当前,数据中心正经历从单一资源存储向计算能力核心枢纽的深刻转型,内部承载的计算集群规模不断扩大。随着对高效互联网络需求的日益迫切,这实际上是对连接于各个计算节点间网络性能不断提升的直接响应。数据中心网络的整合已悄然成为提升整体计算能力的关键组成部分,这一过程生动体现了计算与网络深度融合的发展趋势。
为了适应高性能计算环境严苛的要求,智能无损以太网技术应时而生,其目标是构筑一个能够满足大规模、高密度计算集群间高速互连,并有效消除数据传输丢包问题的网络架构体系。这种技术致力于在确保数据零丢失的前提下,大幅提升数据传输速度和效率,从而充分赋能高性能计算领域的发展与创新。
高性能计算工作对网络基础设施要求不断提升随着5G、大数据、物联网(IoT)及人工智能(AI)等创新技术在社会各领域的深入应用,未来二三十年内智能化与数字化将成为社会发展的重要趋势。数据中心计算能力已成为推动这一进程的关键动力,并且其关注焦点正逐渐从资源规模向计算能力规模转移。业界普遍接受了以计算力为核心的数据中心模式,在此架构下,网络基础设施在实现数据中心内部高性能计算中扮演着至关重要的角色。优化网络性能成为提升数据中心计算效能的关键因素。
为应对计算能力需求的持续增长,行业在多个维度上不断寻求突破。尽管单核芯片技术在3nm节点遭遇瓶颈,通过多核堆叠的方式可以在一定程度上提升计算能力,但伴随核心数量增加,每单位计算能力的能耗也显著上升。与此同时,计算单元技术的发展已接近物理极限,摩尔定律预测的每18个月性能翻倍的趋势即将走到尽头。面对急剧攀升的计算需求,特别是在计算集群由P级迈向E级的大规模扩展过程中,高性能计算(HPC)的重要性愈发凸显。
高性能计算致力于聚合大规模计算能力,解决超出常规工作站处理能力的复杂科学计算问题,如模拟仿真、模型构建和图像渲染等。当计算需求从P级跃升至E级时,计算集群规模不断扩大,对互联网络的性能要求也随之升高,这进一步彰显了计算与网络深度融合的发展潮流。随着计算需求从P级到E级的跨越式发展,计算集群规模的增长对互联网络性能提出了更高标准,使得计算与网络之间形成了更为紧密的共生关系。
在高性能计算(HPC)的不同应用场景中,网络性能需求呈现多元化特点:
松耦合计算场景:在金融风险评估、遥感等节点间相互依赖性较弱的领域,网络性能需求相对平缓。这类任务对数据传输的即时性要求并不苛刻,但仍需稳定可靠的网络支持以确保计算效率。紧耦合计算场景:针对电磁模拟、流体动力学等高度依赖节点间同步协作和快速信息交换的任务,网络延迟成为关键考量因素。此类应用需要极低的网络延迟,并配备专门设计的低延迟网络设施,以确保节点间的高效协同运算。数据密集型计算场景:在天气预报、基因测序等处理大量原始数据并生成巨量中间结果的应用情境下,高吞吐量网络至关重要。不仅要求网络具备高速传输能力,同时对整体网络延迟也有明确且严格的标准。综上所述,在高性能计算环境中,为了应对各类复杂任务的需求,网络系统必须兼具高吞吐量与低延迟的特性。为达成这一目标,业界普遍采用远程直接内存访问(RDMA)技术来取代传统的TCP协议,以有效降低通信延迟,并最大限度地减少服务器CPU资源占用。尽管RDMA技术优势明显,但其对网络丢包现象的高度敏感也突显了构建无损网络环境的重要性。
高性能计算网络的演进历程传统数据中心网络自始至终依赖于基于以太网技术构建的多跳对称架构,并在数据传输过程中倚重TCP/IP协议栈。尽管历经三十多年的发展与改进,但受限于其内在的技术局限性,传统的TCP/IP网络在满足高性能计算(HPC)日益增长的需求时显得捉襟见肘。随着RDMA(远程直接内存访问)技术逐渐崭露头角并逐步取代TCP/IP成为高性能计算网络的标准配置,一场意义深远的变革正在上演。
此外,在RDMA技术的实际应用中,其采用的网络层协议也经历了从基于昂贵而高效的InfiniBand(IB)协议的无损网络,向成本更为亲民且同样具备智能无损特性的以太网技术过渡。这一转变标志着高性能计算网络技术在追求更高性能、更低延迟以及更优成本效益方面的持续探索与突破。FS的专业技术团队将深入剖析这些技术变迁背后的驱动力及其带来的显著进步。
从TCP到RDMA在传统数据中心环境中,构建多跳对称网络架构的标准配置长期依赖于以太网技术和TCP/IP协议栈。然而,随着高性能计算需求的不断攀升,TCP/IP网络由于以下两个核心瓶颈而显得力不从心:
