
引用
arXiv:2310.06530 [cs.SE]
https://doi.org/10.48550/arXiv.2310.06530
论文:https://arxiv.org/pdf/2310.06530.pdf
摘要
C反编译器将一个可执行文件(由C编译器输出的文件)转换为源代码。恢复的C源代码一旦重新编译,预期将产生一个与原始可执行文件具有相同功能的可执行文件。经过二十多年的发展,C反编译器已被广泛应用于生产中,用于支持反向工程应用,包括遗留软件迁移、安全强化、软件理解,以及作为启动对抗性软件开发的第一步。尽管C反编译器的发展蓬勃,但反编译器的输出主要用于人工消费,不适合自动重新编译。通常需要大量的手动工作来修复反编译器的输出,以便能够正确地重新编译和执行。
本文的动机在于最近大型语言模型(LLMs)在理解自然语言的密集语料库方面取得成功。为了减轻修复反编译器输出时繁琐、昂贵和经常出错的手动工作,我们探讨了使用LLMs增强反编译器输出的可行性,从而提供可重新编译的反编译。需要注意的是,与以往专注于提高可读性(例如恢复类型/变量名)的工作不同,我们专注于增强反编译器输出的可重编译性,即生成可以重新编译为具有与原始可执行文件相同功能的可执行文件的代码。
我们进行了一项试点研究,以描述重新编译商业C反编译器IDA-Pro的输出所面临的障碍。然后,我们提出了一种两步骤的混合方法,利用LLMs增强反编译器输出。具体来讲,我们首先通过一个静态的、迭代的增强步骤,使用LLMs来修复反编译器输出中的语法错误,使其在语法上“可重新编译”。然后,我们通过一个动态的,修复内存错误的步骤,使用LLMs来修复仅在运行时才能暴露的内存错误。最终增强的反编译器输出可以顺利地被C编译器恢复,最终产生一个重新编译的可执行文件,其功能与原始可执行文件相同。
1 引言
C反编译器通过分析和转换低级可执行文件来恢复C源代码。鉴于C在软件行业、恶意软件作者以及其不安全的特性中的广泛应用,C反编译器已被广泛用于软件逆向工程和安全分析任务。例如,C反编译器经常用于恢复遗留软件的源代码,以进行安全强化等目的。到目前为止,市场上已经有许多成熟的C反编译器可供选择,包括商业工具如IDA-Pro,其许可证费用数千美元,以及由开源社区或国家安全局(NSA)积极维护的免费工具(例如Ghidra)。
尽管C反编译器蓬勃发展,但广泛认可的是反编译器的输出主要用于人工消费,不适合自动重新编译。软件编译本质上是一个有损过程,许多高级信息(如变量名、类型信息和数据结构)在编译后在二进制文件中不存在。因此,反编译器通常以务实和保守的方式设计,其中生成的代码的可读性优先于其“可重新编译性”,即生成的代码可以重新编译为与原始可执行文件具有相同功能的可执行文件。
尽管反编译器的输出不适合自动重新编译,但最近的研究强调了自动重新编译反编译器输出的重要性。例如,各种软件跨架构迁移技术的最终目标是将反编译器输出重新编译为可以在不同架构上运行的二进制文件。此外,为了重用遗留软件,通常需要将反编译器输出重新编译为可以在不同操作系统上运行的二进制文件。在各种安全工具和加固任务中,通常需要用安全检查对反编译器输出进行仪表化,并将其重新编译为具有与原始二进制文件相同功能的二进制文件。然而,“可重新编译”的反编译器发展缓慢,有限的工作重点集中在基于规则的方法或人工工作上。
