RAG 的关键其实就在检索这一步:检索质量好不好,很大程度上取决于怎么切分和存储文档——也就是分块(Chunking)这个看起来不起眼的环节。
固定分块、递归分块、语义分块、结构化分块、延迟分块,每种方法在优化上下文理解和检索准确性上都有各自的价值。用对了方法,检索质量能提升一大截,幻觉问题也会少很多。

RAG 的效果很依赖文档拆分的方式。这篇文章会先过一遍 RAG 的基本流程,然后重点讲分块在里面扮演什么角色,接着深入聊聊固定、递归、语义、基于结构和延迟这五种分块技术的定义、平衡点和实现思路,方便你根据实际场景选择合适的方案。
RAG 工作流程概览标准流程是这样的:
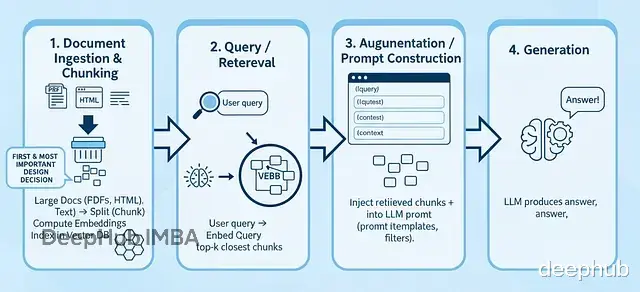
文档摄取和分块 拿到大文档(PDF、HTML、纯文本)→ 切分成小块 → 算嵌入向量 → 扔进向量数据库。
查询检索 用户提问 → 把问题转成向量 → 用余弦相似度找出最相关的 top-k 个块
上下文增强 把检索到的块和元数据塞进 LLM 的 prompt 里,通常会用模板做些处理和筛选。
答案生成 LLM 根据检索内容加上自己的知识生成回答。
生成器只能看到你喂给它的东西,所以检索质量直接决定了最终效果。块切得不好或者根本检索不到相关内容,再强的 LLM 也救不回来。这也是为什么业内普遍认为 RAG 大概 70% 靠检索,30% 靠生成。
在讲具体技术之前,得先明白为什么分块这么重要:
嵌入模型和 LLM 都有上下文长度限制,没法直接塞整个文档进去;块必须语义完整。要是在句子中间或者一个完整意思的中间切断,嵌入向量就会带噪声甚至产生误导;块太大的话,相关的细节信息容易被淹没;反过来块太小或者重叠太多,就会存大量冗余内容,浪费算力和存储。
下面按从简单到复杂的顺序,聊聊五种主流的分块方法。
1、 固定分块最直接的做法:按固定长度(token、词或字符)切文本,块与块之间留一些重叠部分。
这是 RAG 项目的常见起点,特别适合文档结构未知或者内容比较单调的场景(比如日志、纯文本)。算是一个不错的 baseline。
代码实现示例:def fixed_chunk(text, max_tokens=512, overlap=50): tokens = tokenize(text) chunks = [] i = 0 while i < len(tokens): chunk = tokens[i : i + max_tokens] chunks.append(detokenize(chunk)) i += (max_tokens - overlap) return chunks
2、递归分块先按高层级的边界拆(段落或章节),如果某个块还是超长了,就继续往下拆(比如按句子),直到所有块都符合大小限制。
适合有一定结构的文档(带段落、章节的那种),既想保持语义边界完整,又要控制块的大小。
好处是能尽量保留段落这种逻辑单元,不会在奇怪的地方切断,而且能根据内容自动调整块的大小。
用 LangChain 实现递归分块:
from langchain.text_splitter import RecursiveCharacterTextSplitter # Sample texttext = """ Input text Placeholder... """ # Define a RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=200, # target size of each chunk chunk_overlap=50, # overlap between chunks for context continuity separators=["\n\n", "\n", " ", ""] # order of recursive splitting) # Split the textchunks = text_splitter.split_text(text) # Display resultsfor i, chunk in enumerate(chunks, 1): print(f"Chunk {i}:\n{chunk}\n{'-'*40}")
这样做能确保后续做嵌入和检索的时候,不会在边界处丢失关键上下文。