延迟问题:TCP/IP协议栈处理数据包时,在内核层面涉及多次上下文切换,由此引入了数微秒级别的延迟。这种通常在5-10微秒范围内的延迟对于要求微秒级响应的系统而言,成为了显著制约因素,影响诸如人工智能数据处理和分布式固态存储等任务的高效执行。CPU利用率问题:除了延迟瓶颈外,TCP/IP网络还存在CPU资源消耗过大的问题。主机CPU必须深度参与协议栈内部的数据复制过程,当网络规模和带宽持续增长时,这会导致CPU调度压力增大,进而使得CPU负载长时间保持高位。业界普遍认为,每传输一个比特的数据就需要占用大约1Hz的CPU频率资源,因此在超过25Gbps(满载)的高速网络环境下,大量的CPU资源将被用于网络通信而非实际计算工作。为应对上述挑战,服务器端引入了RDMA(远程直接内存访问)技术。RDMA是一种革命性的内存访问机制,它允许数据绕过操作系统直接在计算机内存之间进行快速传输,从而避免了耗时的处理器中间环节操作。这一创新设计有效地解决了延迟、CPU利用率的问题,实现了高带宽、低延迟及低资源占用率,有力推动了高性能计算环境的发展与优化。
从InfiniBand到RoCE如下图所示,RDMA技术所采用的内核旁路机制使得应用程序可以直接与网络适配器进行数据读写操作,从而成功规避了TCP/IP协议栈带来的延迟限制。通过这一优化,协议栈延迟几乎可以降低至1微秒以内。此外,RDMA的零拷贝特性使得接收端能够直接访问发送端内存中的数据,这不仅极大降低了CPU处理负担,还显著提升了整体CPU效率。
对比之下,在40Gbps速率下,传统的TCP/IP通信可能会将所有可用的CPU资源消耗殆尽;而采用同样速度下的RDMA方案时,CPU利用率则可以从100%大幅下降至5%,同时,网络传输延迟也由原来的毫秒级别骤减至不足10微秒,实现了性能的飞跃提升。随着以太网技术的发展,RDMA over Converged Ethernet(RoCE)应运而生,它将RDMA的优势引入到了广泛部署的以太网环境中,进一步推动高性能计算领域在网络性能、效率和兼容性方面的持续进步。
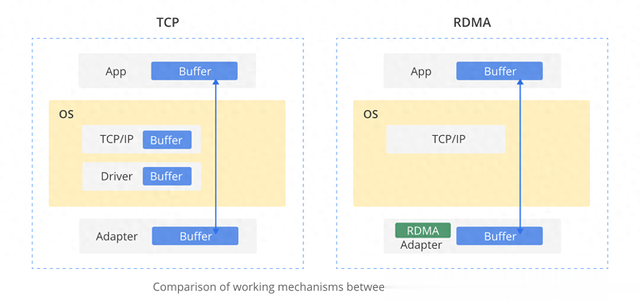
添加图片注释,不超过 140 字(可选)
目前,高性能计算领域中RDMA网络层协议主要有三种选择方案:InfiniBand、iWARP(互联网广域RDMA协议)以及RoCE(以太网融合上的RDMA)。
InfiniBand:作为一种专为RDMA设计的协议,在硬件层面确保了无损传输特性,从而提供了卓越的带宽和低延迟性能。然而,由于其封闭的架构设计,可能会导致互操作性受限以及潜在的供应商锁定问题。iWARP:该协议允许在TCP/IP基础之上实现RDMA功能,虽然需要使用特制的网络适配器,但由于受到TCP协议本身特性的影响,相较于InfiniBand而言,在性能上存在一定的折损。RoCE:该技术则将RDMA的优势引入到了广泛应用的以太网环境中,使得通过以太网进行远程内存访问成为可能。RoCE能够在标准的以太网交换机上运行,仅需配备专用的RDMA网络适配器即可。RoCE协议分为两个版本,即RoCEv1和RoCEv2。其中,RoCEv2作为增强型网络层协议,不仅支持路由功能,还允许不同广播域中的主机相互访问。尽管RoCE具有诸多优势,但因其对数据包丢失高度敏感,因此必须依赖于无损以太网技术来保证最佳性能。高性能计算网络领域的这一发展进程,充分展示了业界对于不断提升性能、效率和互操作性的持续探索与努力。
总结随着数据中心与高性能计算需求的日益增长,RDMA技术在实现高效、低延迟数据传输方面扮演着核心角色。对于用户和供应商来说,在InfiniBand技术和支持RDMA的以太网技术之间做出选择时,需要根据具体需求和实际应用场景进行审慎评估。超级计算领域中,InfiniBand技术凭借其广泛的应用基础及成熟的生态系统占据优势;而在以太网环境内,RoCE与iWARP则更适合应用于高性能计算和存储场景。
飞速(FS)作为一家专业服务于网络、数据中心以及电信行业的通信和高速网络系统解决方案提供商,充分利用NVIDIA® InfiniBand交换机、100G/200G/400G/800G光模块及NVIDIA® InfiniBand 光纤网卡等产品,为客户提供包括基于InfiniBand和无损以太网(RoCE)在内的全面解决方案。这些方案能够满足各类应用需求,助力用户显著提升业务运行效率和整体性能表现。欲获取更多详尽信息,请访问官方cn.fs.com网站。