首先,打开window系统中的cmd命令行工具,或者powershell,安装腾讯云tencentcloud的Python库
pip install -i https://mirrors.tencent.com/pypi/simple/ --upgrade tencentcloud-sdk-python
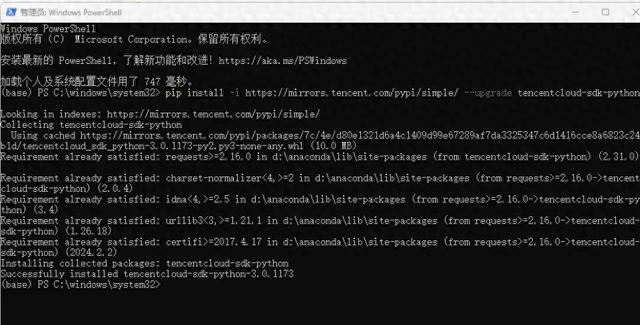
然后,开通腾讯云的对象存储COS服务,

把要转录成文本的mp3音频文件上传到腾讯云的存储桶:
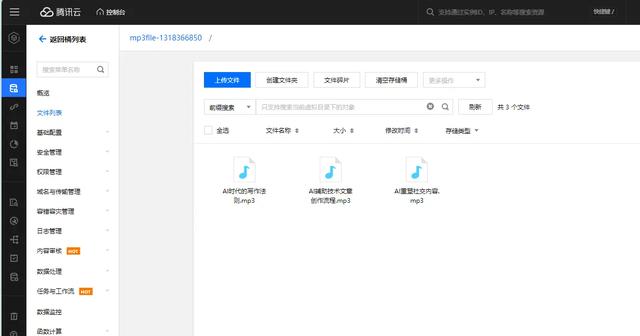
把这个存储桶的访问权限 设置为:公有读私有写

申请腾讯云语音识别资源包的免费额度(10小时),该免费额度将以预付费资源包的形式在每月1号自动发放,仅在当月有效 。然后新建API密钥:访问管理-API密钥管理—新建密钥,即可生成API/SDK调用所需的签名APPID、SecretId与SecretKey信息。。

最后,在AI大模型聊天应用deepseek中输入提示词:
你是一个Python编程专家,要写一个通过腾讯云的语音识别API进行批量AI语音识别的Python脚本,具体步骤如下:
腾讯云SecretId是XXX,SecretKey是XXX
音频文件URL列表如下:https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E6%97%B6%E4%BB%A3%E7%9A%84%E5%86%99%E4%BD%9C%E6%B3%95%E5%88%99.mp3, https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E8%BE%85%E5%8A%A9%E6%8A%80%E6%9C%AF%E6%96%87%E7%AB%A0%E5%88%9C%E6%B5%81%E7%A8%8B.mp3, https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E9%87%8D%E5%A1%91%E7%A4%BE%E4%BA%A4%E5%86%85%E5%AE%B9.mp3
对于每个音频文件,创建一个语音识别任务,然后定期检查任务状态,直到任务完成或失败。完成后,将识别结果保存到本地文件。识别结果保存到F:\\aivideo\\目录下,文件名为对应的mp3文件名,格式为txt。”
注意:
如果创建任务或查询状态时发生错误,应该打印错误信息;
每一步都要输出信息到屏幕上;
音频文件URL中的mp3文件名经过了URL编码,在命名txt文本时,要解码这段文本, 将其转换回原始的中文文本,然后用这个解码后的文件名来命名txt文档;

deepseek生成的Python源代码:
import os
import time
import json
import urllib.parse
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.asr.v20190614 import asr_client, models
# 腾讯云API的SecretId和SecretKey
SECRET_ID = "XXX"
SECRET_KEY = "XXX"
# 音频文件URL列表
AUDIO_URLS = [
"https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E6%97%B6%E4%BB%A3%E7%9A%84%E5%86%99%E4%BD%9C%E6%B3%95%E5%88%99.mp3",
"https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E8%BE%85%E5%8A%A9%E6%8A%80%E6%9C%AF%E6%96%87%E7%AB%A0%E5%88%9C%E6%B5%81%E7%A8%8B.mp3",
"https://mp3file-1318366850.cos.ap-guangzhou.myqcloud.com/AI%E9%87%8D%E5%A1%91%E7%A4%BE%E4%BA%A4%E5%86%85%E5%AE%B9.mp3"
]
# 保存结果的目录
OUTPUT_DIR = "F:\\aivideo\\"
def create_rec_task(client, url):
try:
req = models.CreateRecTaskRequest()
params = {
"EngineModelType": "16k_zh",
"ChannelNum": 1,
"ResTextFormat": 0,
"SourceType": 0,
"Url": url
}
req.from_json_string(json.dumps(params))
resp = client.CreateRecTask(req)
print(f"Task created for URL: {url}, Task ID: {resp.Data.TaskId}")
return resp.Data.TaskId
except TencentCloudSDKException as err:
print(f"Error creating task for URL: {url}, Error: {err}")
return None
def describe_task_status(client, task_id):
try:
req = models.DescribeTaskStatusRequest()
params = {
"TaskId": task_id
}
req.from_json_string(json.dumps(params))
resp = client.DescribeTaskStatus(req)
return resp.Data
except TencentCloudSDKException as err:
print(f"Error describing task status for Task ID: {task_id}, Error: {err}")
return None
def save_result_to_file(url, result):
file_name = urllib.parse.unquote(os.path.basename(url)).replace(".mp3", ".txt")
file_path = os.path.join(OUTPUT_DIR, file_name)
with open(file_path, "w", encoding="utf-8") as f:
f.write(result)
print(f"Result saved to {file_path}")
def main():
cred = credential.Credential(SECRET_ID, SECRET_KEY)
httpProfile = HttpProfile()
httpProfile.endpoint = "http://asr.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = asr_client.AsrClient(cred, "ap-guangzhou", clientProfile)
for url in AUDIO_URLS:
task_id = create_rec_task(client, url)
if task_id is None:
continue
while True:
time.sleep(5)
task_status = describe_task_status(client, task_id)
if task_status is None:
continue
if task_status.Status == 2: # 任务完成
print(f"Task ID: {task_id} completed.")
save_result_to_file(url, task_status.Result)
break
elif task_status.Status == 3: # 任务失败
print(f"Task ID: {task_id} failed.")
break
if __name__ == "__main__":
main()
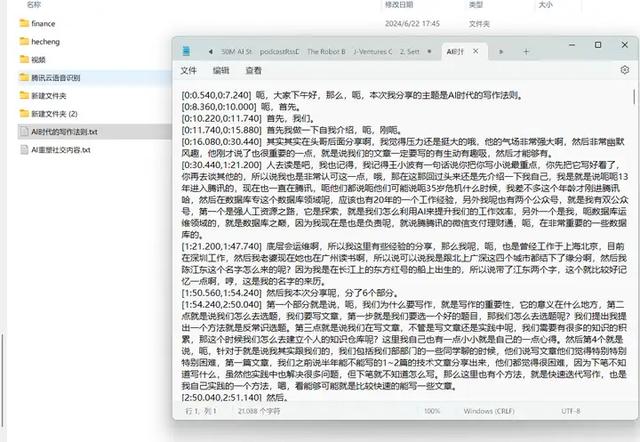
复制以上代码到vscode中,运行程序:

腾讯云语音识别速度很快,一两分钟就把3个几十分钟长度的音频转录完成了。识别的准确率也挺高:
识别完成后,可以查看语音识别资源包的调用情况,包括识别次数和识别小时数:

在语音识别资源包这里面可以查看还有多少免费额度:
