表现的预训练模型)。
3. 用于漏洞修补的微调。我们重用了VulRepair包中提供的数据集,该数据集包含了8,482个漏洞修复实例(一个有漏洞的C/C++函数及其修复版本),通过合并两个数据集CVE-Fixes 和Big-Vul 获得,然后按照70%用于训练(5,937个)、20%用于测试(1,706个)以及10%用于验证(839个)进行划分。我们发现并丢弃了38个实例,其修补部分为一个空字符串(训练集中有24个,验证集中有3个,测试集中有11个)。在这个初步的清理过程之后,我们解决了训练、验证和测试集之间存在重叠实例的问题。我们从训练集中移除了所有与另一个集合(验证集或测试集)中具有相同对应的样本。具体地说,我们从训练集中移除了与测试集重复的674个实例,以及与验证集重复的322个实例。我们决定从训练集中移除这些实例,而不是从测试集或验证集中移除,因为我们希望通过比较我们在清理后的数据集上微调VulRepair时的发现与原始论文中报告的结果来评估性能影响。为了做到这一点,重要的是利用完全相同的测试集,因此,它应保持不变。我们在去重步骤中移除的实例数量(1,008个)比训练集与测试集和验证集之间的重叠实例数量之和(674 + 322 = 996)要高。这是因为训练集本身包含一些重复实例,因此一些与测试集或验证集共享的实例在训练集中出现了多次,因此被移除了多次。
RQ1.1 自监督预训练对基于深度学习的技术的性能的影响
实验设计。我们评估了经典掩蔽语言模型自监督目标对基于深度学习的技术的性能的影响,该技术对漏洞补丁进行了微调。我们在测试集中的 1695 个函数上运行每个训练好的模型,要求其生成补丁。我们使用束搜索解码模式 ,可以为输入序列生成多个漏洞修复候选项。我们使用两个指标评估每个模型的性能:不同束大小 K 下的准确匹配率 (EM@K),以及 CrystalBLEU 分数 。我们还进行了统计测试,以确定实验中的哪种技术在修复易受攻击的代码方面更有效。为此,我们使用 McNemar 检验(这是一种针对相关样本的比例检验)和 Odds Ratio(OR)来评估技术可以生成的准确匹配率(EM)。我们还使用 Wilcoxon 符号秩检验在句子级别计算的 CrystalBLEU 分数的分布,对每种技术生成的预测进行统计比较。Cliff's Delta (d) 被用作效果大小,并设置阈值:|d| < 0.10 时微小,0.10 ≤ |d| < 0.33 时小,0.33 ≤ |d| < 0.474 时中等,|d| ≥ 0.474 时大。对于所有测试,我们假设显著性水平为 95%,并通过使用 Holm's 校正程序调整 p 值来考虑多重测试。
结果。表1报告了我们研究对象的不同训练策略所取得的结果。第一列“Model-ID”报告了我们为每个训练模型分配的唯一标识符。 “Pretraining” 和 “Fine-tuning” 列指示了每个模型采用的训练程序组合。例如,第一行M0表示直接针对漏洞修补任务进行了标准微调过程的非预训练模型。最后,EM 和 CB 报告了特定配置在精确匹配(EM)方面实现的性能以及测试集中所有预测的平均 CrystalBLEU 分数 (CB)。表2报告了统计测试的结果(Fisher's exact test 和 Wilcoxon signed-rank test),包括调整后的 p 值、OR 和 Cliff's d 效应大小。OR > 1,或者正的 Cliff's d值表明右侧处理优于左侧处理。为了提高可读性,我们对处理进行排序,以显示通常 ≥ 1 的 OR。

表1:使用不同方法修补易受攻击的C函数的精确匹配程度和CrystalBleu分数
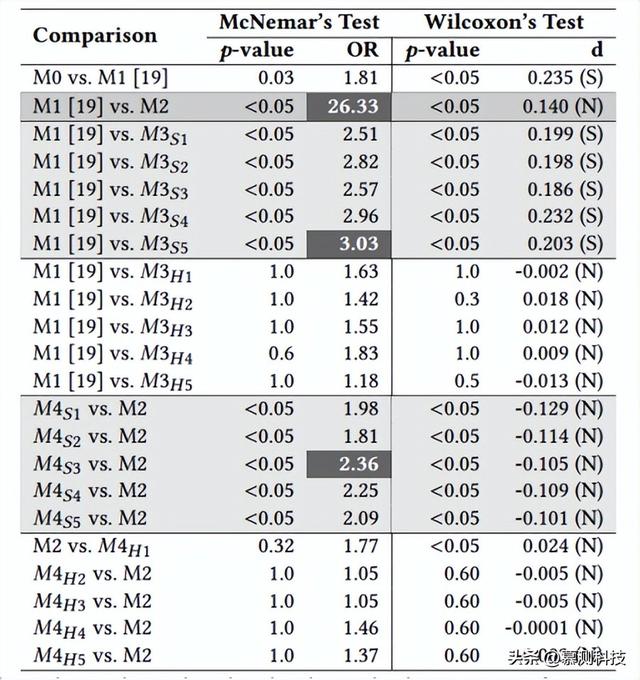
表2:McNemar和Wilcoxon对top1的预测结果
RQ1.2 监督预训练对基于深度学习的技术的性能的影响
实验设计。类似于RQ1.1, 我们将修复漏洞的任务作为一个监督的预训练目标,作为漏洞修补的更一般的表示,评估使用类似于下游任务的监督目标进一步预训练自监督预训练模型的有效性。
结果。与仅使用自监督训练相比,可以显著提升性能。这种改进在我们尝试的所有波束大小下都是一致的。具体来说,当仅依赖顶部预测(即,K=1)时,EM预测从3.34%增加到12.28%(+∼9%)。当模型被要求生成更多候选修补程序时,这种差距甚至更大,EM预测的改进达到+∼12%。