为了克服障碍并提供高效的解决方案,我们提出了一个名为DecGPT的两步骤混合框架,使用LLMs增强反编译器输出。首先,我们使用LLMs静态地修复反编译器输出中的语法错误。这形成了一个迭代过程,我们将增强的反编译器输出提供给C编译器,然后使用编译器的错误消息来指导LLMs在进一步迭代中重新增强反编译器输出。其次,我们使用一个动态的、使用LLMs修复内存错误的步骤。在准备这一步时,我们将增强的反编译器输出编译为启用地址检测器(ASAN)的可执行文件。然后,我们运行一组测试用例的可执行文件,并使用ASAN的错误消息来指导LLMs修复内存错误。我们的经验表明,ASAN可以在运行时暴露大量微妙的缺陷,因此动态步骤有效地暴露了静态步骤无法暴露的微妙缺陷。最终增强的反编译器输出将是一段C代码,可以顺利地被C编译器恢复,最终产生一个重新编译的可执行文件,其功能与原始可执行文件相同。
我们在Code Contest数据集的一个子集上对DecGPT进行评估,该数据集包括300个测试用例,并展示了DecGPT可以在适度努力的情况下显著提高重新编译成功率(从基线设置的45%提高到75%)。进一步的消融研究表明,静态和动态步骤都是实现高重新编译成功率所必需的。结果表明生成式人工智能在解决逆向工程中固有的基本挑战方面具有很大潜力。我们还讨论了几个有前途的未来研究方向,可以进一步提高反编译的质量。本文主要贡献如下:
在概念上,本研究专注于“可重新编译的反编译”这一重要研究方向,以满足在安全和软件重工程任务中重新执行反编译器输出的需求增加。因此,我们首次探索了使用LLMs替代以往基于规则或人工工作的方法来增强反编译器输出的可行性。在技术上,我们设计了一个两步骤的混合方法,有意发挥LLMs在增强反编译器输出中的全部潜力。我们的方法利用LLMs在静态环节修复反编译器输出中的语法错误,同时在运行时动态修复仅在运行时才能发现的内存错误。在实证上,我们在流行的C测试用例上的评估显示,由LLMs自动增强的反编译的C代码可以顺利地被C编译器恢复,最终产生一个重新编译的可执行文件,其功能与原始可执行文件相同。我们还讨论了进一步改进反编译质量的有前途的方向。2 方法
在本节中,我们介绍我们的方法DecGPT,一个两步骤的混合流程,使用LLMs增强反编译器输出。

图1:DecGPT的工作流程
图1展示了DecGPT的工作流程。我们首先启动静态的、迭代的增强步骤来修复反编译器输出,使其可以被标准C编译器编译。然后,我们启动一个动态的、修复在运行时检测到的内存错误的步骤。最终增强的反编译器输出可以顺利被C编译器恢复,生成一个语义正确的可执行文件。
2.1 静态增强
静态增强旨在修复反编译器输出中的语法错误和推理错误,并使输出可被标准C/C++编译器编译。给定一段反编译器输出o,我们首先使用标准编译器C(在我们的实现中,我们使用标准的GCC编译器)编译该输出。如果编译器C无法编译输出o,我们将启动以下静态增强步骤。
① 初始提示。静态增强步骤是一个迭代过程。对于默认的反编译器输出,我们应用预处理规则①到③。这些规则会从伪代码中删除不必要的标记,并有助于防止由此产生的幻觉。我们指示模型减少在反编译器输出中发现的冗余变量赋值,从而减少输出长度,同时减少如果需要源代码片段进行进一步修复时产生幻觉的机会。通过以上步骤,我们为LLM准备了一个初始提示以修复输入。
② 后处理。尽管我们在提示中指定了期望的输出格式,但我们的测试表明,ChatGPT有时会生成部分格式错误的输出,包括代码解释。直接使用这些输出进行重新编译通常会导致编译错误。为解决这个问题,我们创建一组规则清理输出o。处理后,我们将使用标准C/C++编译器重新编译输出o。
③ 处理错误消息。如果输出o在编译时失败,我们在编译过程中收集编译器错误消息E。然后,我们首先使用脚本预处理E,以去除无关信息,例如行号和文件名。然后,我们将经过预处理的错误消息E和包含错误的特定行,输入到LLM中生成一个新的标记序列T。
④ 修复反编译输出o。在这一步中,我们将反编译器输出o令牌化为一个标记序列T。然后,我们准备一个提示P输入到LLM中。提示P指示LLM修复标记序列T并生成新的标记序列T'。