3、语义分块根据语义变化来切分文本。用句子级别的嵌入来判断哪里该结束一个块,哪里该开始下一个。相邻句子如果语义相近就放一起,相似度明显下降了就切开。
在检索精度要求高的场景特别有用(法律文本、科研论文、技术支持文档之类的)。不过计算嵌入和相似度有成本,而且相似度阈值的设定需要反复调试。
代码实现:
from sentence_transformers import SentenceTransformer, util model = SentenceTransformer("all-MiniLM-L6-v2") def semantic_chunk(text, sentence_list, sim_threshold=0.7): embeddings = model.encode(sentence_list) chunks = [] current = [sentence_list[0]] for i in range(1, len(sentence_list)): sim = util.cos_sim(embeddings[i-1], embeddings[i]).item() if sim < sim_threshold: chunks.append(" ".join(current)) current = [sentence_list[i]] else: current.append(sentence_list[i]) chunks.append(" ".join(current)) return chunks
4、基于结构的分块利用文档本身的结构——标题、子标题、HTML 标签、表格、列表这些——作为天然的分块边界。比如每个章节或标题自成一块(必要时也可以继续递归拆分)。最适合处理 HTML 页面、技术文档、维基类内容,或者任何有明确语义标记的材料。
从实际经验来看,这种策略效果最好,尤其是配合递归分块一起用的时候。
但前提是得先解析文档格式,而且对于特别长的章节,可能还是会超出 token 限制,这时候就需要混合使用递归拆分了。
实现要点:
用专门的库解析 HTML / Markdown / PDF 结构
把章节标题(<h1>、<h2> 之类的)当作块的根节点
某个章节太长的话,退回到递归拆分
表格和图片可以单独成块,或者做一下摘要处理
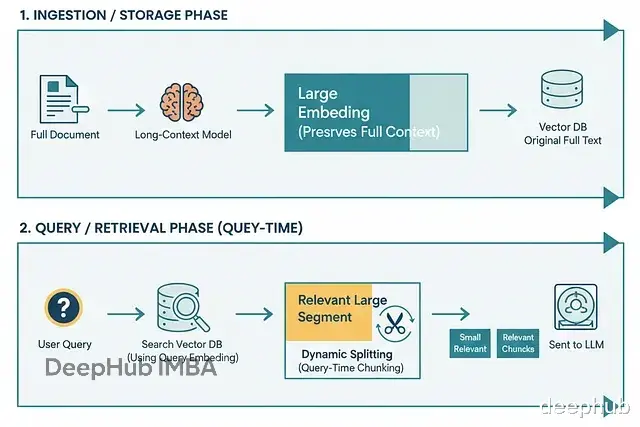
5、延迟分块(也叫动态分块或查询时分块)什么是延迟分块:把文档拆分这件事推迟到查询时再做。
不是一开始就把所有东西切碎,而是存储比较大的片段甚至整份文档。等查询来了,只对相关部分做动态拆分或筛选。核心思路是在做嵌入的时候保留完整上下文,只在确实需要的时候才切分。
Weaviate 的说法是把这叫做"反转传统的嵌入和分块顺序"。
先用支持长上下文的模型对整个文档(或大段落)做嵌入。然后基于 token 范围或边界标记,池化生成块级别的嵌入。
具体流程
在索引里存储大段落或完整文档。
查询来了,先检索出 1-2 个最相关的大段。
在这些段落内部,围绕匹配查询的部分动态切分(可以用语义或重叠的方式)成更细的块。
对这些细块做过滤或排序,最后喂给生成器。
有点像编程里的延迟绑定,等有了更多上下文信息再做决定。
适用场景
大型文档集(技术报告、长文)里,跨段落的上下文关联很重要的情况。
文档经常更新的系统,不用每次都完整重新分块,能省不少时间。
高精度要求或高风险的应用(法律、医疗、监管类),代词或引用理解错了代价很大的那种。
听起来挺理想,但代价也摆在那。嵌入整个文档或大段内容,计算开销相当大,而且需要支持长 token 的模型。查询时的计算成本也会增加,可能影响响应速度。
写在最后分块这件事看着不起眼,但实际上直接决定了 RAG 系统的上限。固定分块简单粗暴适合快速验证;递归分块在保持语义完整性上更有优势;语义分块精度高但成本也高;结构化分块对特定类型文档效果最好;延迟分块则是在计算资源充足时的高级玩法。
没有哪种方法是银弹。实际项目里往往需要根据文档类型、查询特点、资源限制来组合使用。比如技术文档用结构化分块打底,长篇报告考虑延迟分块,日常问答系统可能固定或递归分块就够了。
https://avoid.overfit.cn/post/aa5e48e682a746bba4b22af0a2257775
作者:Ahmed Boulahia