注入修复漏洞知识所确保的卓越性能也得到了McNemar检验的证实,它报告了M1和M2之间EM预测的统计显著差异,OR=26.33有利于M2。Wilcoxon符号秩检验也表明,当比较M1和M2之间的CrystalBLEU分数分布时存在统计显著差异(p值<0.05),然而,效应大小很小。这主要是由于漏洞修复和漏洞修复之间的共同之处,有助于模型在不使用用于此类任务的有限微调实例的情况下获得与下游任务相关的知识。最终,漏洞修复无非就是特定的漏洞修复,其中漏洞可能被用于安全攻击。图1展示了这样一个场景的具体示例。图的顶部显示了我们测试集中修复漏洞所需的更改,而底部显示了Chen等人数据集中的一个修复漏洞的更改(即,用于漏洞修复训练的数据集)。正如可以看到的那样,虽然作用于不同的代码组件,但涉及的两个函数都需要相同的代码更改。换句话说,在这两个函数中,字段disc_data和receive_room都需要分别初始化为NULL和0。在这种情况下,学到的修复模式基本相同。

图1:易受攻击的代码与需要模型执行类似代码更改的错误代码的示例
RQ1.3 prompt-tuning的作用
实验设计。对于表1和表2的结果,我们首先关注仅使用自监督过程对预训练模型进行微调时的prompt-tuning效果(表1中的和)。随后,我们报告并讨论了使用自监督和有监督(即bug修复)预训练(表1中的和)对预训练模型进行prompt-tuning的影响。
结果。软prompt(M3S1至M3S5)和硬prompt(M3H1至M3H5)均有助于提高仅使用自监督目标预训练的模型的性能。但改进的幅度有显著不同。当模型被要求生成一个预测时(K=1),软prompt-tuning提供了2.14%至3.44%的EM预测的增加。虽然这些改进看起来微不足道,但baseline(即M1)仅达到了3.34%的EM预测。因此,在prompt-tuning的背景下表现最好的模板(M3S5)使模型的预测能力提高了一倍。统计测试的结果(表2)可以支撑这种观点,经过软prompt-tuning的模型在使用的prompt模板上独立于其他模板,都达到了显著更高的EM预测百分比,而与标准方法微调的自监督预训练模型相比。这些调整后的p值总是<0.05,ORs范围从2.51到3.03。在CrystalBLEU得分方面也观察到改进,与M1相比,K=1时增加了12%。统计测试证实了一个显著的差异,有利于用软prompt进行微调的模型,独立于使用的模板(在所有情况下,p-values <0.05,效应大小较小)。在使用不同的软prompt模板时,我们发现它们对性能有显著的影响。在查看top预测(K=1)时,表现最好的模板是M3S5,而表现最差的是M3S1,EM预测方面有1.30%的差距,这意味着相对提高了24%(1.30/5.48)。这表明在采用prompt-tuning时,仔细选择模板的重要性:模板的设置必须与其他模型的超参数设置同样重要,这些通常会经过调整过程。同样值得注意的是,虽然M3S5是K=1的最佳模板,但对于其他K值而言情况并非如此:对于K=3和K=5,它是第二佳,而对于K=10,它是第三佳。因此,即使是为训练模型设想的使用场景,以及它将需要为每个输入生成的候选解决方案数量,也可能会影响所采用模板的选择。查看硬prompt结果,与基baseline相比,它的改进比软prompt的改进要小(例如,K=1时增加了0.67%)。所有尝试的提示和所有考虑的束大小K都保持较低(或在少数情况下没有)改进。
对已经获取了任务特定知识(感谢错误修复训练)的模型进行prompt-tuning时所取得的结果与对自监督预训练模型所取得的结果相差甚远。观察表2中的和,我们可以注意到,在这种情况下,经过硬prompt的模型是表现最好的,总体上在EM预测方面取得了最佳表现,这对于所有的K值都成立。与baseline(仅使用自监督+监督训练,不进行prompt-tuning的M2)相比,改进幅度相对较小(在EM方面约+1%),但在统计上显著。需要注意的是,这与先前关于处理其他软件工程任务时prompt-tuning的益处的文献观察是一致的。相反,软prompt-tuning能够改善CrystalBLEU方面的结果,但在EM预测方面却有所下降,比M2的baseline更差,统计分析也证实了这一点。在对已经经历了自监督和监督训练组合的模型进行软prompt-tuning时为何没有进一步改进可能有两个原因:第一个原因与模型从错误修复中获取的额外知识有关。正如之前所示(见图1),修复一个通用的错误可能需要非常相似的代码更改,这些更改与修补漏洞所需的相似。因此,这些任务之间的相似性可能已经与模型熟悉的代码转换相似,并且将这些转换应用于不同的上下文(即漏洞修复)的努力是微不足道的;第二个原因与prompt-tuning策略有关,这些策略严重依赖于在预训练期间获取的自然语言知识。当进一步专门化预训练模型以纳入特定上下文知识时,这些关键信息可能会部分被覆盖。换句话说,虽然自监督预训练模型主要捕捉自然语言中的词语统计分布,但另外经过错误修复训练的模型可能已经失去了一些表示和解释自然语言的能力,导致表现不佳。
转述:杨沛然