⑤ 迭代增强。修复后的标记序列T'然后输入到编译器C中重新编译修复后的输出T'。如果编译器C再次无法编译T',我们首先迭代T'中的每个函数,并检查是否某些函数体被剥离;如果是,我们撤销更改。然后,我们从①开始重复上述过程,直到编译器C成功编译T',或者迭代次数超过预定义的阈值N。在我们当前的实现中,根据我们的初步实验证明,我们将N设置为15。
以上静态增强步骤旨在修复反编译器输出中的语法错误和推理错误,并使输出可被标准C/C++编译器编译。然而,输出可能仍然包含各种内存错误和功能错误。换句话说,即使这个静态修复阶段的输出是“可重新编译的”,其生成的可执行文件仍可能崩溃或产生明显不正确的结果。为解决这个问题,我们启动以下动态修复步骤。
2.2 动态修复
我们使用一组测试用例T对编译的可执行文件E进行性能分析。此外,我们配置C编译器在编译阶段将地址检查器注入到可执行文件E中。这样,每当可执行文件E包含微妙的内存错误时,地址检查器将在运行时性能分析阶段可靠地检测和报告这些错误。根据内存检测结果,我们接着启动以下动态修复步骤。
⑥ 收集内存错误信息。当可执行文件E中的一个注入的地址检查器在程序输入t上发出警报时,我们首先收集内存错误信息I。内存错误信息I包括地址、错误指令、上下文中的寄存器值以及堆栈跟踪。这些信息由地址检查器良好生成,并可以通过脚本轻松解析进行分析。
⑤ 修复缺陷。然后,我们准备一个提示P输入到LLM中。提示P指示LLM修复源自测试用例t中的内存错误信息I。LLM然后生成一个新的标记序列T'。
⑤ 测试功能等效性。如果测试用例t没有引发警报,我们将验证可执行文件E的输出与期望的输出是否一致。如果输出正确,我们将继续下一个测试用例。如果输出不正确,我们准备一个提示P并指示LLM尽最大努力修复功能缺陷;再次强调,我们认为直接修复功能缺陷是一个非常具有挑战性的任务,我们的主要重点是上述内存错误修复。总的来说,我们然后从第⑥步开始重复上述过程,直到可执行文件E通过所有测试用例或在T中失败任何测试用例,并指示LLM修复已识别的缺陷。
3 实验
3.1 研究问题
我们的评估旨在回答以下研究问题:
RQ1:DecGPT在解决基于规则的重新编译挑战方面效果如何?
RQ2:DecGPT在缓解基于LLM的重新编译挑战方面效果如何?
RQ3:迭代设计对DecGPT性能的贡献有多大?
3.2 RQ1:与基于规则的重新编译器的比较
为评估DecGPT在处理基于规则的重新编译挑战方面的有效性,我们将其与我们之前使用的设置进行了比较;为了便于展示,我们将之前使用的设置表示为DecRule。为了与DecGPT进行公平比较,我们将原始源代码中提取的头部和命名空间添加到反编译结果中。需要注意的是,在DecGPT的情况下,这些信息预计会被LLM推断出来。
如表1所示,DecRule可以成功地重新编译测试数据集中的8%的二进制文件,而DecGPT可以重新编译其中的75%。这种比较突出了DecGPT在解决与基于规则的重新编译相关挑战方面的有效性。为了了解DecGPT能够修复的错误类型,我们使用使用DecRule时生成的编译错误作为参考,并手动检查LLM和DecGPT之间的对话链。我们的分析显示,大约98%的规范错误在两轮对话中被DecGPT修复,无论测试用例是否可以重新编译。我们认为这些发现是合理的。为了通用地修复规范错误,通常会使用类似符号执行的重量级二进制分析来推断函数原型。相反,LLMs可以通过将语法错误的代码块替换为正确的代码块来相对容易地修复这些错误。
