还在为手动翻阅大量PDF资料、逐条复制粘贴指定信息到Excel而头疼吗?今天,我们将向你展示如何利用Python实现自动化办公,一键批量从PDF文档中提取指定信息,并将这些信息整理到Excel和文本文档中,让你从此告别繁琐的数据整理工作!
故事背景
小李在一家金融公司任职,每天都需要分析大量上市公司的年报数据。然而,传统的分析方法要求他逐一打开PDF年报,阅读内容,并将有用的信息手动复制到Excel表格中。这不仅耗时费力,而且容易出错。小李渴望找到一种更高效的数据处理方法,以便他能够专注于分析工作本身。
一、痛点分析与需求明确
在金融分析领域,上市公司年报是数据的重要来源。然而,手动处理这些PDF年报信息却是一项繁琐且耗时的任务,根据小李的历史经验传统方式的复制粘贴,完成一个文档指定信息的提取大概需要5分钟左右的时间,而且还需要保证复制的内容完全正确,从18年24年的所有上市公司年报大概有上千份,也就是需要5000分钟的重复性工作还不能保证得到的数据完全正确。为了解决这个问题,我们决定利用Python的自动化能力,实现批量从PDF年报中提取指定信息的功能。


想要得到的结果,主要的业务信息提取到txt里
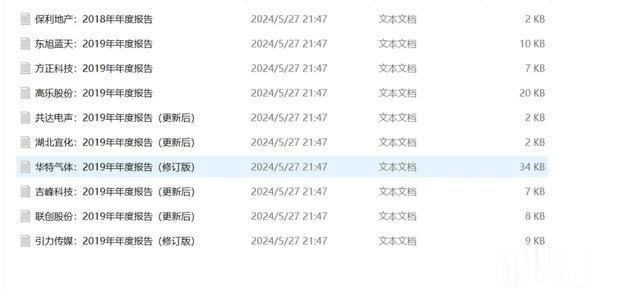
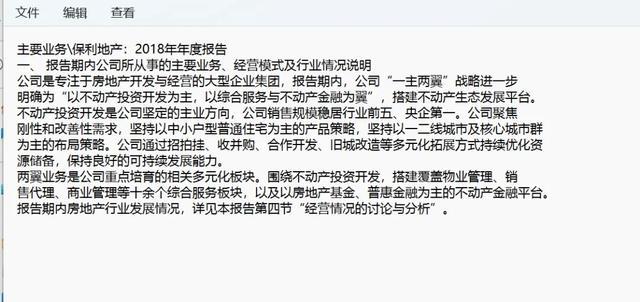
二、技术实现
PDF年报结构分析
首先,我们需要对上市公司年报的结构进行分析,确定目标信息所在位置。一般来说,年报中的“公司业务概要”部分包含了我们需要的主要业务信息。这部分内容通常位于“第三节”,并且上海市场和深圳市场的年报格式略有不同。

确定关键词
为了准确提取目标信息,我们需要确定关键词。在本例中,我们选择“公司业务概要”和“重大变化情况”作为文字截取的起始和结束关键词。通过在PDF文档内搜索这两个关键词,我们可以确定它们的位置,并截取它们之间的内容。
编写Python脚本
接下来,我们利用Python编写一个自动化脚本,实现批量处理PDF年报的功能。这个脚本将使用pdfplumber等库来读取PDF文件,并使用正则表达式等技术来匹配关键词并截取目标信息。然后,我们将这些信息整理到Excel和文本文档中,以便后续分析。
#获取待处理的年报的路径import ospath='年报' #文件所在文件夹files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径import pdfplumberimport timetime0= time.time()#从字符串中提取指定首尾的文字def Get_text(start_str, end_str, source_str): start = source_str.find(start_str) #找到开始关键词对应的位置索引 if start >= 0: start += len(start_str) end = source_str.find(end_str, start)#找到结束关键词对应的位置索引 if end >= 0: return source_str[start:end].strip() #截取起始位置之间的字符#定义写入txt的函数def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表. file = open(filename + '.txt','w',encoding="utf-8") file.write(filename + "\n") for i in range(len(final_text)): text = final_text[i] if i != len(final_text)-1: #判断是否最后一个元素 text = text+'\n' #若不是最后一个元素才换行 file.write(text) time.sleep(0.1) #加入一个延时,避免批量写入出现乱码 file.close() #获取年报中的“主要业务”信息for file in files: data = [] key_words = "重大变化情况" with pdfplumber.open(file) as p: for i in range(6,26): #公司主要业务主要年报的在8~23页范围内 page = p.pages[i] #选页 page_text = page.extract_text() #提取文字 data.append(page_text) #将提取的文字加入列表 if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间 break # 终止for循环 #将数据列表`data`转换成一个大字符串 source_str = "".join(data) #截取文字 start_str = "公司业务概要" end_str = "重大变化情况" text_wanted = Get_text(start_str, end_str, source_str) #去掉不需要的尾巴 final_text = text_wanted.split("\n")[:-1] new_file = "主要业务\\" + file.split("\\")[1][:-4] To_txt(new_file,final_text) print("{} 处理完成!".format(new_file)) time1= time.time()print("处理完成,共用时 {} 秒。".format(time1-time0))效果展示
经过我们的努力,小李现在只需要运行一次Python脚本,就可以自动从大量PDF年报中提取出主要业务信息,并将这些信息整理到Excel和文本文档中。这不仅大大节省了他的时间,还提高了数据的准确性和一致性。现在,小李可以更加专注于分析工作本身,为公司创造更大的价值。
总结与展望
通过本篇文章的介绍,我们可以看到Python在自动化办公领域的强大能力。利用Python编写自动化脚本,我们可以轻松解决许多繁琐的数据处理任务,提高工作效率。未来,随着人工智能和大数据技术的不断发展,我们相信Python将在自动化办公领域发挥更加重要的作用。让我们一起期待Python为我们带来的更多惊喜吧!
数海丹心
大数据和人工智能知识分享与应用
108篇原创内容
公众号