借助我们的设计,DecGPT可以修复62.5%的推断错误和所有已识别的反编译器模板错误。通过利用反编译的伪代码作为输入,并使用编译错误作为反馈,DecGPT迭代地替换反编译器输出中的错误段。在一个成功重新编译的案例中,我们发现最初的反编译输出包含一个类型推断错误,其中一个变量的整数类型被错误地推断为无符号整数类型。随后,这个变量和另一个正确推断的变量被用来调用max函数。虽然这导致编译错误,但我们发现通过两轮对话,DecGPT可以成功地通过精确地将无符号整数类型替换为整数类型来解决这个问题。LLM也发生类似情况,用于修复反编译器模板错误,这通常导致编译时的类型转换失败。然而,DecGPT可能无法修复所有推断错误。剩下的37.5%样本中,我们发现70.2%来自标准模板库(STL)函数。STL是C++编程范式的重要组成部分,提供可重用的容器和算法。值得注意的是,STL函数的识别通常被认为是困难的,因为相同STL函数的反编译代码在不同类型下可能差异很大。在我们的研究中,我们观察到STL函数调用的存在往往会将反编译输出的上下文长度从2.8倍增加到16.1倍。这对LLMs构成挑战,因为LLMs的性能高度依赖上下文长度。然而,我们也将这视为反编译的挑战,因为反编译的伪代码可能无法准确表示使用的STL函数,从而阻碍LLMs修复语法错误。
剩下的错误都来自不同上下文中错误推断的缓冲区大小。虽然缓冲区大小可以通过ASAN错误消息间接修复,但缺乏准确的缓冲区大小信息仍然对LLMs成功重新编译二进制文件构成挑战。我们认为这对LLMs和反编译器都是一个挑战,因为LLMs的性能高度依赖其输入的质量(即,反编译器输出)。

表1:三个不同工具的编译成功率
3.3 RQ2:与基于大型语言模型的重新编译器的比较
我们现在评估DecGPT,以了解其在解决基于LLM的重新编译挑战方面的有效性(称为llm-baseline)。与llm-baseline相比,DecGPT在几个方面取得了进展。首先,DecGPT扩展了系统提示以增强重新编译过程的整体稳定性。其次,在LLM返回的源代码中添加了结构级别的健全性检查,并确保下一次迭代中输入模型包含了重新编译二进制文件所需的所有必要信息。第三,我们使用启用ASAN的方式编译二进制文件。这使得当二进制文件崩溃时,我们能够提取导致内存损坏的语句行。然后,我们将这些信息作为LLM生成修复问题的输出版本的一部分。表1和表2显示了这两种设置的成功率和每个间隔的成功案例数量。总体而言,DecGPT在重新编译相同一组二进制文件的成功率方面比llm-baseline高出30%;它被认为更能处理具有长上下文的反编译输出。我们对结果的解释如下。
扩展系统提示的有效性。为了评估DecGPT中扩展系统提示的效果,我们参考表1中C = 1的结果。在这种情况下,成功率是在二进制文件成功重新编译而无需额外修复查询的情况下进行测量的。与llm-baseline的结果相比,容易观察到当系统提示扩展时,成功率从32%增加到37%。换句话说,通过扩展系统提示,DecGPT有效地对LLM施加了更多约束,并帮助LLM集中于修复反编译输出并更接近期望的输出。这些有助于改进性能而无需额外迭代。
静态增强的有效性。DecGPT在重新编译长度较长的输出时优于llm-baseline。如表2所示,对于上下文长度在1280至1640和1640至2048之间的情况,DecGPT成功重新编译的反编译器输出比llm-baseline分别多了4.3倍和4.5倍。这表明DecGPT可以有效地缓解基于LLM的重新编译挑战,适用于更长的上下文长度。
这种明显的性能差异归因于扩展系统提示和静态增强的协同效应。在检查两个上述上下文长度区间内的成功案例时,我们发现DecGPT能够检测和恢复共计194个实例,LLM在修复过程中鲁莽地剥离函数体。DecGPT通过避免这些不必要的修改有效地保持了反编译器输出的完整性,并确保必要的上下文能够传递到下一次修复迭代中。因此,DecGPT在具有长上下文输入的重新编译中表现出比llm-baseline更好的性能。
动态增强的有效性。动态增强的设计旨在解决单独通过静态增强无法解决的功能不正确问题。为了评估DecGPT的动态增强提供的修复成功率,我们手动查看了50个DecGPT成功修复的运行时错误的案例,并将这些修复分类为三类。两个主要类别是输出格式错误和轻微算法错误,分别占样本案例的48%和42%。输出格式错误通常涉及与输出的结构或格式相关的问题,比如在每个输出后缺少换行符。至于轻微算法错误,通常包括小错误,比如逆向的加号/减号符号或逆向的程序逻辑。当提供正确的输出作为用户提示的一部分时,LLM通常可以修复这些问题。剩下的10%修复案例属于由于反编译器输出中的推断错误而导致的内存损坏问题。
动态增强的局限性。动态增强的一个重要部分是使用ASAN检测内存损坏问题。在运行时触发的55个ASAN实例中,DecGPT能够修复其中的40%。我们认为这些结果是合理且普遍鼓舞人心的,显示了将ASAN(其输出是严重内存错误的结构良好的文档)与LLM结合起来增强反编译输出的潜力。
我们进一步通过手动检查LLM和DecGPT之间的中间对话来调查无法修复的ASAN错误的原因。我们将无法修复的ASAN错误的原因分为两种类型。无法修复的ASAN错误的主要原因是在LLM试图修复类型转换错误时使用类型转换运算符(如"static_cast"和"reinterpret_cast")。这导致了81.8%的无法修复的ASAN错误。尽管尝试在系统提示或用户提示中明确禁止使用这些类型转换运算符,但LLM仍然继续使用它们作为修复策略。这种行为可能归因于第3.3.2节讨论的快捷学习行为。然而,这种行为的根本原因和适当的缓解措施留作未来工作,因为它们超出了当前论文的范围。剩下的18.2%无法修复的ASAN错误是由于幻觉错误引起的,比如LLM推断的错误缓冲区大小。
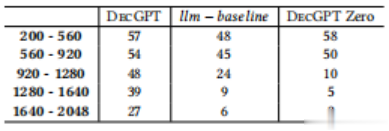
表2:不同上下文长度设置下的成功用例数目
3.4 RQ3:消融实验
为了了解迭代两阶段设计对DecGPT性能的贡献,我们在没有静态增强和动态增强的情况下运行DecGPT,我们将这种设置称为DecGPT Zero。与DecGPT类似,我们使用这种设置查询LLM 15次,并且如果LLM返回的任何输出通过所有测试用例(使用与DecGPT相同的标准)则认为重新编译成功。结果如表2所示。总体而言,DecGPT明显优于DecGPT Zero,特别是在处理具有长上下文的反编译输出时。对于上下文长度在200到560和560到920之间的情况,我们观察到DecGPT和DecGPT Zero之间有可比性的性能。这一结果是合理的,因为在这两个区间内,DecGPT修复反编译器输出所需的平均迭代次数分别为1.24和2.13。在这么少的迭代次数下,DecGPT和DecGPT Zero的性能相似。
然而,在剩下的区间中,DecGPT Zero显示出比迭代设计明显更低的成功率。这是合理的:随着上下文长度的增加,反编译器输出中包含的函数越多,这意味着反编译器输出中可能存在更多的语法错误。LLMs在处理长上下文时面临的另一个技术障碍是性能下降和信息遗忘问题。通过迭代设计,DecGPT可以逐步修复错误,为LLMs提供足够的上下文来解决反编译器输出中存在的现有语法错误或LLMs在先前迭代中引入的错误。相比之下,DecGPT Zero只有一次机会来修复错误,因此,DecGPT Zero更有可能遇到上述障碍。这些结果表明,迭代设计是DecGPT性能的关键因素。
转述:邹英龙